

Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
How strands work and why you should use them
In this post, I dissect how strands work (e.g: Boost Asio strands), why you should use them, and one way to implement it.
11 Min Read

Introduction
This was originally posted on my blog at http://www.crazygaze.com/blog/2016/03/17/how-strands-work-and-why-you-should-use-them
If you ever used Boost Asio, certainly you used or at least looked at strands.
The main benefit of using strands is to simplify your code, since handlers that go through a strand don’t need explicit synchronization. A strand guarantees that no two handlers execute concurrently.
If you use just one IO thread (or in Boost terms, just one thread calling io_service::run), then you don’t need synchronization anyway. That is already an implicit strand.
But the moment you want to ramp up and have more IO threads, you need to either deal with explicit synchronization for your handlers, or use strands.
Explicitly synchronizing your handlers is certainly possible, but you will be unnecessarily introducing complexity to your code which will certainly lead to bugs. One other effect of explicit handler synchronization is that unless you think really hard, you’ll very likely introduce unnecessary blocking.
Strands work by introducing another layer between your application code and the handler execution. Instead of having the worker threads directly execute your handlers, those handlers are queued in a strand. The strand then has control over when executing the handlers so that all guarantees can be met.
One way you can think about is like this:
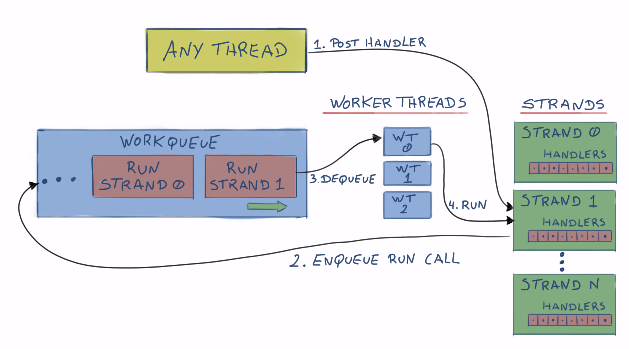
Possible scenario
To visually demonstrate what happens with the IO threads and handlers, I’ve used Remotery.
The code used emulates 4 worker threads, and 8 connections. Handlers (aka work items) with a random workload of [5ms,15ms] for a random connection are placed in the worker queue. In practice, you would not have this threads/connections ratio or handler workload, but it makes it easier to demonstrate the problem. Also, I’m not using Boost Asio at all. It’s a custom strand implementation to explore the topic.
So, a view into the worker threads:

Conn N are our connection objects (or any object doing work in our worker threads for that matter). Each has a distinct colour. All good on the surface as you can see. Now lets look at what each Connobject is actually doing with its time slice.

What is happening is the worker queue and worker threads are oblivious to what its handlers do (as expected), so the worker threads will happily dequeue work as it comes. One thread tries to execute work for a given Conn object which is already being used in another worker thread, so it has to block.
In this scenario, ~19% of total time is wasted with blocking or other overhead. In other words, only~81% of the worker thread’s time is spent doing actual work:

NOTE: The overhead was measured by subtracting actual work time from the total worker thread’s time. So it accounts for explicit synchronization in the handlers and any work/synchronization done internally by the worker queue/threads.
Lets see how it looks like if we use strands to serialize work for our Conn objects:


Very little time is wasted with internal work or synchronization.
Cache locality
Another possible small benefit with this scenario is better CPU cache utilization. Worker threads will tend to execute a few handlers for a given Conn object before grabbing another Conn object.
Zoomed out, without strands

Zoomed out, with strands

I suspect in practice you will not end up with handlers biased like that, but since it’s a freebie that required no extra work, it’s welcome.
Strand implementation
As a exercise, I coded my own strand implementation. Probably not production ready, but I’d say it’s good enough to experiment with.
First, lets think about what a strand should and should not guarantee, and what that means for the implementation:
No handlers can execute concurrently.
This requires us to detect if any (and what) worker thread is currently running the strand. If the strand is in this state, we say it is Running .
To avoid blocking, this means the strand needs to have a handler queue, so it can enqueue handlers for later execution if it is running in another thread.
Handlers are only executed from worker threads (In Boost Asio’s terms, a thread runningio_service::run)
This also implies the use of the strand’s handler queue, since adding handlers to the strand from a thread which is not a worker thread will require the handler to be enqueued.
Handler execution order is not guaranteed
Since we want to be able to add handlers to the strand from several threads, we cannot guarantee the handler execution order.
The bulk of the implementation is centered around 3 methods we need for the strand interface (similar to Boost Asio’s strands )
post
Adds a handler to be executed at a later time. It never executes the handler as a result of the call.
dispatch
Executes the handler right-away if all the guarantees are met, or calls post if not.
run
Executes any pending handlers. This is not part of the public interface.
Putting aside synchronization for now, we can draft the behavior of those 3 methods. Overall, it’s quite straightforward.



For the actual source code, we need two helper classes I introduced earlier:
Allows placing markers in the current callstack, to detect if we are executing within a given function/method in the current thread.
Simple multiple producer/multiple consumer work queue. The consumers block waiting for work.
Useful as-is, but introduced mostly to simplify the sample code, since in practice you will probably be using strands with something more complex.
There is also Monitor<T> , which allows you to enforce synchronization when accessing a given object of type T. You can learn more about it at https://channel9.msdn.com/Shows/Going+Deep/C-and-Beyond-2012-Herb-Sutter-Concurrency-and-Parallelism at around minute 39 , but here it is the implementation I’ll be using:
template <class T> class Monitor { private: mutable T m_t; mutable std::mutex m_mtx; public: using Type = T; Monitor() {} Monitor(T t_) : m_t(std::move(t_)) {} template <typename F> auto operator()(F f) const -> decltype(f(m_t)) { std::lock_guard<std::mutex> hold{m_mtx}; return f(m_t); } };
The strand implementation is pretty much what you see in the diagrams above, but with the required internal synchronization. Heavily documented to explain what’s going on.
#pragma once #include "Callstack.h" #include "Monitor.h" #include <assert.h> #include <queue> #include <functional> // // A strand serializes handler execution. // It guarantees the following: // - No handlers executes concurrently // - Handlers are only executed from the specified Processor // - Handler execution order is not guaranteed // // Specified Processor must implement the following interface: // // template <typename F> void Processor::push(F w); // Add a new work item to the processor. F is a callable convertible // to std::function<void()> // // bool Processor::canDispatch(); // Should return true if we are in the Processor's dispatching function in // the current thread. // template <typename Processor> class Strand { public: Strand(Processor& proc) : m_proc(proc) {} Strand(const Strand&) = delete; Strand& operator=(const Strand&) = delete; // Executes the handler immediately if all the strand guarantees are met, // or posts the handler for later execution if the guarantees are not met // from inside this call template <typename F> void dispatch(F handler) { // If we are not currently in the processor dispatching function (in // this thread), then we cannot possibly execute the handler here, so // enqueue it and bail out if (!m_proc.canDispatch()) { post(std::move(handler)); return; } // NOTE: At this point we know we are in a worker thread (because of the // check above) // If we are running the strand in this thread, then we can execute the // handler immediately without any other checks, since by design no // other threads can be running the strand if (runningInThisThread()) { handler(); return; } // At this point we know we are in a worker thread, but not running the // strand in this thread. // The strand can still be running in another worker thread, so we need // to atomically enqueue the handler for the other thread to execute OR // mark the strand as running in this thread auto trigger = m_data([&](Data& data) { if (data.running) { data.q.push(std::move(handler)); return false; } else { data.running = true; return true; } }); if (trigger) { // Add a marker to the callstack, so the handler knows the strand is // running in the current thread Callstack<Strand>::Context ctx(this); handler(); // Run any remaining handlers. // At this point we own the strand (It's marked as running in // this thread), and we don't release it until the queue is empty. // This means any other threads adding handlers to the strand will // enqueue them, and they will be executed here. run(); } } // Post an handler for execution and returns immediately. // The handler is never executed as part of this call. template <typename F> void post(F handler) { // We atomically enqueue the handler AND check if we need to start the // running process. bool trigger = m_data([&](Data& data) { data.q.push(std::move(handler)); if (data.running) { return false; } else { data.running = true; return true; } }); // The strand was not running, so trigger a run if (trigger) { m_proc.push([this] { run(); }); } } // Checks if we are currently running the strand in this thread bool runningInThisThread() { return Callstack<Strand>::contains(this) != nullptr; } private: // Processes any enqueued handlers. // This assumes the strand is marked as running. // When there are no more handlers, it marks the strand as not running. void run() { Callstack<Strand>::Context ctx(this); while (true) { std::function<void()> handler; m_data([&](Data& data) { assert(data.running); if (data.q.size()) { handler = std::move(data.q.front()); data.q.pop(); } else { data.running = false; } }); if (handler) handler(); else return; } } struct Data { bool running = false; std::queue<std::function<void()>> q; }; Monitor<Data> m_data; Processor& m_proc; };
Note that Strand is templated. You need to specify a suitable Processor type. This was mostly to allow me to share the code as-is, without more dependencies.
Another peculiar thing to note is that the strand doesn’t use the Processor to execute handlers, as mentioned in the beginning. It uses it to trigger execution of its own run method.
Usage example
A simple useless sample demonstrating how it can be used.
#include "Strand.h" #include "WorkQueue.h" #include <random> #include <stdlib.h> #include <string> #include <atomic> int randInRange(int min, int max) { std::random_device rd; std::mt19937 eng(rd()); std::uniform_int_distribution<> distr(min, max); return distr(eng); } struct Obj { explicit Obj(int n, WorkQueue& wp) : strand(wp) { name = "Obj " + std::to_string(n); } void doSomething(int val) { printf("%s : doing %dn", name.c_str(), val); } std::string name; Strand<WorkQueue> strand; }; void strandSample() { WorkQueue workQueue; // Start a couple of worker threads std::vector<std::thread> workerThreads; for (int i = 0; i < 4; i++) { workerThreads.push_back(std::thread([&workQueue] { workQueue.run(); })); } // Create a couple of objects that need strands std::vector<std::unique_ptr<Obj>> objs; for (int i = 0; i < 8; i++) { objs.push_back(std::make_unique<Obj>(i, workQueue)); } // Counter used by all strands, so we can check if all work was done std::atomic<int> doneCount(0); // Add work to random objects const int todo = 20; for (int i = 0; i < todo; i++) { auto&& obj = objs[randInRange(0, objs.size() - 1)]; obj->strand.post([&obj, i, &doneCount] { obj->doSomething(i); ++doneCount; }); } workQueue.stop(); for (auto&& t : workerThreads) { t.join(); } assert(doneCount == todo); }
And a possible output...
Obj 2 : doing 0 Obj 1 : doing 1 Obj 1 : doing 3 Obj 1 : doing 4 Obj 3 : doing 6 Obj 5 : doing 2 Obj 4 : doing 5 Obj 6 : doing 11 Obj 3 : doing 8 Obj 5 : doing 10 Obj 5 : doing 12 Obj 6 : doing 17 Obj 3 : doing 9 Obj 3 : doing 13 Obj 5 : doing 18 Obj 0 : doing 14 Obj 2 : doing 15 Obj 3 : doing 16 Obj 5 : doing 19 Obj 1 : doing 7
Conclusion
No explicit synchronization required for handlers going through a given strand.
Big plus. Greatly simplifies your code, so less bugs.
Less blocking overall
Big or small plus depending on your connections/threads ratio. The more connections you have, the less likely two worker threads will do work on a connection concurrently, and thus less blocking.
Cache locality
I’d say small plus. Highly dependent on your scenario. But it’s a freebie that comes with no extra complexity, so I’ll take it.
I don’t see any obvious downside of using explicit strands, unless you stick with just one worker thread (which is an implicit strand on its own).
Feel free to comment with corrections or questions.
Read more about:
Featured BlogsAbout the Author
You May Also Like







