Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
Democratizing PySpark for Mobile Game Publishing
How Zynga analytics is leveraging the Spark big data platform to support game studios and publishing operations.
21 Min Read

Over the past two years, analytics at Zynga has been increasingly using PySpark, which is the Python interface to the Spark big data platform. We have central and embedded analytics teams that use PySpark to support mobile publishing operations including analytics and reporting, experimentation, personalization services, and marketing optimization. I presented at Spark Summit 2020 about how we opened up this powerful platform to our entire analytics organization, and discussed some of the challenges that we faced as well as novel applications that our team developed. This post provides a text version of the video presentation, which is available here. Our Machine Learning (ML) engineering team also presented at the summit on novel applications of reinforcement learning.

I’m a distinguished data scientist at Zynga, where my role is to explore new technologies and to advocate for expanding the tech stack of our analytics teams. This session aligns with the theme of the conference, which is to democratize tools for AI and Big Data. At Zynga, we’ve aligned with this theme by opening up the Spark ecosystem to our full analytics team. We did face growing pains and scaling challenges with this approach, but we’ll discuss how we overcame these hurdles and provide some best practices for scaling Spark within your analytics organization.

We are in unprecedented times, and the conference being virtual this year reflects this reality. One of the ways that Zynga has responded to the COVID pandemic is by leading an initiative with the World Health Organization, where we partnered with dozens of game publishers and studios to spread messages about social distancing through games. The Play Apart Together initiative amplified communications about how to stay safe during these challenging times, while still remaining connected with friends and family through gaming. Our mission is to connect the world through games, and I’m proud that Zynga played a vital role in this initiative.

Our analytics team at Zynga is now more than 50 people, and we’ve opened up the PySpark platform to the entire organization. Anyone that is part of Zynga analytics now has access to use this platform to scale analyses and ML models to massive data sets. While opening up this powerful tool has helped accelerate the output of our analytics organization, we did face a few challenges and growing pains as more team members adopted the platform for everyday tasks, and we’ll highlight a few ways we’ve overcome these issues. One of the key ways that we addressed these challenges was by putting together a broad set of training materials and setting up policies to keep clusters maintainable and costs under control. While it did take a bit of effort to open up PySpark and drive adoption of the platform, we found that our teams used Spark in novel ways that have resulted in useful analyses and tools for our game teams and live services.

Zynga has a diverse portfolio of games, and has embedded analysts and data scientists that support the studios that develop these titles. We refer to our games that make over $100M annually that we expect to thrive for several years as “Forever Franchises”. At the time of recording this session, we had 6 games that met this criteria. Since then, our acquisition of Peak Games has pushed this number to 8 with the addition of Toy Blast and Toon Blast to our portfolio.
One of the challenges that we face as an analytics organization is that our portfolio of games generates vastly different data sets. For example, we have casino games, social slots games, racing games, and match-3 based games with different event taxonomies. While the data sets vary significantly across titles, one of our goals over the past couple of years has been standardizing the infrastructure and tooling that our embedded teams use to process these massive data sets and find insights for our studios. We’ve found Spark to be a great fit for a centralized platform, because it integrates well with all of our data sources and can scale to process huge workloads.

In terms of how Zynga analytics is structured, we’re a combination of our analytics engineering, embedded analytics, and central analytics teams. While the team is a mix of different disciplines, we have the shared goal of helping our game teams find insights and personalize gameplay experiences.
The embedded analysts and data scientists are co-located with the studios that they support, and work closely with product managers and studio leadership to support game launches and live services. These teams are responsible for monitoring the performance of games, running experiments for personalization, and exploring how to improve the user experiences in our titles. The central analytics function, which I’m a part of, is focused on building tools that can scale across all of our analytics teams as well as support publishing operations, such as user acquisition and corporate development. Both of these teams leverage our data platform, which provides capabilities for tracking event data, processing diverse data sets, and building data products that power our live services. Our analytics engineering team is responsible for building and maintaining this platform, which is the backbone of our analytics capabilities.

While our analytics team performs a variety of different functions, there’s several common themes that we see across our different teams in terms of supporting studios as a game publisher. The first is one of the core functions of analytics at Zynga, which is leveraging our data platform to measure the performance of games, and to provide insights for improving the experience for our players. The second common theme we see is running experiments in our games, and partnering closely with product managers to determine the outcome of experiments and how to build upon these findings. The third theme is building data products that drive personalized experiences in our games. For example, we build propensity models that predict which users are likely to lapse in gameplay and can customize the experience based on these signals. The final theme is marketing optimization, which is at the intersection of product marketing and user acquisition. While this has typically been a function of the central analytics team, it’s useful to leverage the domain knowledge from our embedded analysts and data scientists when building ML models that support this function.

Our data platform has gone through a few iterations since Zynga was founded in 2007, but over the past couple of years we’ve seen large, beneficial changes as we’ve standardized the tools that our analytics teams utilize. We’ve been using Vertica as a data store for over a decade, and this database has powered our core analytics functions such as reporting, exploratory data analysis, and A/B testing in our games. While this database has been a consistent part of our data platform over the past decade, many of the tools used by our analysts have changed over time. I categorize these different shifts in tools as three analytics eras at Zynga.
I refer to the first era as the SQL era, because analysts and data scientists spent the majority of their time working directly with our database. This included tasks such as building reports, exploring metrics around the new user funnel, calculating the results of experiments, and wrangling data into a usable format for tasks such as forecasting and propensity modeling. The main tool used by analysts in this era was an IDE for connecting to and querying against our data store. While some analysts and data scientists used the R programming language to build ML models, there was no standardization across different embedded analytics teams.
In 2017, we formed the central analytics team, which resulted in a turning point in our standardization of tools. We decided to move forward with Python as the standard language for analytics as Zynga, and set up a hosted Jupyter notebook environment where analysts could collaborate on projects. We refer to this as the Notebook Era, because our analysts started spending more time in notebook environments than working directly with our database. One of the great outcomes was that using a common, hosted environment for notebooks meant that it was much easier to share scripts across teams, since the environment had a fixed number of libraries with specific versions. While it did take a bit of time for our teams to ramp up on Python as the common language for our analytics teams, the benefit quickly outweighed the cost of training our teams, because teams could more easily collaborate and it was much easier to perform analyses across our full portfolio of games, rather than individual titles.
The current era of analytics at Zynga is referred to as the Production Era, because our analytics teams are now leveraging tools to put ML models into production. Our analysts are now leveraging PySpark to build batch ML pipelines that scale to tens of millions of players, we’re building endpoints and web tools with Flask to support game and publishing teams, and we’re partnering with analytics engineering to build real-time predictive models using AWS SageMaker. Instead of finding insights and handing these off to game teams, our analytics team is now much more hands-on in building systems that power live services based on these insights.
One of the changes that occurred over the past couple of years is that we’ve provided our analytics teams with more access to tools than what was previously available. While we’ve now opened up our Spark environment to the full team, we started with limited access and demonstrated the usefulness of the platform before scaling to all of Zynga Analytics. Once we saw that our analysts and data scientists could build end-to-end ML models, we wanted to empower more and more of our teams to use this platform.

There were several reasons why we wanted to open up our Spark ecosystem to all of our analysts. One of the core motivations was that we wanted to provide a path for our analysts to continue developing their technical chops and level-up their skill sets. Getting hands on with Spark and building end-to-end pipelines is one of the ways that analysts can continue their career progression at Zynga.
Another motivation was that we wanted to standardize on tooling that enabled our analysts to work with clusters of machines, rather than single instances which was a restriction within our Jupyter notebook ecosystem. We are using Databricks as our Spark platform, which provides cluster management, job scheduling, and collaborative notebooks. Similar to this motivation, we wanted to update our platform to cover more of the types of tasks that our teams are performing. For example, some teams needed to process large data sets that were not available in our database, and Spark has a variety of data connectors which means that we can use this platform as a unified solution. Also related, was that we wanted our teams to be able to scale to larger problems, such as creating propensity models for our full user base rather than a single game or cohort of players.
The final reason that we wanted to open up the platform to all of our analysts was to distribute the ownership of jobs that are running on the platform. Instead of having our analytics engineering team be responsible for all monitoring of scheduled jobs, the analytics team that sets up a job is also responsible for monitoring the job failures as well as model maintenance. Distributing ownership has been critical as we’ve ramped up the number of jobs and tasks running on the platform.
The first growing pain that we faced when transitioning to PySpark as our standardized platform for large-scale analytics was that our teams needed to learn PySpark, which can be described as a dialect of the Python language. While PySpark can run any Python command, the true potential of PySpark is unlocked when you leverage Spark dataframes and libraries that use this distributed data structure that enables commands to run on a cluster of machines instead of just a single driver node.
To bootstrap the process of adopting PySpark for running everyday tasks, we started building a collection of training materials to help our teams ramp up in this new ecosystem. Our training materials included sample notebooks that perform common operations, onboarding materials that we authored for getting started on the platform, and training sessions that we have as part of offsite team events. We wanted to provide enough material to ensure that our teams could perform their everyday tasks within this new platform.
The next step we took towards training on this platform was mentoring. In addition to the offsite events that resulted in recordings of training sessions, we provided more direct mentoring as well. We held office hours where our more experienced PySpark users could answer questions for our team members that were still learning the platform. This approach had mixed results, but a positive outcome was that the most active attendees were partnered up with mentors that could provide directed feedback.
While we tried to get ahead of the curve in terms of training materials, it was still a challenge to drive adoption of the platform once it was rolled out to the full team. We found that one of the best ways to drive adoption of the platform was to pair up different teams that needed to leverage the platform in order to complete a project, which resulted in cross-team collaboration. For example, we had a team that was doing a reinforcement learning project within our Jupyter notebook environment, and when we added our ML engineering team to the project the data scientists learned how they could scale their existing workflows by porting them to PySpark.
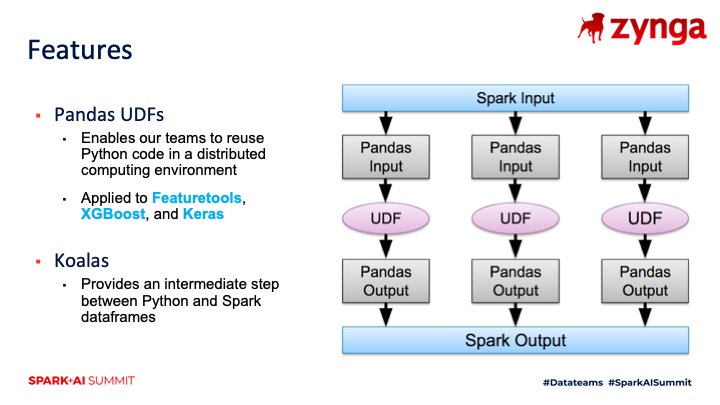
Another way that we worked to accelerate the adoption of the platform was by leveraging features of the PySpark ecosystem that are familiar to Python coders, but under the hood enable the notebook to run in a distributed fashion across a cluster of machines. Pandas UDFs are a way of authoring functions in a divide-and-conquer approach, where you define how to partition your data set, write standard Python code to operate on the subset of data, and then combine the results back into a distributed data frame. I discussed how Zynga uses this approach at Spark Summit 2019.
Koalas is another feature in PySpark that we’ve explored for enabling our analysts and data scientists to make the jump from coding in Python to PySpark. It provides the same interface as Pandas dataframes, but executes in a distributed mode. While it’s not currently possible to simply replace these libraries to make existing Python code work in a cluster environment due to limits in the implementation, it does provide a useful bridge for learning how to work with distributed data sets.
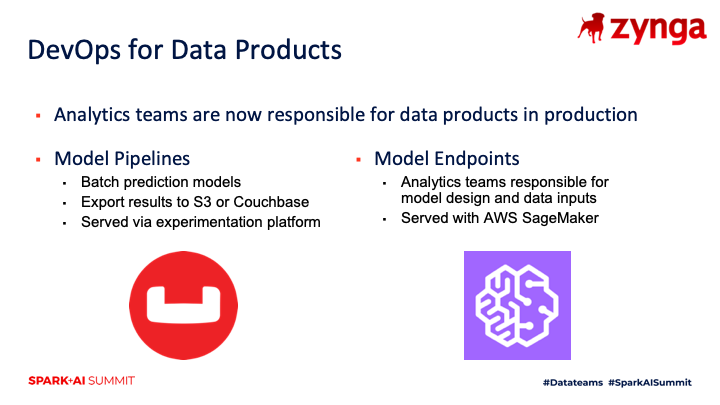
We’ve distributed the ownership of data pipelines for ML models, which has enabled our analytics team to scale up by an order of magnitude on the number of models that we have in production. While our prior approach was for data scientists to build model specifications and hand them off to our analytics engineering team for production, our new model is to collaborate across these teams and have analysts and data scientists own more of the DevOps aspects of live ML models. We have multiple approaches for putting models into production, such as building batch pipelines that push predictions to our application database, or partnering with ML engineering to set up a model as a web endpoint using AWS SageMaker. While our analysts and data scientists are not responsible for monitoring the infrastructure that powers these models, they are responsible for monitoring the uptime and performance of models that are serving predictions.

Another way that we’ve made the platform more accessible for our team is by authoring an in-house library that performs common functions that our analytics teams need to perform. This includes reading and writing to various data sources, as well as publishing ML outputs to our application database where the predictions can be used by our live services. We also built some model maintenance tools, but we’ve been migrating to MLflow as the library matures and provides more features.

As we opened up the platform to more team members, one of the issues that we faced was conflicts in library versions across different notebooks. We also didn’t want to spin up a cluster per user, because the cost could grow out of control. We decided on a policy where interactive clusters have fixed library versions, and scheduled jobs are set up to run on ephemeral clusters, meaning scheduled jobs do not interfere with any other tasks. Additionally, for teams working on new workflows, the team can request a development cluster to test out the workflow before migrating to a scheduled job running on an ephemeral cluster.

While we distributed ownership to embedded teams that are running jobs, we still had a gap in identifying owners of jobs. Before we opened up the platform to all teams, we did an audit of existing jobs and made sure that any running jobs were producing outputs that were being used by our game teams. Once we completed the audit, we then set up a process for scheduling new jobs. Now jobs require an owner, a backup owner, and a team alias to be scheduled, and we collect logs on which model outputs are actively being used by game studios. For tasks that we plan to run long term, we migrate the workflow to Airflow where we have robust monitoring.
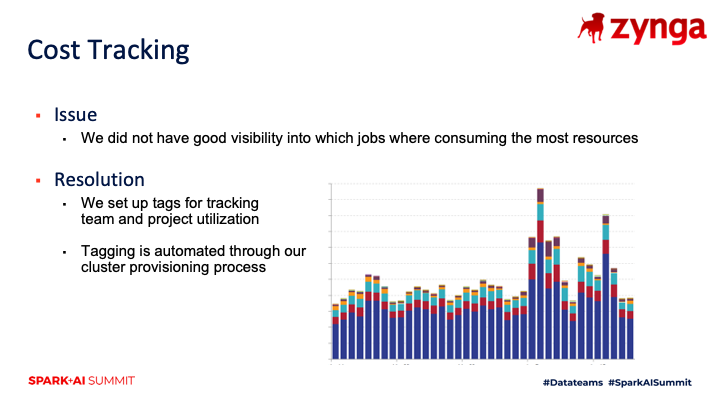
An additional lesson we learned was about cost tracking. We unleashed an excited team on a new platform and our team was eager to use features such as GPUs for training deep learning networks. While anyone can attach notebooks and run PySpark scripts, we have constrained cluster creation to our ML engineering team, which is part of analytics engineering. To control costs, we tag all clusters using scripts to make sure that we can monitor expenses. We also sunset old clusters and deprecate project-specific clusters as needed. Our goal is to avoid long-running clusters that require specific libraries, and instead set up shared clusters with up-to-date libraries.

We opened the floodgates to this new platform, but it took some nudging to get teams to explore this platform. While it was a notebook environment that was similar to Jupyter, it also had challenges. For example, the delayed execution of tasks in Spark resulted in challenging debugging exercises for our team. Instead of a task failing immediately, a script might complete several steps before failing.
While our initial approach was to have a Slack channel as a catch-all for Spark questions, we discovered a higher signal-to-noise ratio when we paired up newer Spark users with experienced Spark users. We also focused on cross-team collaborations to make sure that we had a mix of different experience levels that were working on projects.
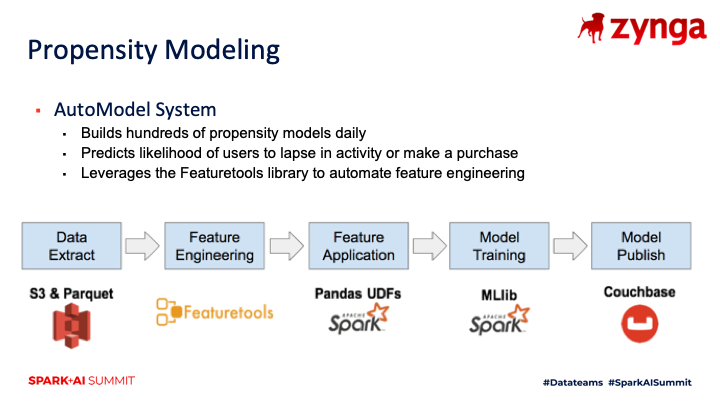
One of the first projects where we found success with adopting PySpark was the AutoModel system that builds hundreds of propensity models daily. This is an end-to-end workflow that pulls data from our data lake, applies automated feature engineering using the Featuretools library, and trains classification models using the MLib library included with Spark. The output of the workflow is predictive scores that are written to our application database, which is built on Couchbase. Once the results are published to Couchbase, our game teams can use the predicted values to set up experiments and personalize gameplay experiences. While we had a few use cases in mind for this system,which creates likelihood to lapse and likelihood to purchase predictions for all of our games, our product managers came up with novel applications for these predictive values that we had not anticipated.
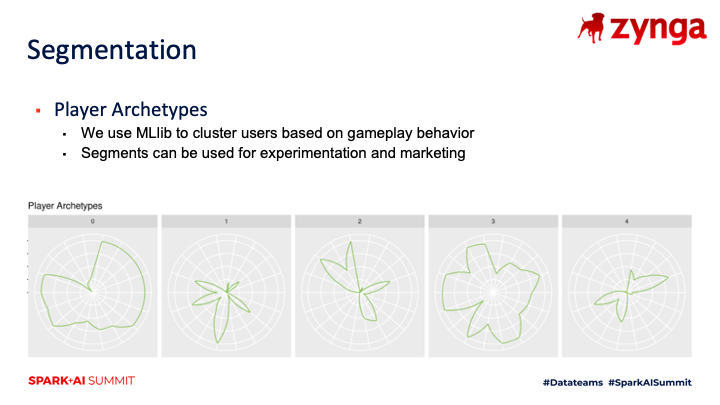
Another use case of PySpark at Zynga is using our data to segment players into different player archetypes, which enables us to better understand our player base. While some embedded analysts had done this type of work for specific games, it was typically done as a one-off exercise rather than a scheduled task that provides up-to-date segments for our game teams to leverage. We were able to use PySpark to put these segmentation models into production, enabling these segments to be used in our experimentation stack. While we had less algorithms available in MLlib versus scikit-learn for clustering players, we were able to standardize our approach and apply this pipeline to multiple games in our portfolio.
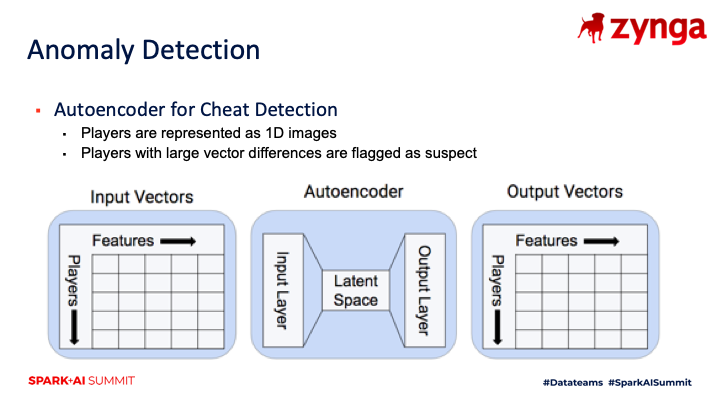
Our analytics teams have participated in hackathons over the past few years, and this was a great opportunity for our analytics teams to try out projects on PySpark. One of the novel applications that resulted from these projects was an anomaly detection system that used deep learning. The system encodes user activity as a 1D image, uses an autoencoder to compress the image to a latent space, and then uses the autoencoder to decompress the image. Players that have large discrepancies between the input and output images are then investigated further. While this workflow was restricted to a single machine rather than a cluster, our team was able to take advantage of large instances set up with GPUs for quickly iterating on Tensorflow models. It’s one of the great ways that opening up this platform has really benefited some of the work that we’re exploring.
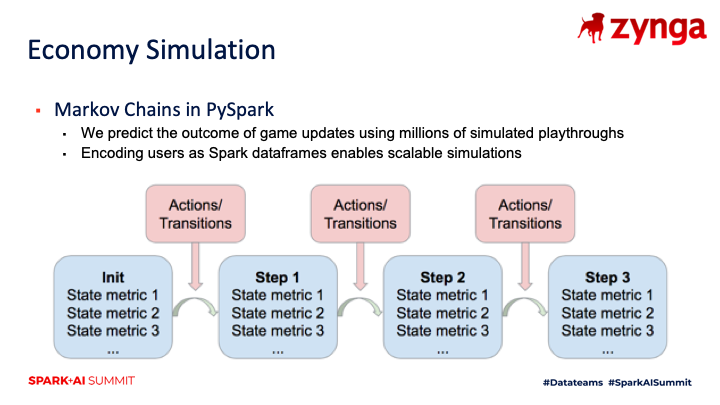
A theme we’ve seen with PySpark is that it enables portfolio-scale analyses, where an approach developed for a particular game can often be scaled to multiple titles. One example of this was an economy simulation project that was initially explored by our Slots analytics teams. While the initial version of this workflow was specific to this genre of games, the team was able to generalize simulating game economies as Markov chains, and ported the approach to use Spark dataframes. The result was a method that could be ramped up to large simulations across several of our games.

While most of the novel applications that we found were focused on building ML pipelines, we also discovered that PySpark was useful for scaling up workloads for other types of numeric calculations.Using Pandas UDFs, we were able to take existing notebooks, and use a divide and conquer approach to make the code run concurrently across a cluster of machines. This allowed us to do distributed work with the scipy, numpy and statsmodels libraries, and helped with scaling tasks such as significance measurements for A/B testing.
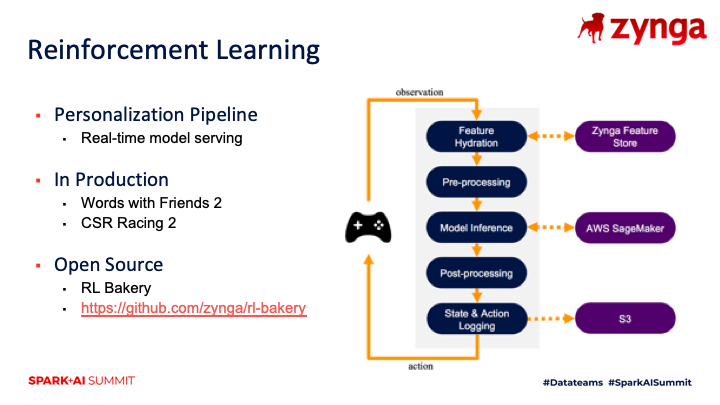
I also wanted to showcase one of the other projects at Zynga, which is our reinforcement learning pipeline called RL Bakery. While this workflow does not use PySpark directly, we found that some of our data scientists were using Spark for offline training of deep learning models, and we needed a pipeline for serving these models in real-time and for providing online updates to the models. We’ve used this pipeline to serve reinforcement learning models in production for both Word With Friends 2 and CSR Racing 2, and example applications include notification timing.

Revisiting the takeaways from this session, we’ve opened up our Spark infrastructure to our entire analytics teams and the result was novel applications for game studios that are now powering live services. While it did take some time to drive adoption of the platform, we did build momentum as more team members started using the platform and we focused on cross-team projects that were able to leverage PySpark to quickly scale up. We also faced challenges with managing clusters of machines and libraries versions, as well as keeping costs in line, but the improvement in output has been well worth the cost. Democratizing PySpark at Zynga has enabled our analytics organization to tackle new and large-scale problems, and has enabled our analytics teams to get hands-on with more big data tools.

Thank you for following along with this session. Zynga analytics is hiring and you can find the list of open positions here.
Read more about:
Featured BlogsAbout the Author
You May Also Like







