Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
How to effectively use procedural generation in games
In this rich excerpt from "Procedural Storytelling in Game Design," developer and proc-gen expert Darius Kazemi shares some ways to use procedural generation more effectively in game development.
12 Min Read

The following excerpt is the second chapter of "Procedural Storytelling in Game Design", edited by Tanya X. Short and Tarn Adams. The book was published last month, and is now available for purchase directly from publisher CRC Press. Use the code "UBM18" (sans quotation marks) to get 25 percent off PLUS free shipping!
As a practice, procedural generation tends to draw a technical type of person.
I use “technical” in the broadest sense of the term, meaning someone who is highly interested in technique, defined as the procedures involved in completing a complicated task. This doesn’t necessarily mean the task must be scientific or technological. The technique I speak of applies equally to the mathematics of graph theory and the practicalities of throwing a clay pot. An artist and an engineer are equally technical.
A common problem with the technical types of people is that it is easy for us to get lost in technique itself, seeking out ever-greater heights of technical achievement in order to impress some unseen, usually internalized spectator. Of course, this is understandable, as we find pleasure in the definition and solution of problems. It’s why many of us chase procedural generation in the first place. This drive can be a positive thing in settings like academic research or the early prototyping phases of a project, but it can get in the way of finishing projects.
In other words, it is easy for us to lose sight of our ultimate goal when creating something and instead get lost in the fiddly details. We end up with projects that increase in scope until they seem like an unfinishable mess. We turn small problems into big ones. This isn’t the worst thing when working in a pure research mode, but it’s a very undesirable situation in the context of a project with a deadline.
One of the most life-changing pieces of advice I ever received was from the game designer and programmer Brian Reynolds. Perhaps best known for the PC strategy games Civilization II and Alpha Centauri, Reynolds was giving a lecture at the Game Developers Conference in the early 2000s about the artificial intelligence systems in his game Rise of Nations.
Tossed off as almost an aside, he said that when you are building the AI for a strategy game, the best place to start with any computer decision-making is to pick a decision out of a hat at random; then test to see how it plays. If the AI is good enough, congratulations, you have saved yourself a bunch of time, and you can move on.
While picking a strategy out of a hat will not itself be sufficient most of the time, the important lesson in Reynolds’ words is clear: when coming up with algorithms, start as simple as you can, test it to see if works, and if it doesn’t, go ahead and complicate things from there.
Two examples from Spelunky
The procedural level generation in Derek Yu’s roguelike platformer game Spelunky is often held up as a high water mark of the field, and with good reason. The level generation has been covered at length in other places, but I want to hone in on two examples from the source code of the original freeware game that illustrate two ways of approaching a procedural generation problem in the simplest possible way.
The first example is the placement of generic treasures in the level. You might think that there would be a system of treasure sub-room templates or an algorithm that intelligently creates appropriate places to store treasure in a level. Spelunky does nothing like this. It handles the problem simply and elegantly with the following algorithm: For any given empty ground surface on the map, the probability of a treasure existing in that space is directly proportional to the number of solid surfaces adjacent to the space.
Because Spelunky is based on a grid of tiles, there are four possible configurations: a tile with the ground on the bottom and nothing to the top, left, or right (an open space); a tile with ground on the bottom and one additional adjacent surface (usually a corner of a room but sometimes a crawlspace); a dead-end nook with access from only one cardinal direction; and a space completely enclosed by solid surfaces.
As the number of adjacent surfaces increases, so does the chance of treasure appearing. This makes intuitive sense: You wouldn’t hide treasure in the middle of an open floor, but you might tuck it into the corner of a room or a crawlspace, and you’d definitely bury it.
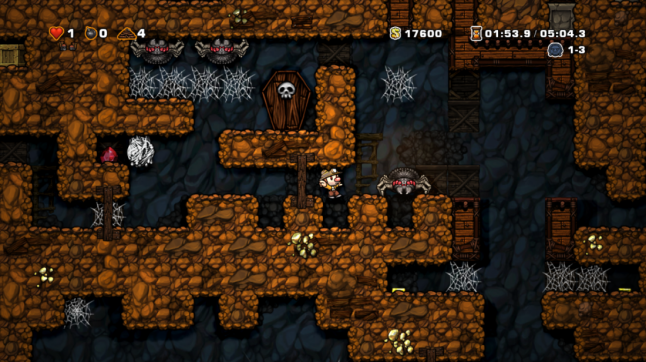
This is achingly elegant, but don’t worry, plenty of Spelunky’s code is just as simple but far more kludgy. The next example we’re going to look at is the placement of the Giant Spider enemy. As you read this algorithm, compare it to the elegance of how treasure is placed: In the first cave tile set, check for a two-by-two block of empty tile spaces below every brick tile that is not the ceiling of the level itself or in a shop, in the starting room, or on the bottom half of a room. If there is a two-by-two block of empty tile spaces, and we’re thus allowed to generate a Giant Spider in this level and have yet to do so, then there is a 1 in 40 chance that we generate a Giant Spider and some cobwebs right beneath this brick. If we do generate a Giant Spider, we should not generate another in this level.
The above algorithm works out to about 30 lines of code, compared to 1 line of code for the treasure placement. While one algorithm is much briefer than the other, both are simple. Neither relies on A* path finding, cellular automata, or Perlin noise, and certainly nothing more complex than those classic standbys. Both algorithms rely on simple checks against features of the game world that are already represented in the game’s model. Neither algorithm introduces any additional data or systems to the game. Could we come up with better solutions than these? Probably, but these are certainly good enough and did not prevent Spelunky from being hailed as a modern classic.
Perception vs. reality
Another hard learned lesson from years as a videogame developer: Almost nobody who views procedural content will understand what is happening behind the scenes.
When presented with an algorithm, most people assume far more complexity than what is actually going on. For example, my Twitter bot “Two Headlines” takes the subject of one news headline and swaps it for the subject of a different news headline. I often have people ask me what kind of natural language processing code I use for it.
The truth is that it’s running a far less complex algorithm: It goes to Google News, clicks on a subject in the subject listing, finds a headline about that subject, and replaces the subject name with a different subject. It’s a simple scraper that does a find-and-replace on some text.

People also assume machine learning where there is none. I think this is because people like to apply narratives in order to understand the world. They like to think, “This level generator seemed random at first, but now it’s making more sense; it must be learning my play style.” People will sometimes attribute intelligence to the algorithm rather than to themselves!
These perceptions are why Brian Reynolds’ advice on prototyping artificial intelligence is so important. Simply picking a random number to make important decisions is often enough to elicit the perception of intelligence.
Using context to take your work from trivial to impressive
Suppose I tell you I have written some code that gets a random noun from an English dictionary and then gives you its definition. I don’t think you would be particularly impressed, and you would not consider it procedural generation except in the most trivial sense of the term.
Suppose I tell you I have written software that generates variations on a joke and that approximately three out of every five jokes it generates cause a test audience to laugh. You would probably want to see this in action.
Finally, suppose I tell you that both of these pieces of code are functionally the same, save for some window dressing.
The code I am referring to does, in fact, exist; it is a generator I made in 2011 called “You Must Be.” The code is simple, and the joke is effective. The algorithm grabs a random noun and its definition, like earthquake: a shaking of the ground caused by the movement of the earth’s tectonic plates.
The window dressing, what I call the “context,” is the addition of a few static words:
Girl, you must be an earthquake because you are a shaking of the ground caused by the movement of the earth’s tectonic plates.
Surreal humor though it may be, it’s genuinely funny stuff. Yet the core algorithm is about as simple as you can get, relying on the dictionary as its mundane data source.
The “context” part is key here. The context transforms the code from a rote algorithm to a joke generator. When you think about it, this applies to all procedurally generated content. Take Perlin noise as an example. I can describe the algorithm, a kind of randomized stepping up and down over a gradient, but the algorithm is sterile, just like our dictionary algorithm. You could have shown the algorithm for Perlin noise to any number of mathematicians who would not have made the leap that Ken Perlin did: applying the algorithm to the context of naturalistic texture generation.
In the world of procedurally generated content, the difference between a purely technical person and a craftsperson or designer is understanding that a great technical leap won’t necessarily create interesting content. Rote algorithms will work just fine if you situate them within an interesting game, visual context, or music theory framework, etc.
The problem might not be your procgen
Imagine you have a level generator for a Mario-style platform game. It places platforms at random throughout a two-dimensional level. The player can jump from one platform to the next, but the level generator sometimes creates gaps that are too big for the player to jump. Your instinct as a programmer might tell you that this is a problem with the level generator; you need to put in a constraint that makes all gaps traversable. But maybe the solution doesn’t lie in the generator.
Instead of changing the generator, you could change the way the player character controls by adding a “run” button. Maybe you include a tradeoff, such as making it difficult to slow down once you’ve started running or causing running to use up a valuable resource. It would probably be easier to tweak the physics of the player sprite than to refactor your level generator. And when you test out these changes, you may find that what was once a “bad” level generator is now a “good” level generator.
The platform generator is responding to changes in context. When you change the physics of the player character, the meaning of the platforms themselves changes. The context also changes if you add rising lava to levels, or make the platforms crumble if they are stepped on for too long. Making technically simple changes can transform a level generator from “generator of barely noticeable terrain” to “generator of nearly insurmountable challenges.” It can also do the opposite! Imagine Spelunky’s level generator with the main character controlled like Pac-Man. Suddenly this algorithm that was a stroke of brilliance is now just making bad Pac-Man levels.
These strategies work well outside the realm of procedural generation as well. “Write a book” is one kind of challenge. “Write a book in a month” is an entirely different challenge that completely changes the possibility space and will cause the writer to go about things in an unconventional way.
Conclusion
The next time you think of a question like “What is the best way to generate a system of caves?”, maybe think, “What is a way that I already know to generate a system of caves, why are those caves unsatisfying to me, and what can be changed about everything but the caves themselves to make them satisfying?”
If you can do this, you’ll implement things faster, you’ll have simpler code to maintain, and you may even gain some insights about your non-procedural systems. I’m asking you to consider the possibility that the problem with your generator is not your procedural generation. It might be everything else.
The last thing I’ll say is that keeping your procedural generation implementations as simple as possible has a nearly invisible long term benefit to your career as a creator. Doing so allows you to ship more things than you would otherwise. Actually putting work out into the world means your art will have viewers, your game will have players, your music will have listeners. You will probably get feedback on your algorithms, and you will discover ways that players interact with or perceive them that you could not have predicted.
This is real knowledge that you can take into your next project or your next iteration of the same project. If you spend five years building what seems like the perfect content generator, I guarantee that no matter how much testing you do you will not learn as much about its shortcomings as you will when you release it into the world.
So just set it free into the world as soon as possible. The next time you make something, it will be even better.
About the Author
You May Also Like







