Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Deep Dive: A framework for generative music in video games
The goal is to use computational creativity and generative techniques to extend the capabilities of human composers.
1h 3m Read

Game Developer Deep Dives are an ongoing series with the goal of shedding light on specific design, art, or technical features within a video game in order to show how seemingly simple, fundamental design decisions aren’t really that simple at all.
Earlier installments cover topics such as how art director Olivier Latouche reimagined the art direction of Foundation, how the creator of the RPG Roadwarden designed its narrative for impact and variance, and how the papercraft-based aesthetic of Paper Cut Mansion came together with the developer calls the Reverse UV method.
In this edition, Professor Philippe Pasquier, the director of the Metacreation Lab for Creative AI at the School of Interactive Arts and Technology at Simon Frasier University, and Dr. Cale Plut, an instructor at Simon Frasier University, discuss the potential of generative music, that is, music that generates in response to the player's actions in real-time, offering a generic framework that can be applied across multiple projects and genres.
The elevator pitch
Imagine if game music responded to your actions just as much as the other parts of the game. In the Mass Effect games, different stories, abilities, and visual aesthetics occur based on whether the player follows the “paragon” or “renegade” actions, which evolve over the course of the game. What if the music also did this? What if, in Slay the Spire, a frost deck had frostier music than a lightning deck? What if the music in the latest Far Cry was more subtle and stealthy if you spend your time sneaking around bases, and more bombastic and aggressive if you’re the “guns blazing” sort of player?

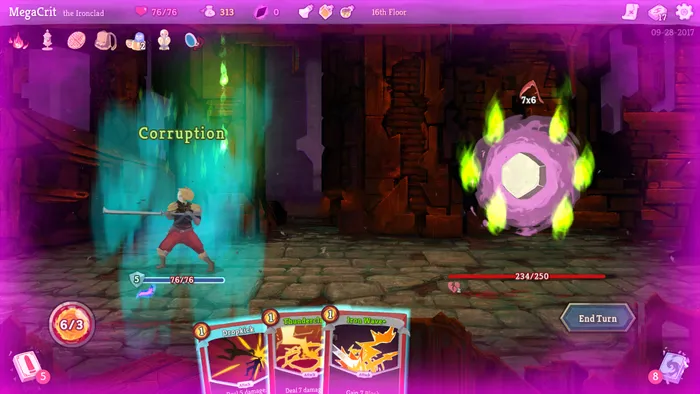
Figure 1: These two Slay the Spire runs play differently, could they sound different too? Images courtesy of MegaCrit
We can keep letting our imagination run, it’s easy to keep coming up with hypothetical ways that music could respond and match a game. This is actually very common in games on a basic level. “Adaptive,” sometimes called “interactive” music, is music that responds to the game. One of the first studies that we did in this research looked at adaptive music and found that players perceive when the music matches the gameplay, and they appreciate it. In other words, music matters.
The issue with adaptive music is that writing and designing adaptive music requires additional work, and the amount of work required can increase exponentially with more complex musical adaptivity. Adaptive music is widely used in the game industry but tends to be quite rudimentary for this reason. Generative music uses automated systems to create all or part of a musical score, and we investigate using generative music to assist in creating a highly adaptive musical score. We present a generic framework for using generative music in games that integrates into any game’s adaptive music and can be applied in a wide variety of musical and game genres.
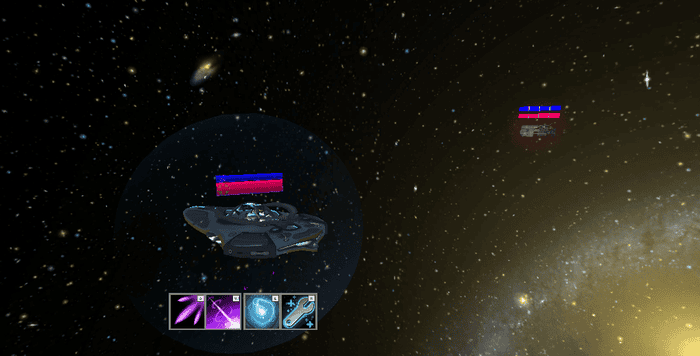
Figure 2: A screenshot of Galactic Defense, the game that we created to implement and evaluate our generative score.
The slightly longer pitch

Figure 3: A soldier in XCOM 2 in concealment, preparing an ambush. Screenshot courtesy of Firaxis.
Let’s start with a concrete example of how really highly adaptive music might work. We’ll use Firaxis’ XCOM 2 for this example. Let’s imagine the following scenario: You start a mission, and everything is covered by the fog of war. You have your “B” team out, let’s say, five reasonably trained soldiers, and you’re unsure what you’re stepping into. The music is tense, subtle, and quiet—anything could be around any corner.
You move forward and catch sight of a patrol. You’re still concealed, so you have time to set up an ambush. However, there are some resources that are about to expire, so you need to move fast. As you come across this patrol, the music has shifted—drums and dissonances are added, building tension and activity to match the boiling pressure cooker of an XCOM ambush.
You’re just getting your last two soldiers into the perfect ambush position when a second patrol spots one of them. The second group screams, alerting the first team of your position. Both patrols dive for cover, but a hail of gunfire from the troops that had made it into position guns down almost half of the Advent forces. Right before the patrol actually saw you, the music started to kick into high gear, and now that the battle is on, the music has been unleashed—drums, bass, and synthesizers explode into a frenzy of sound: violent, sudden, and overwhelming.
The remaining enemy forces make it into cover, and the fight begins in earnest. The music calms down to a driving beat, keeping the pressure on. As you advance and pick off the remaining forces, the music becomes more triumphant, but never loses the tension, knowing more could be around any corner.
Adaptive music
As the elevator pitch mentions, what I’ve just described is called “adaptive” music, or sometimes “interactive” or “dynamic” music. The basic idea—music that changes based on gameplay—has been around for a while. The iMuse system, used in old LucasArts adventure games, shifted the music based on environment—you go from the docks to a kitchen, and the instrumentation and style of the music change to characterize the new location. iMuse was so cool because it could have really smooth and musical transitions.
Adaptive music is common in the games industry, but also pretty rudimentary. One major example is the Mass Effect games, where the music adds layers as the combat gets more intense. If there are a lot of enemies, the music is more bombastic and full. When there are only one or two enemies left, the music is much more subdued. Remember Me had a cool mechanic where the music would add layers as the player grew their combo meter, getting into a groove as the player does. We take some of the design cues for our work from Doom (2016)’s music system—Mick Gordon describes writing “verse-like” and “chorus-like” structures—the game music selects instruments to jam together within each “verse” or “chorus,” and the game switches between verses and choruses based on the intensity of the fight.
Given how easy it is to think of cool and exciting ways to use adaptive music, and given that we already have the tools to make adaptive music, a good question is “why isn’t adaptive music everywhere”? Why don’t we see games with highly adaptive scores, where the music is just as unique to your game as the route that you took through the map, or your build, or how you approach each encounter, or which vegetables are on your Stardew Valley farm, or which Dream Daddy you’re dating? It was easy to imagine our cool XCOM example, so why doesn’t the game music do that?
The catch
Well, there are two main issues. One is that if we want the music to match the gameplay events, we need to be able to tell the future a little bit. Music has a mostly linear relationship with time. Music occurs over time, and we’re used to hearing it change over time in particular ways. While in gameplay, the player might be able to switch easily from sniping around the edge of a map to diving into the action, changes in music require some more setup. This is an issue for adaptive music because if we want music that really lets loose when the player does something cool, the “let loose” part needs to be set up ahead of time, or it risks feeling sudden and shocking. While “wouldn’t it be cool if…” is easy, deciding how to actually represent the gameplay in a way that the music matches, using only the game data, isn’t as easy as it seems.
The other issue is that to have music that can change between methodical and aggressive, or music that sounds different if you’re flanking versus if you’re being flanked, or a score that can adapt seamlessly between concepts like “frosty” and “lightning-y,” someone is going to need to write all of that music. If we want the XCOM music to change when the player is revealed halfway through setting up a concealed ambush, we need to write the “stealth” music, the “discovered” music, and the “regular combat” music, and we need to write these pieces so that they can quickly transition to each other when the conditions are met. As we push for more adaptivity, this problem gets worse: If we want to have states between “stealth” and “discovered,” for example, then we need to either write new music or write the stealth and discovered music so that they can be mixed together with each other to produce the desired effect.
Ultimately, a big reason that we don’t have cool adaptive music everywhere is just economics. Ask any econ professor, and they’ll give you the definition of economics as something like “the study of the distribution of scarce resources.” In this case, our scarce resource is either “composer’s time” or “music budget,” and in the games industry currently, these resources are very, very scarce.
If you had to decide between a two-minute loop of music that would perfectly match the gameplay of a tight combat system and play under every battle, or six different five-minute battle themes that you could use for different combat scenarios, which would you choose? Would you rather have one piece of music that grows with your life simulator farm, changing elements of itself depending on the crops and layout, or would you like two pieces of music per season that capture the “vibe” of those seasons? Adaptive music is cool, and it matters to the player experience, but it would require higher music budgets or some reductions of the music elsewhere. On the other hand, using linear pieces allows you to really focus on writing the music to match the overall game experience rather than the specific moment-to-moment changes.
Generative music: A solution?
So, I’m going to share a little industry “secret”: it’s common, across a lot of the music industries, for people other than the credited “composer” to write music for something. This happens in film, this happens in games, Mozart did it for classical music (thanks Wikipedia). Assistant composers, orchestrators, ghostwriters: it takes a whole team to produce the extremely refined product of industrial music. This is without even mentioning the performers themselves, who interpret the written score into the music itself.
Generative music, or “procedural” music, is music that is created with some degree of systemic automation. In other words, it’s music where a machine does the composing, assistant composing, orchestrating, arranging, and/or performing. Our research focuses on using computer-assisted composition to create adaptive music by partially automating musical composition that would otherwise require additional people, time, and/or money.
For this work, we use the “Multi-Track Music Machine”, or MMM, which is a Transformer model. We use MMM’s 8-bar model, via Google Collab, to expand a highly adaptive but very short musical score. MMM has a whole host of features, but the one that we use is “bar inpainting”—we give MMM a piece of music and have it generate new parts for some of the instruments, which will fit with what the other instruments are playing. In other words, we basically say, “Here’s a clip of music. Can you give me four different piano parts and four different guitar solos that could play with this clip instead of what’s written?” We can do this with any selection of instruments—we could generate a drum part, a saxophone part, and a bassoon part that could play under a given guitar solo if we wanted to.
We compose our score to adapt to match an incoming emotion. We use a three-dimensional Valence-Arousal-Tension, or “VAT” model of emotion. Basically, valence is the pleasantness/unpleasantness of an emotion, arousal is the level of activity or energy, and tension arises when the emotion concerns a “prospective,” or future event. The VAT model is useful for both games and music—valence/arousal describe an emotional reaction to things as they occur, and tension lets us model through time, modeling anticipation and resolution.
We compose an adaptive score that can adapt in these three dimensions simultaneously and independently. The score has 27 manually composed variations, each of which is written to express a particular emotion. This amount of adaptivity makes writing large amounts of music unfeasible, so we use MMM to create additional musical content that expresses the same adaptivity as the composed score.
What came before
If you’re interested in a survey of generative music in games, we published a paper about just that. As an overall summary, we see two main approaches to using generative music in games. Academic research mostly focuses on creating new generative models and technology that can compose music in real-time based on an input emotion. In the games industry, the focus is mostly on extending composed music by rearranging pre-composed and pre-recorded clips of music together in new ways.
There is also some academic research in this area. Various generative music systems have been created by researchers, including Marco Scirea, Anthony Prechtl, David Plans and Davide Morelli, and a team led by Duncan Williams. Generally speaking, this research focuses on the creation of a new music generation algorithm that can generate music in real-time to match an input emotion.
The industry approach
Overall, generative music in the game industry uses random chance to arrange pre-composed and pre-recorded musical clips in new ways. One of the earliest examples of generative music in games comes from 1984’s Ballblazer, which used a technique that was later called “Riffology.” Basically, the game generates a few “riff” variations on the provided score by removing or altering some of the notes and then stitches together these riffs into longer musical phrases, along with matching accompaniment. This is a simple but effective use of generative music in games.
These approaches can also be used with adaptive music. No Man’s Sky, for example, generates music by arranging together musical fragments, and the library of fragments is based on what environment the player is in. Basically, the composition and performance are done by humans offline. During gameplay, the system can rearrange these composed elements based on [what is happening in] the game. This approach is relatively simple to implement and produces a large amount of added variation to the score at a negligible computational cost.
While there are benefits to using this approach to generative music, it does surprisingly little to solve any of the issues with adaptive music. The music team still has to manually write and perform all of the possible musical elements. In order to write music that fits together regardless of arrangement, composers are limited in their overall expressive range—if the highest-energy music has to be able to transition to the lowest-energy music at any time without sounding jarring, then the musical difference between the two clips will be somewhat limited. The term I like for this is the “10,000 bowls of oatmeal” problem—generative methods can often give you endless amounts of stuff that is not very interesting.
The academic approach
Academic research in this area is so different as to occasionally feel like an entirely different field. While games from the industry mostly focus on extending human-composed music, academic approaches generally favor replacing a human-composed score with one that is composed, arranged, and performed online, in real-time, by a computational system. Rather than composing music and having a system arrange it, most academic generative systems take some abstracted input, such as a value corresponding to the estimated tension level of the gameplay. Generally, these systems output music for a single instrument, most commonly a solo piano.
Generally speaking, the focus on these systems is on the music generation itself. The theory, as we understand it, is that if we can create a system that can generate music in real-time based on a generic input like emotion, then all that’s left is plugging some description of the game’s emotion, and we’ve successfully created a universal generic music generation system for games. We can also see ways to incorporate some additional flexibility as the technology improves—we could provide a bunch of other music parameters for a game developer, such as genre, tempo, key, density, or whatever other descriptors we can train the model on.
A benefit to this system design is that, if possible, it could completely remove almost all of the labor of using adaptive and generative music, massively multiplying a developer’s ability to create music themselves. Also, since the systems can compose music in real-time, they could theoretically perfectly match the gameplay at every moment while still maintaining musical transitions.
There are two main issues with these systems. The first is that composing game music is about more than just combining some notes together to produce an emotion. While matching emotion is often described as a goal of game music, it does not represent the entirety of a composer’s skill set. Michael Sweet, in a book about interactive game music, recommends bringing a composer into the creative process early on, if possible, both because the composer will be able to tailor the music more to the creative goals of the game developers and also because the composer’s work may inspire changes or additions to the game instead. These advantages are difficult to quantify and, therefore, hard for a computational system to provide.
The second issue with these systems is that what they output in their current form is so far removed from video game music that it can sometimes feel like an entirely different field. In one, the output sounds like any other recording or production of music written and performed by humans, created to support the rest of the gameplay. In the other, the output sounds like a General MIDI piano, noodling out some notes and chords, swinging from consonant Major triads to dissonant minor triads with tritones and minor 2nds added. Spore is the closest thing to an industrial version of this approach, as it does use generative music to compose and perform music in real-time. However, even with Spore, the generative music is only used during creature creation and editing and provides non-adaptive ambient background music. It doesn’t quite fulfill the promise of the highly adaptive real-time composer replacement.
Comparing the two
There’s a study by Duncan Williams that does a direct comparison between a relatively standard academic generative adaptive system and a relatively standard video game score (World of Warcraft). As far as we know, WoW uses non-adaptive linear music, and if I had to characterize the WoW background music, I would describe it as trying to “set the scene”—providing a consistent, general vibe to a gameplay environment, but not attempting to match or comment on the events or actions of gameplay. This means that this isn’t a perfect comparison, as we’re comparing a generative adaptive score to a composed linear score rather than comparing a generative and composed adaptive score directly. It is still, however, a very useful comparison.
The oversimplified version of Williams et al.’s findings is that players rated the generative adaptive system as more closely matching the emotion of the gameplay than the composed linear score but also rated the generative adaptive system as being quite a bit less “immersive” than the composed linear score. The even more oversimplified version of this, extrapolated out to the trends between academic and industry uses of generative music in games, is this: academic systems are really cool technologically and do a good job of adapting to match emotion (which matters), but sound worse than most commercial game music. While players like the music adapting, the lowered musical quality and fidelity takes them out of the game.
Let’s recap: adaptive music helps to address the differences between the linear nature of music and the unpredictable interactivity of games. However, adaptive music takes additional work to create compared to linear music. Generative music may be able to partially or wholly automate some of this work, to produce highly adaptive scores with little additional cost compared to linear scores. Industry approaches generally use manual, offline composition and performance with real-time, automated arrangement. Academic approaches generally target fully automated real-time composition, performance, and arrangement. It is difficult to evaluate how effective any approach is due to a lack of direct comparisons between similar approaches.
Our approach: Build a bridge
Let’s be honest, we got lucky here. One of the main advantages that we had going into this work was our Metacreation labmate Jeff Ens’ Multi-track music machine. By using an existing generative music system, rather than trying to create our own custom-tailored for games, we could turn our attention to the application and evaluation of generative music in games. Rather than asking, “can we generate music for games?” we asked, “how can we use generative music in games?”
We had two main goals in this research. One focuses on applying the technology in more real-world settings: we investigate computer-assisted composition within current game music production workflows. The second goal focuses on extending previous research: we evaluate the generative music in comparison to work that is musically similar to the generative music while also similar to typical game music. In other words, we want to build a bridge between academic and industry uses, exploiting the advantages of both approaches. We use some manual offline composition and performance, some offline automated composition and performance, and real-time automated arrangement. Figure 4 shows the typical industry pipeline, typical academic pipeline, and our “bridge” approach.
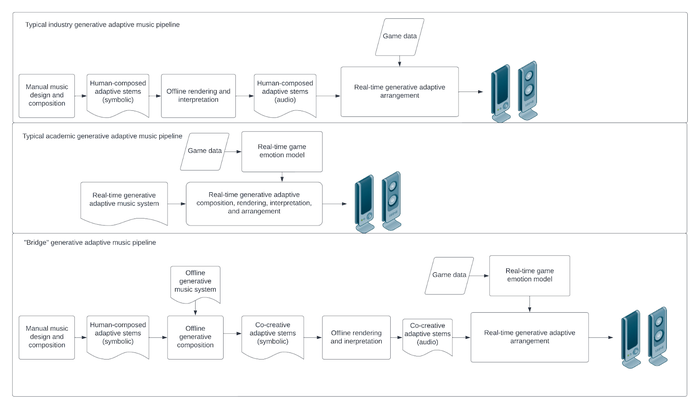
Figure 4: Typical pipelines from the games industry, academia, and our “bridge” approach.
MMM: Generative music system.
The design and evaluation of MMM itself is the subject of Jeff’s own PhD Thesis, and we encourage people who are interested in the inner workings and representations of MMM to read his work. For our purposes, I’m going to describe the parts of MMM that we used and how we used them. We use the 8-bar version of the model running in a Google Collab, which takes a MIDI file as its input and allows us to download the MIDI file as output.
Once a MIDI file is loaded, we can select any number of bars in any number of instruments. We can optionally set some parameters (I used one set of settings when generating our score), and MMM will replace the selected music with new music based on the surrounding score. I like to describe this as interacting with MMM musically rather than parametrically. Rather than trying to define the musical features that we want to see with variables, we compose music that demonstrates those features. Speaking personally as a composer, I find this very useful because I have a lot of practice in writing music that sounds the way I want it to. I would imagine this is true for most, if not all, composers.
Unsurprisingly, the design of MMM influences our computer-assisted, co-creative approach. While previous academic systems often generate their music in real-time, MMM generates music offline, takes a MIDI file as input, and outputs a MIDI file. To increase the performance quality and fidelity compared to previous real-time MIDI synthesis, we use VST instruments in Ableton Live to interpret and render our MIDI scores.
We split our work into three main components. Because we are extending our composed adaptive score with MMM, and we want the score to adapt based on emotion, we must control the emotional expression of the adaptive score. Because we want to control the musical adaptivity based on the gameplay, we must model the perceived emotion of the gameplay. Finally, because we want to implement and evaluate this all within a game, we need to find or create a game.
The IsoVAT guide: Affective music composition and generation
To extend an affective adaptive score with MMM, we need an affective adaptive score to extend. Strictly speaking, we’re trying to match the perceived emotion of both music and gameplay. From a compositional standpoint, we want the music to express the same emotion that a spectator would perceive from the gameplay. For this part of the research, we’re going to set games aside for a moment and focus on music composition within a broad range of Western musical genres.
Previous studies have empirically demonstrated that composers can express basic emotions like “happy” and “sad” with relatively high accuracy. However, these approaches commonly leave the musical manipulations entirely up to the composers—composers are asked to write music that expresses a particular emotion, with no additional criteria. We want to exercise a bit more specific control over the composition of the music, particularly with the complexity of creating our three-dimensional adaptive score. This also allows us to exert parametric control over the output of MMM, without directly manipulating generative parameters.
Put simply, we took past research on music emotion and tried to figure out what we could make with it. There are two main approaches in music emotion research. One manipulates individual musical features, and the other builds models from the analysis of full musical pieces. One example of a feature-based approach would be to play individual major and minor chords and then directly compare perceptions of just those chords in isolation. The alternate approach generally plays complete, real-world pieces for audiences, asking for annotations, and then uses some form of analysis to determine the features that are shared among pieces with similar emotional expressions.
Keeping on-brand, we bridge these approaches together. We collect and collate data from large surveys on music and emotion to build a set of musical features that are associated with perceived emotional expression. We organize this data to describe the changes in emotional expression that changes in the feature will produce. So, in other words, while we compose full musical pieces, we control the music’s emotional expression by manipulating the specific features that are associated with our desired emotional change.
For our sources, we have two main surveys of MER, and several surveys that translate between various emotional models. The collected data from broad surveys of music emotion research is extremely messy, and I won’t bore everyone with the transformations and cleaning we had to do. The short version is that we have several exclusion criteria, depending on the source and the specific transformation, to ensure that we’re only including data that is strongly found across multiple sources. We use this data to create a guide that describes the changes in emotional perception that are associated with changing musical features. Because we’re isolating the emotional dimensions of our VAT model, we creatively name our guide the “IsoVAT” guide. For reference, the full IsoVAT guide is in Figure 5:

Figure 5: The IsoVAT guide
Some readers may note that this set of features seems strange. There is only one rhythmic feature, and several features seem to be describing things that are very similar to each other. As we mentioned above, the input data was extremely messy, and we made decisions on what to keep based on how strongly the mappings were represented in the input data. If there are features that don’t have consensus or that don’t have much research, then we don’t include them.
These descriptions might also seem vague and nonspecific. This is partially due once again to our data source, as we must interpret the wide range of terminologies and descriptions used in previous literature. Another reason for these descriptions is that this guide is intended to describe broad trends across multiple genres and styles within Western music. Also, as we can see in the guide, these interactions are complex and multifaceted, and not every composer will interpret these changes in the same way. With how broad and complex of a goal we have, we’re leaning a bit on a composer’s ability to interpret these features into music.
The composed score
Armed with the IsoVAT guide, we compose our adaptive score. Let me take a personal moment here and mention that writing this score was hard. Our adaptive score is composed to adapt independently and simultaneously in three dimensions—Valence, Arousal, and Tension. This score is also composed to act as a typical adaptive score, and therefore we attempt to compose the music so that any individual clip can quickly and smoothly transition to any other individual clip.
The IsoVAT was extremely useful for this task. It’s trivial to manipulate any one emotional dimension in music—if we asked any composer to write music with varying levels of tension or with various levels of arousal, we would expect that they would be able to do this without much difficulty. However, this gets much harder if we ask for music with varying levels of tension and arousal but a consistent level of valence that can transition between any of the pieces at any time without sounding jarring. Having a set of features to anchor the emotional expression allows us to focus on manipulating all three dimensions independently and on the adaptive nature of the music.
Each level of adaptivity has a level of low, medium, or high for each emotional dimension. We compose one clip of music for each possible combination of the three values of the three VAT dimensions, which gives us 27 clips of music. I affectionately call this score the “music cube” because we can organize it as a cube in three-dimensional space. For each point in space, defined by [valence, arousal, tension], we have a clip of music that expresses the corresponding combination of emotions. Figure 6 shows the basic music cube. Each labeled point is a clip, and as we navigate the cube, we queue up the corresponding clips.
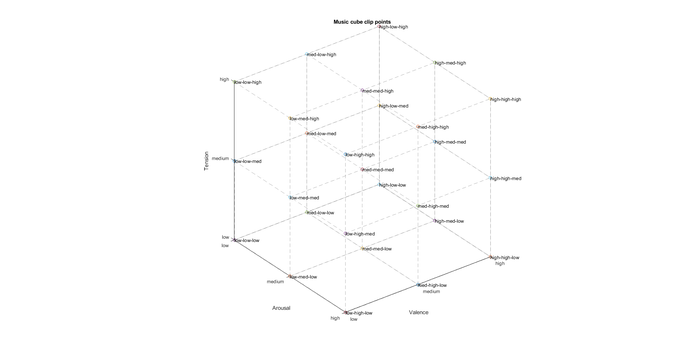
Figure 6: The music cube! Each point in the cube represents a musical clip. For any value (low, medium, or high) of valence, arousal, and tension, we have a corresponding musical clip
Even with the IsoVAT guide, writing 27 pieces of music that are similar enough to transition to each other at any time but different enough from each other to express specific levels of emotion is quite a bit of work. Because of the high adaptivity, each clip in this score is eight bars long, with an instrumentation of drums, guitar, piano, bass, and strings. Basically, we mostly focus our musical attention on creating a highly adaptive and flexible score, which limits the amount of music that we can compose. We now move on to how we adapt and extend this score.
Musical adaptivity
To control our adaptive score, we used Elias, which is a music-focused middleware program. Elias extends a lot of what iMuse does, but is updated to also allow for pre-recorded audio and even includes some real-time synthesis. There are other, more widely used middleware programs, such as FMOD and Wwise, but Elias is particularly suited for our musical score. FMOD and Wwise generally cross-fade between tracks or adaptive levels, while Elias is based on transitioning music at specific timings. We use “smart transitions” in Elias, which auto-detects silence in audio tracks to build transition points; if an instrument is actively playing when a transition is called for, the instrument will continue to play its part until it has a good transition point. This design allows for more musical transitions and more agile adaptivity.
As we’ll discuss with our emotion model, the adaptivity of our score is controlled with a vector containing a valence, arousal, and tension value that represents the modeled gameplay emotion. To connect these continuous values to the musical adaptivity, we define thresholds—effectively creating regions of music instead of points. Figure 7 shows the music cube placed in its continuous space. This gets very busy pretty quickly, and Figure 8 shows the regions of the music cube with a few selected points to demonstrate.

Figure 8: The music cube space, with selected example clips. Colour-coding indicates regions corresponding to clip.
As mentioned, we compose our adaptive score in sets of three—a low, medium, and high clip per dimension, for each possible combination of VAT levels. To help smooth out transitions and to increase the granularity of the adaptivity, we stagger the adaptivity of different musical sections. We manually add a “medium-high” and “medium-low” level to each dimension by having the melody instruments adapt at the intermediate levels, while the rhythm parts only adapt at high, low, and medium. Because only half of the instruments are changing material at any time, the point where they cross over is less obvious.
We end up sneaking some more adaptivity as well; moving from high towards medium will have a different arrangement than moving from medium to high. It starts to all get really complex here, but the main thing is that we end up with seven different possible arrangements per dimension: low, low melody/medium rhythm, medium melody/low rhythm, medium, medium melody/high rhythm, high melody/medium rhythm, and high.
This complicated our music cube. The rhythm section behaves as normal; for any point in space, there is a corresponding musical clip based on the region. For the melody instruments, the direction is important; the melody instruments have several one-way thresholds. If we pass a threshold going in that direction, we adapt the melody instruments. Figure 9 shows the music space from Figure 8, with the melody thresholds added in. The shaded regions, as before, indicate the level of the rhythm section.
The line at the base of each arrow indicates the one-way transition thresholds for the melody instruments, the arrow represents the direction of the threshold, and the color-coding indicates the destination clip when passing the threshold. When the incoming value crosses a melody threshold in the direction indicated by the arrow, the melody instruments transition to the corresponding clip. To show this, we have the same example points in space as in Figure 8, but have added an origin direction; we see that the melody may or may not be playing different clips than the rhythm section, based on where we are coming from on the cube.

Figure 9: The full music cube! Colour-coding in regions indicates corresponding rhythm section clips. Coloured arrows indicate melody section transition thresholds and direction.
The obvious solution, right? We have a video demo of the adaptive score, in our “Music explorer”. If you want to interact with the score yourself, you can download the game from Itch.io or even download the source code from GitHub if you want.
Generative score
We use MMM to cheaply generate variety for our adaptive score. MMM can create new variations for individual instruments and parts in a MIDI file based on the surrounding music. We’ve also mentioned that we split the score into two sections, the melody section and the rhythm section. To create our variations, for each of our initial three levels, we generate a total of six new variations: three variations with new melody parts, playing over the composed rhythm parts, and three variations with new rhythm parts, playing under the composed melody parts. This ends up giving us four total variations (one composed, three generated) for each instrument, for each of our 27 original clips.
Because the variations for each instrument will fit with the composed music from the other section, we should be able to combine any instrument’s individual variations with any collection of any variations from the other instruments. So one generated bass line might play with string harmonies that were generated in a different batch, playing with a different generated guitar part that is playing music with a slightly different emotional expression.
This all adds up to a complex musical score that can simultaneously adapt between seven levels of three emotional dimensions and that has enough musical content that it will probably never repeat. This score can adapt based on an input of VAT emotion levels. This creates an affective, adaptive, generative music score. In order to implement this score into a game, we must also create some model of perceived gameplay emotion that outputs VAT emotion levels.
PreGLAM: The Predictive, Gameplay-based Layered Affect Model
PreGLAM models the perceived emotion of a passive spectator. Winifred Phillips describes one function of game music as “acting as an audience,” where the music should feel like it’s watching the gameplay, and “commenting periodically on the successes and failures of the player.” We extend this metaphor by creating a virtual audience member to control the musical adaptivity, and thus PreGLAM models an audience. While we design PreGLAM to control our adaptive score, we also believe that its framework could be used for a variety of applications—it is a generic audience model.
For our purposes, we have PreGLAM essentially “cheer” for the player. In practice, the difference between “the player, who wants the player to win, feels x when y happens” and “a spectator, watching the game, who wants the player to win, perceives x emotion when y happens” is small and subtle, but it is important to keep in mind. Because PreGLAM is modeling a spectator, we could potentially give PreGLAM any desire—in multiplayer games, for example, we could run a version of PreGLAM for each player or team. PreGLAM modeling a spectator’s emotions also means that we are only interested in the ramifications of the player’s decisions on the gameplay, which means we can take all of our input data from a single source: the game’s mechanics and interactions.
Design considerations
While PreGLAM has many potential theoretical applications, some of its design is specifically informed by our application of controlling music. As we’ve mentioned, music is linear, and it changes through time. Not only do musical transitions need to be set up to avoid sounding jarring, but sudden drastic changes in emotion may also create jarring music. There’s a term, “musical expectancy,” which is basically how much we are able to predict what will happen in music. We’re used to certain musical patterns, so we are sensitive to music that does not follow those patterns. Musical expectancy is strongly implicated in emotional expression. Musical expectancy presents an issue for adaptive music—if we begin transitioning the music towards the current gameplay emotion, the music will always sound like it’s trailing behind the gameplay.
The MMO Anarchy Online used a cool adaptive score that includes logic for transitioning between different cues. The music team mentions the problems they have with musical expectancy in this score; sometimes, the player would die, but the music system would continue to play boss fight music for a few seconds and would not seem to be synchronized to the action. To address this, we want a gameplay emotion model that can describe the current emotion in a way that is also moving towards the future emotion. A chapter in the Oxford handbook of interactive audio suggests addressing this via game design; rather than a building being destroyed when its health reaches zero, we may begin the music transition then and then destroy the building when the musical transition is done—the transition then will synchronize with the gameplay.
We adapt the Oxford handbook’s suggestion; rather than altering the gameplay to match the music, we try to predict what will happen in the immediate future so that the music can begin its transition earlier. Instead of keeping a building alive after its mechanical death to synchronize with the music, we trigger the music for the building’s destruction if it’s below 10 percent health and being attacked by the player. A nice thing about emotions is that we can reasonably assume that a human watching the game will probably predict that a building that is almost dead and is being actively attacked might be destroyed soon. If the prediction is wrong, it’s not more wrong than the human spectator would be, which is what we’re modeling.
PreGLAM’s design diverges somewhat from similar research. We note that we’re using a psychological affect model, which means that we are not dealing with biofeedback like brain signals or EEG or facial recognition. The most common contemporary psychological game emotion models in academic research for music follow a simple design: we have some constant evaluation of game state, and we directly link that evaluation to a continuous model of emotion. Prechtl’s Escape Point maps a “tension” value to how close the player is to a mobile object (mob). If the player touches the mob, they lose the game, and therefore tension rises as they approach the mob. Scirea’s Metacompose is evaluated into a checkers game; a game-playing AI outputs a fitness value for the player’s current state and a value that describes the range of fitness values that may result from the next move. In other words, Metacompose responds to how good the player’s current situation is in the game and how much is at stake in their next turn.
We see similar models outside of game music research as well. The Arousal video Game AnnotatIoN (AGAIN) Dataset authors describe similar approaches that model emotion by training an ML classifier on large sets of annotated game data. The AGAIN database moves towards general modeling by creating a large dataset of annotated game data across nine games in three genres, racing, shooter, and platforming. Outside of academic research, we see these models in adaptive music in the game industry; the previously mentioned Mass Effect, for instance, models the “intensity” of combat based on the number of opponents. Similarly, Remember Me adjusts the music based on the current combo meter.
PreGLAM is based on affective NPC design, having townspeople respond differently to the player based on how their day is going, or how the player has acted to them in the past, for instance. The models we extended are based on the “OCC” model of emotion, titled after the creator's initials: Ortony, Clore, and Collins. The OCC model is a cognitive appraisal model and describes the valenced reactions to events based on how they affect the subject—something that is desirable to the subject evokes a positively valenced emotional response. Tension is described in the OCC model as being evoked by the prospect or possibility of future events, which also have valenced responses based on how they affect the subject. Arousal isn’t particularly delved into with the OCC model, but we directly link arousal to the amount of activity in the game, measured by the number of events happening.
Design
In SIAT Intro Game Studies classes, we teach the “MDA” framework for game design. Mechanics, the rules and structures of the game, are created by a game developer. These mechanics combine in real-time as Dynamics, which describe the run-time behavior of these rules and structures. This produces the Aesthetics, or the experience of playing the game. Game designers create a game on the level of Mechanics by creating objects with actions that can affect each other. The specific experience for the player arises from the ways that these mechanics occur through time, in play.
I would generally characterize the previously mentioned approaches to game emotion as modeling game emotion from the aesthetics of the play. The current number of enemies in a fight, the closeness of the player to in-game mobs, or even a strategic evaluation of the current game state are based on the result of the player’s interaction with the game. The player plays the game, which affects the game state, which represents the output of the gameplay. We base PreGLAM on game mechanics; rather than responding to the UI health bar or in-game variable decreasing, PreGLAM responds to the action that caused the damage.
This design has advantages and disadvantages. The biggest disadvantage, especially compared to ML/DL approaches, is that some elements of PreGLAM must be human-designed and integrated directly into the game. I know for a fact (since I wrote the code) that there are events modeled by PreGLAM that aren’t represented in the visuals or watchable variables at runtime. As an example, in our game, the opponent may follow an attack combo string with a heavy attack. In the code, the opponent passes a boolean to the “attack” coroutine when beginning the combo, indicating whether it will follow the combo with the heavy attack or not. Other than the internal flag on the coroutine, there is no indication in the game variables or visuals that indicates whether the opponent will finish the combo with the heavy attack until the heavy attack is <1.5 seconds from firing. Without building the necessary calls to PreGLAM into the game by hand, we could not have had access to this information.
The biggest advantage of PreGLAM’s design is that a lot of the required design work is already part of game design. Game design is already about sculpting a player’s experience through game mechanics. PreGLAM provides some specifications for quantifying player experience that aren’t standard, but the overall understanding of how the mechanics will combine in play to create a particular experience is one of the core elements of game design. In our combo/heavy attack example, while it would be impossible to determine from a post-hoc examination of the game variables or visuals, adding a single conditional call to PreGLAM is trivial.
Architecture
Mood
Thus far, we’ve mostly been using the word “emotion” pretty loosely, but in the actual work, we use “affect” a lot more. Affect is the more general term for affective phenomena like emotions or moods. Emotions tend to be short-lived (seconds, minutes, maybe hours) and have some subject or trigger, while moods tend to be longer-lived (many hours, days, maybe weeks) and not have a source or subject. We broadly interpret this with PreGLAM, separating the overall affect model into two layers: mood and emotion.
We take some creative liberty in interpreting mood, but for PreGLAM, mood represents the environmental aspects of affective perception. In Dark Souls, Blighttown expresses a different mood than New Anor Londo. In our game, the player fights against several different opponents, and we set a mood value that basically describes how hard the opponent is; rank-and-file enemies aren’t very exciting, but the final boss is.
Mechanically, the mood values serve as a baseline value —without gameplay, what is the perceived emotion of the situation and/or environment? As we’ll discuss in the next section, emotions are modeled as a rise and fall in VAT values in reaction to events. The rise and fall is relative to the mood value. An exciting event in an overall unexciting fight may spike valence, arousal, and tension, but as the play continues, the fight will return to its expected level of excitement.
Emotion
PreGLAM’s modeling of emotions is built around what we call “Emotionally Evocative Game Events,” or “EEGEs.” EEGEs are any game event that we, as a designer, think will evoke an emotional response. This could be anything, from basic combat events like “Player uses a health potion” or “Player gets hit” to more long-term things like “Player discovers lore collectible” or “Player upgrades tool” to really anything we can think of.
EEGEs have two main components: a base emotion value and a set of context variables. The base emotion value describes the basic emotional response to the event. If the player gets hit, that will increase arousal and reduce valence. The context variables describe the ramifications of the event—while getting hit has negative valence, the strength of the emotion might depend on whether the player was at full health or one hit away from dying.

“Evo Moment #37/Daigo Parry”: Each kick from Justin Wong has a much stronger emotional connotation than if Daigo wasn’t on his last breath
EEGEs come in two main flavors: past and prospective. Past EEGEs are easiest; when something happens in the game, PreGLAM models the emotional response. If the player gets hit, PreGLAM models a negative change in valence, with the intensity depending on the player’s current health. For prospective events, we have two subtypes: known and unknown.
Known prospective events are basically events that are queued up in the game code and going to happen. As previously mentioned, the most basic example in our game is the opponent’s heavy attack. Our game is a series of 1v1 fights against opposing spaceships. The opponent has a heavy attack, which the player can “parry” if timed correctly. The heavy attack is telegraphed by a red warning, which is shown about two seconds before the opponent fires. There is a 50 percent chance when the opponent is using their light attack combo that, they will finish it with a heavy attack. This is decided before the light attack combo begins. The player won’t know whether the opponent will fire a heavy attack after their combo, but PreGLAM can begin to model the heavy attack when the opponent begins the light attacks—it is known to the game code; therefore it can be sent to PreGLAM.
Unknown prospective events are more complicated and based on the expected strategy and play. The most basic example for us comes again from the heavy attack interactions. If the player parries a heavy attack, the opponent is stunned and defenseless for a few seconds. The player’s own heavy attack can be risky to use and is most effective against a defenseless opponent. The “correct” follow-up to timing a parry correctly is to fire a heavy attack. If the player correctly times a parry, PreGLAM begins to model the player firing a heavy attack.
During gameplay, PreGLAM calculates the values for each EEGE, based on the base emotion value, context variables, and the time until the event (for prospective events), or the time since the event passed (for past events), and then adds them to the mood values to output a single value each for Valence, Arousal, and Tension. Basically, PreGLAM looks at everything that it thinks will happen in the next several seconds and everything that has happened in the last minute and a half and outputs the modeled perceived emotion of a spectator watching it happen.
Figure 10 shows examples of how PreGLAM would model valence, arousal, and tension from 5 events. In all three Figures, the player successfully parry-riposted 7 seconds ago, took damage 4 seconds ago, is currently dealing damage, and we expect a heavy attack from the opponent in 3 seconds. Each labeled point describes the EEGE and its associated emotional value, as modified by theoretical context variables. The thick dash-dotted line shows the output value from PreGLAM through time, adjusting through time based on the events of the game. In all three figures, we have a mood value of 0 for all dimensions to keep things simple.



Figure 10: Valence, arousal, and tension charts for a theoretical PreGLAM window
Using PreGLAM to control music
This one’s easy. PreGLAM outputs a valence, arousal, and tension value, four times per second. Our adaptive score takes an input of valence, arousal, and tension levels, as explained in the music cube. All we need to do is translate the values to adaptive levels. Skipping the boring details, we chose various thresholds for emotion levels based on the PreGLAM output during development and playtesting. When the PreGLAM output passes a threshold for any emotional dimension, the corresponding change is sent to the score. These thresholds are the regions and melody thresholds of our music cube, and PreGLAM outputs a position in the cube.
In order to evaluate how our adaptive score works in practice, we will want to evaluate it in its context: a video game. We had a choice here as to whether to use a pre-existing video game or design our own. Generally, literature in the area suggests creating your own, which gives you more information and control. For our purposes, the choice is even more clear since PreGLAM is designed to integrate into a game on the mechanical level.
Our game

Figure 11: Visual tutorial for “Galactic Defense”
Figure 11 summarizes almost all of the gameplay. Our game is called “Galactic Defense” or “GalDef”, and is an action-RPG with light run-based mechanics. Because this game was created as a research platform, there are some additional requirements that we have for its design, other than having a comparable experience of play to a video game. The first is that we want GalDef to be easily and quickly learnable, even by those who do not have a large amount of gaming experience. The second is that we want enough consistency between playthrough experiences to ensure that most players have about the same experience while also giving enough variance to have perceivable swings in emotion.
Most of the game is spent in combat, which uses highly abstracted third-person action game combat mechanics, in the vein of 2010-2020s Soulsbornes (A genre named for From Software’s Dark Souls and Bloodborne). The player controls a single spaceship in a fight against a single opponent spaceship. If the player is not taking any actions, they automatically block incoming attacks, which drains their recharging “shield” resource.
The player has two attacks: a light attack combo that deals small amounts of damage over time and a heavy attack that deals a large amount of burst damage after a short wind-up. The light attack combo is triggered with one button press and fires a series of small shots. These shots deal more damage and fire more quickly through the duration of the combo. The combo can be canceled at any time while it’s firing by hitting the attack button again. The player is vulnerable while firing the light attack but begins blocking again immediately upon canceling or completing the combo. The heavy attack has a wind-up time, during which the player is vulnerable. If the player is hit during the wind-up, the attack is canceled. After the wind-up, the heavy attack fires a single shot. This attack deals more damage if the opponent is not blocking.
The player also has two special abilities: a parry and a self-heal. The parry directly counters the opponent’s heavy attack. The opponent’s heavy attack, like the players, has a wind-up before use. This wind-up is accompanied by a visual indicator, where “targeting lasers” center on the player. If the player parries immediately before the heavy attack fires, the attack does no damage, and the player responds with an attack that deals a small amount of damage and briefly stuns the opponent. The self-heal has a short windup, during which the player is vulnerable, and then heals the player for a percentage of their missing health. If the player takes damage during the wind-up, the heal is canceled.
The opponent has very similar capabilities to the player. There are two main differences for the opponent. The opponent’s heavy attack, as mentioned, is not canceled upon receiving damage (though the opponent’s self-heal is). The opponent also does not have a parry ability. Other than these changes, the opponent has identical tools: a light attack combo, a heavy attack, and a self-heal. The general feeling we’re aiming for with these mechanics is to create the feeling of a duel; the player is wearing their opponents down, watching for times to play defensive, counterattack, or turn aggressive.
There are three “stages”, or “levels” in GalDef. In between each stage, the player is fully healed and given a chance to upgrade their ship. The first stage contains one trash mob and one miniboss, the second contains two trash mobs and one miniboss, and the third contains one trash mob, one miniboss, and one boss. In between the stages, the player is fully healed and has a chance to upgrade their ship. There are several potential upgrades, such as “Heavy attack wind-up is faster”, “Self-heal heals for more health”, or “Shield meter increased.” These upgrades mostly affect the speed or magnitude of abilities or the player’s base attributes. The player is shown a random selection of three possible upgrades and selects two of them to apply to their run. This mechanic mainly exists to inject some longer-term variety and player agency into the game.
Figure 12 shows the player progression through the full game, along with our assigned mood values. The solid lines show the differences in mechanical power between the player and opponents through the three stages. The symbols show the mood values for each level, which are based on an interpretation of the relative power level. In our music cube, we assign values based on 0 as a neutral value for the emotional dimension. For GalDef, we manipulate the mood values so that at the final boss fight, the adaptive score has access to its full expressive range. We do this by using 0 as the maximum mood value; as the player approaches the maximum mood value, the score can more equally move around the music cube to match the moment-to-moment emotion.
Putting it together
Let’s quickly recap what we have and what we’ve done. We wanted to investigate how to use generative music in video games, bridging knowledge, tools, and practices from academic and game industry approaches. We also wanted to evaluate our application of generative music in comparison to a composed adaptive score and a composed linear score that all share similar instrumentation, style, function, and performance quality.
To control the musical adaptivity of our scores, we break the task into composing an emotionally adaptive musical score and creating a perceived game emotion model. For our adaptive score, we create the IsoVAT guide, based on past music-emotion literature, which is empirically evaluated before being used to compose our adaptive score. For our perceived game emotion model, we create PreGLAM, which models the real-time perceived emotion of a passive spectator based on the mechanical interactions of the games. Both PreGLAM and IsoVAT interpret previous research literature into design and composition frameworks and guidelines that can be interpreted in a creative process. This gives structure and form to the process, allowing for a degree of control over the creative output.
We use the IsoVAT guide to inform the composition of our three-dimensional affective adaptive score. While our score is highly adaptive, it has a very limited amount of musical content. We use MMM to expand the limited content of the score. Because MMM’s output is conditioned on its input, MMMs generated music expresses similar emotions to the input pieces. We incorporate MMMs music into our adaptive score, creating a massive amount of musical content; our musical adaptivity takes us from 27 composed clips to 343 possible unique arrangements. By including MMM’s generations, this expands to about 13.5 trillion possible unique arrangements.
The adaptivity of our generative score is based on the output of PreGLAM, which models the emotional perception of a spectator who is watching the game and cheering for the player. PreGLAM is designed into a game at the mechanical level and models the emotions based on the dynamic interactions during gameplay. PreGLAM mostly models emotional responses to Emotionally Evocative Game Events (EEGEs), which describe an emotional response to gameplay events based on any important gameplay contexts. PreGLAM is also predictive and incorporates the possibility of future events to model tension. This predictive quality also allows for PreGLAM to signal a musical transition before an event has happened, allowing for musical expectancy.
By controlling the real-time adaptivity of a score that incorporates generative music, we produce a game score that is functionally similar to previous approaches that generate adaptive music in real-time, in terms of output. There’s one additional step, which is the evaluation of all of this. While I’ve mostly talked about design and creation, we’re also still doing academic research here. In addition to creating cool new things, we’re mainly interested in creating new knowledge, and part of that is evaluating our work.
As mentioned, music-matching gameplay emotion is one of the most commonly described functions of music in games, and our Music Matters paper indicates that players recognize and appreciate affective adaptive music. Academic research also follows this guideline and often uses emotion models to control musical adaptivity. One advantage of basing our approach on a similar design is that we don’t have to invent the wheel at all. Melhart, Liapis, and Yannakakis created an annotation tool for gathering real-time annotations of perceived emotion, and our annotation gathering is nearly identical.
Evaluation
We evaluate PreGLAM itself and our generative music at the same time. We’re collecting a lot of the same data anyways, and one of the major difficulties in carrying out the study is that people have to play the game for long enough to get familiar with it, even before doing any of the study parts. Basically, PreGLAMs model is partially based on a knowledge of the game mechanics and how they interact with each other in play. Therefore, we need to be sure that our participants have a similar understanding if we are going to compare data from the two sources. We build PreGLAM’s model of game emotion, but participants must build their own internal model of game emotion.
As we’ve described, PreGLAM outputs a value for valence, arousal, and tension. In addition to using these values to adapt the music, PreGLAM outputs a .csv file that has the same values, measured about every 250 ms (Unity makes exact time codes hard). This CSV file represents, in theory, what a spectator would perceive if they have a good understanding of the game mechanics and are watching it being played. In order to see how accurate that CSV file is, we ask people who understand the gameplay to provide annotations of what they perceive while watching gameplay.
We ask participants in our evaluation study to download GalDef, and play the game for around 25 minutes without any specific goals. GalDef has an interactive tutorial, and we also built a video tutorial and created our text-based tutorial seen above. Once the participants are familiar with the gameplay, they go to a website we built to enter their annotations. Figure 11 is a screenshot from this website; the x-axis represents the perceived emotional dimension level, and the y-axis represents time in seconds. This lets the annotator see their annotation history while annotating. Since annotating valence, arousal, and tension at the same time would be really difficult for a human, we ask each participant to annotate one emotional dimension. Our annotation website collects data every 250 ms. This gives us an actual human perception of the gameplay with the same data format as PreGLAMs output.
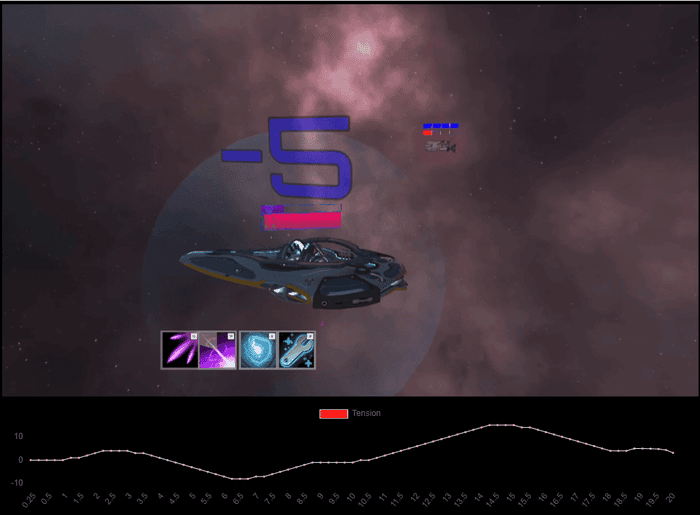
Figure 13: A screenshot of our annotation interface. While watching a video of gameplay, the participant indicates any perceived changes in the assigned dimension (tension, in this case) by using their keyboard.
For the music evaluation, we wrote one additional score. While we could easily evaluate our generative score in comparison to the composed adaptive score, we also wanted to compare the score to a linear score that has some emotional expression. We created a linear score by arranging clips and instruments from the composed adaptive score, with some changes and transitions, into about four minutes of linear music. This linear piece rises and falls in levels of valence, arousal, and tension over time. Since this score is linear, you can easily listen to it on the Internet.
We evaluated the score in two ways. The first was to have participants, when they’re providing annotations, give annotations to four videos. One video had the linear score, one the adaptive score, one the generative score, and one had no music. The video with no music served as the “baseline” PreGLAM evaluation, and we compared whether the music following the gameplay had any real-time effects. This mainly evaluates PreGLAM itself but also looks for any changes in perceived emotion that the music may cause. Our other evaluation encompasses our broader pipeline and design and was based on the previously mentioned work by Duncan Williams et al. with WoW. Once participants are done annotating the videos, we ask them to rank the “best” video in several categories. We ask similar questions to Williams et al. but use rank over ratings, mostly to avoid asking too much from the participants on top of learning the game and providing the annotations.
Results
We did ok. When we’re measuring something as complex as the real-time perceived emotion of a video game and how a co-composed generative score matches it, there is a lot of inherent noise and chaos. Also, while we’re matching past approaches in a lot of ways, the exact specifications of what we’re looking at are a little different, so it’s difficult to make any strong claims. For PreGLAM, the news is pretty straightforward: it works, at least, it works significantly better than a random walk time series. This isn’t a strong comparison, but it’s some absolute measure. A lot of the benefit of PreGLAM is not that it’s expected to work better than other state-of-the-art approaches, it’s a different way to get to a similar output, so “works” is what it needed to do for now.
In terms of how much the music affected the real-time emotional perception, it’s hard to say, but there are trends. Adding music at all reduces how close the PreGLAM annotations are to the ground truth annotations, which I read as showing that the music is affecting the perceived emotion. This is strongest with the composed adaptive score; because the adaptive score has such limited musical content compared to the generative score, I wouldn’t be surprised if the adaptive score ended up with some weird transitions, which may have messed with the perceived emotion.
Our post-hoc questions asked which score matched the gameplay, which score matched the game emotion, which score immersed the participant in the gameplay, and which score the participant liked the most. In our post-hoc questions, we end up seeing almost exactly what we wanted to see. Remember that Williams et al. found that their score outperformed the linear score in terms of matching the gameplay emotion but was rated quite a bit lower on “immersion.” Our results can’t be directly compared, but our adaptive and linear scores are almost equal in terms of matching the gameplay and are also almost equal in terms of “immersion.” Figure 14 shows our result by percentage; each bar indicates what percentage of participants ranked the corresponding video as the highest for that question. Each colored bar indicates the source of the music.
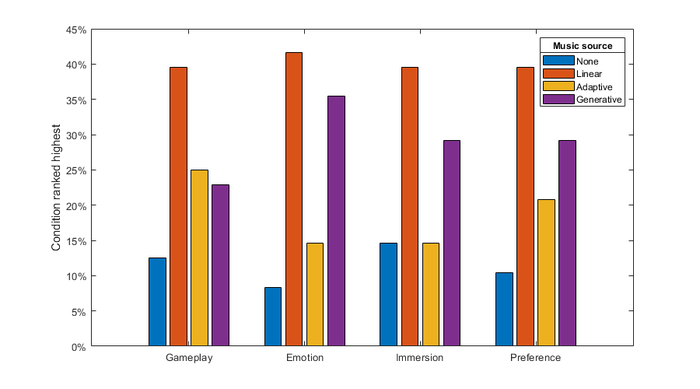
Figure 14: Questionnaire results
At first glance, the emotion matching result looks like not a great result since Williams et al.’s generative score significantly outperformed the compared linear score, but there are a few differences that I think explain why this is encouraging. The first one is that our approach has a bit more complexity and detail to everything—our score is adapting in an additional dimension of tension, and PreGLAM model the moment-to-moment actions of gameplay, whereas the Williams et al. study adapted to longer-term game state flags like “in combat.” The second reason is that our linear score has a wider expressive range than the linear score in WoW. I don’t have the exact details of what linear music Williams et al. used, but the music for the area that the study was performed in has a mostly static musical expression. There’s a concept called “serendipitous sync,” which is when a linear score matches up with gameplay by, basically, luck. This may happen with our score, which explains why the linear score may be perceived as matching the emotion of the gameplay. Our results compare our generative score to a much more similar linear score.
In terms of the immersion rating, we pretty much nailed it. If we had to quantify our evaluation goals for our approach to generative music, it would be “matching previous results on emotional congruency (how well the emotions match), improving previous results on immersion.”
Conclusion
Well, that’s the thesis. We built a generic production pipeline for using a computer-assisted adaptive score that fully integrates into contemporary design tools and processes, leveraging a generative co-creation approach to provide additional variety. We also implement this pipeline into a game, creating a highly adaptive score with limited musical variety, extended with MMM. We then evaluated it, and it all works. To sum up the main motivation behind our approach: we’re looking to use computational creativity and generative techniques to extend the capabilities of human composers. Similarly, we use the findings of previous research in music and game emotion to create tools that are intended to integrate into the creative process. We aim to bridge the gap between academic research and industry approaches by incorporating the strengths of both, and we think we did a good job of that.
Pros and Cons
Both previous academic approaches and our approach target a generic model of using generative music in games. Where our approach primarily differs is that while other academic approaches target genericity by attempting to build universally applicable models of game output, we target genericity by creating frameworks that can universally integrate into design processes. Our advantage has both advantages and disadvantages.
While our approach can be used to extend a human composer’s abilities, it does not necessarily remove any and may add to design work. With sufficient advancement in technology, the approaches from academia could theoretically have all of the advantages of our approach while reducing the work required to use it to almost nothing. Because our approach extends human design, we cannot replace it.
One advantage of our approach is its modular design. Our use of generative music does not depend on the adaptive score having three dimensions or on using emotion to control the adaptivity. Our emotion model could be used for a range of purposes beyond controlling music, such as highlighting exciting moments in esports games, automatically adjusting game AI to manipulate perceived emotions, or analyzing the experience of play. Similarly, having a set of literature-derived and ground-truthed musical features for manipulating emotion in composition could be used beyond game music.
The biggest advantage to our approach is that the technology required for the basic workable idea exists and is not theoretical. Technological advancement will continue to improve this approach, and this approach can flexibly advance with the technology, but a fair amount of the immediate work is design work. Basically, we can begin to explore how to use generative tools rather than waiting for generative tools to be advanced enough that we don’t need to know how to use them. This is also an advantage to our approach because we believe that there is a large, untapped source of working game music knowledge in the games industry, there is a large untapped source of music technology in the academy, and that the best path for advancement is to bridge the gap between them, using the strengths of both.
What’s next?
We didn’t perfect the use of generative music in video games. We did create a generic framework and pipeline for using generative music within common design tools and processes that can apply across a wide range of game and music genres. We used this framework to create an implementation of affective adaptive generative music in a game and empirically evaluated it. Our paper describing this pipeline won an honorable mention at the Foundations of Digital Games conference, and we think that it is an important step in advancing the use of generative music in games.
However, there are also several directions that this research points to, with several possible applications. PreGLAM could be extended with ML/DL techniques while maintaining the advantages of its framework. Also, while PreGLAM functions, evaluating it in comparison to a post-hoc emotion model would give more information about its efficacy. On the game music side, there are many other ways to use MMM or similar models to extend scores.
We’ve mentioned before that how music changes over time is one of its core features. We looked at the moment-to-moment gameplay, with music adapting in a single active gameplay segment. Long-term game form, and long-term music adaptivity, is one of the areas of future work that I’m most interested in. NieR: Automata has a fantastic score that changes throughout the game based on the events of the story and their implications on the environment and characters. This was done entirely manually, by using generative music, similar outcomes could be reached by smaller teams, with more musical content.
Composing music to match long-term game form, as with adaptive music, requires additional labor and time than composing music independently. Therefore, focusing on integrating the musical evolution with the game evolution runs the risk of creating too much musical repetition. One common way to extend music by live musicians is to have solos; a single musician will improvise a melody while the other musicians improvise background chords. Generated solos, which are composed to fit over the background chords, could be used to similar effect. After the player has heard a piece of music a few times in a row or a bunch of times over the course of the game, the music could “loosen” for a while, while keeping the same overall sound.
There are, of course, other possibilities for future work as well, I think we could imagine possibilities and never run out. For a run-based game, we could write a few different grooves for various starting parameters; we then generate a new melody for each run based on the harmonic structures that are composed to match the properties of the run. For a life simulator, we could write several variations for different style options and combinations and generate additional similar music. In a tactical RPG, we could have several basic musical styles and generate individual variations for individual units, creating a score that changes as the team does.
We’ve described our work as co-creative and as computer-assisted composition. Another, broader term for this is “mixed-initiative”, and these systems are on the rise in a range of areas. In addition to our specific implementation, we’ve also worked with Elias to work towards integrating MMM into future versions, allowing for an easier workflow when using our pipeline.
One of the key aspects of any future work is moving towards more collaboration between academic and industrial approaches to generative music. If we see a gap in knowledge in current academic research in this area, it is mainly in the practical understanding of interactive music design and game design, which the games industry is full of. If we see a missed opportunity in industrial approaches in this area, it is in its overly conservative approach to music, missing the potential transformational power to game music design by favoring the most basic workable approach. In bringing together the two camps, we believe we can exploit the advantages of both. We envision a future where composers are armed with cutting-edge co-creative technology, able to design deep musical interactions with a sculpted score, producing a stylistic, complete, customized score for each playthrough. We believe this work takes an important step towards this goal.
About the Author(s)
You May Also Like





.jpeg?width=700&auto=webp&quality=80&disable=upscale)








