

Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Real World AI Fueled by Games
How are video games advancing AI? What is Embodied AI? What is Embodied Cognition? This article offers an overview of Embodied Artificial Intelligence.
16 Min Read

Unity3D has promoted the Reinforcement Learning branch of Machine Learning with its ml-agents initiatives. Embodied AI is another use of video game technology to train virtual avatars in simulations, so that real robots can interact, see, listen, speak, and learn in the real world. Clearly, video game simulations are fueling the next wave of AI.
(Puppo is an AI demo by Unity3D, using ml-agents)
Originally posted here.
Overview of Embodied Artificial Intelligence
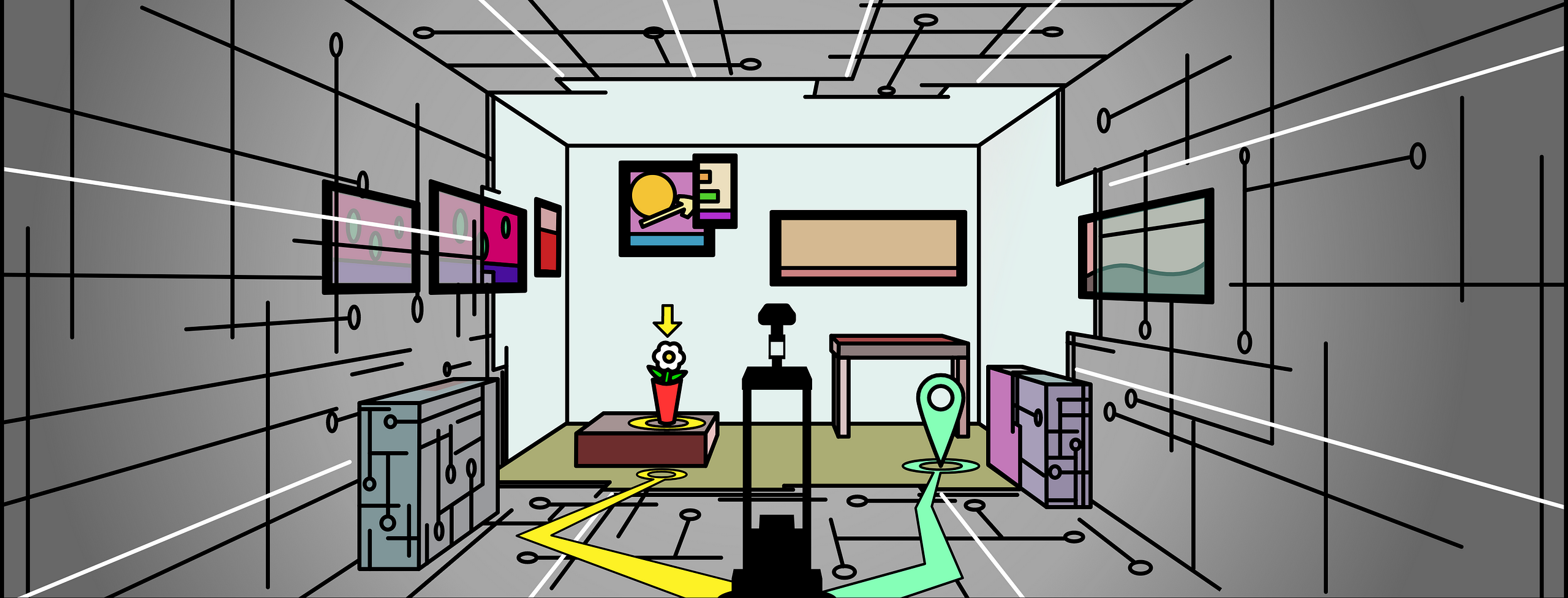
Recent research trends in Artificial Intelligence, Machine Learning, and Computer Vision have led to a growing research space called Embodied AI. “Embodied” is defined as “giving a tangible or visible form to an idea.” Simply put, “Embodied AI” means “AI for virtual robots.” More specifically, Embodied AI is the field for solving AI problems for virtual robots that can move, see, speak, and interact in the virtual world and with other virtual robots -- these simulated robot solutions are then transferred to real world robots.
MatterPort3D allows you to create photo-realistic 3D environments so that intelligent avatars can learn from their immediate environment. The avatars can learn navigation and more with the help of additional sensors (e.g., Computer Vision, NLP, RL). Even Grand Theft Auto is being used as a 3D environment to learn how to drive autonomous vehicles.
History
Linda Smith first proposed the “embodiment hypothesis” in 2005 as the idea that intelligence emerges in the interaction of an agent with an environment and as a result of sensorimotor activity. They argue that starting as a baby grounded in a physical, social, and linguistic world is crucial to the development of the flexible and inventive intelligence that characterizes humankind. Furthermore, the Embodiment Thesis states that many features of cognition are embodied in that they are deeply dependent upon characteristics of the physical body of an agent, such that the agent’s beyond-the-brain body plays a significant causal role, or a physically constitutive role, in that agent’s cognitive processing. While the initial hypothesis comes from Psychology and Cognitive Science, the recent research developments of Embodied AI has come largely from Computer Vision researchers.
AI subfields have been largely separated since the 1960s, subject to various limitations. However, Embodied AI brings together interdisciplinary fields, such as Natural Language Processing (NLP), Computer Vision, Reinforcement Learning, Navigation, Physics-Based Simulations, and Robotics. While Embodied AI requires multiples AI subfields to succeed, the growth of Embodied AI as a research area has largely been driven by Computer Vision researchers.
Computer Vision researchers define Embodied AI as artificial agents operating in 3D environments that base their decisions off of egocentric perceptual inputs that in turn change with agent actions. Embodied AI enables training of embodied AI agents (virtual robots and egocentric assistants) in a realistic 3D simulator, before transferring the learned skills to reality. This empowers a paradigm shift from “Internet AI” based on static datasets (e.g., ImageNet, COCO, VQA) to “Embodied AI” where agents act within realistic simulated environments.

Internet AI. These images from the COCO dataset do not provide a 3D realistic environment.
Motivation
Many of the AI advances in the last decade have been because of Machine Learning and Deep Learning (e.g., Semantic Segmentation, Object Detection, Image Captioning). Machine Learning and Deep Learning have been successful because of the increasing amounts of data (e.g., Youtube, Flickr, Facebook) and the increasing amounts of computing power (e.g., CPUs, GPUs, TPUs). However, this type of “Internet data” (images, video, and text curated from the internet) does not come from a real-world first-person human perspective. Data is shuffled, randomized, coming from satellites, coming from selfie photos, coming from Twitter feeds, and none of this is how a human perceives the world. However, Machine Learning methods are trying to feed this data to NLP, CV, and Navigation problems. While there has been much progress in these fields due to “Internet data” and “Internet AI”, it is not the most suitable data or the most suitable methods. The methods for Machine Learning do not map to the ways that humans learn. Humans learn by seeing, moving, interacting, and speaking with others. Humans learn from sequential experiences, not from shuffled and randomized experiences. The thesis of Embodied AI is to have embodied agents (or virtual robots) learn in the same way that humans learn. Which is why insight from Cognitive Science and Psychology experts is essential. This means that virtual robots should learn by seeing, moving, speaking, and interacting with the world — just like humans.
While “Embodied AI” has a different methodology than “Internet AI”, Embodied AI can benefit from many of the successes from Internet AI. Computer Vision and Natural Language Processing actually work pretty well for some things now (if there is plenty of labelled data). These advances in CV and NLP greatly increase the potential for success in Embodied AI.
Additionally, there now exist plenty of realistic 3D scenes which can serve as simulated environments for Embodied AI training. These environments include SUNCG, Matterport3D, iGibson, Replica, Habitat, and DART. These scenes are much more realistic than the environments that have been used in previous research simulators. The widespread and public availability of these datasets greatly increase the potential for success in Embodied AI.

This is a 3D Map view of the realistic environment. The embodied agent only sees a first person view.
Embodied AI lends itself to applications, such as personal robotics, virtual assistants, and even autonomous vehicles. The combination of NLP, Computer Vision, and Robotics actually make the problem tasks of Embodied AI easier.
Agent and Environment
An agent is merely an abstraction that can take actions in an environment. We refer to this agent as virtual robot, simulated agent, virtual agent, or egocentric agent (due to its first-person views/sensors/interactions). You can think of an agent as a player of a game. On the other hand, an environment is just an abstraction that represents a 3D map with multiple locations, rooms, and objects in the world. It is a simulated environment that represents the physical world. You can accomplish many goals in an environment, such as interaction, navigation, and language understanding. For more information on Agents and Environments, feel free to read our Overview of Reinforcement Learning.
Egocentric Perception
Embodied AI is egocentric as opposed to allocentric. Egocentric perception can be though of as a first-person view. Egocentric perception encodes objects with respect to the agent. Allocentric perception encodes objects with respect to another object (e.g., the front door, the center of the room, etc.). An allocentric perception might be useful if the AI knows the whole map of the environment; however, an embodied agent only knows what they have seen from egocentric perception. An embodied agent does not have access to a map, unless they create it as they navigate the different rooms and locations in the environment. Recall that the Embodiment Thesis focuses on the self, so it would only be appropriate for Embodied AI to also focus on the self.
Internet AI
Embodied AI has additional challenges compared to Internet AI. Internet AI learns from static images from Internet datasets (e.g., ImageNet). These static images are high quality and nicely framed; on the other hand, Embodied AI uses egocentric perception, which produces images or videos that might be shaky and not well composed. The inherent properties of Egocentric Perception create additional changes for Embodied AI as compared to Internet AI. Additionally, the focus of Internet AI is pattern recognition in images, videos, and text on datasets typically curated from the internet; on the other hand, the focus of Embodied AI is to enable action by an embodied agent (e.g. robot) in an environment. Ultimately, the goal is to take all of the advances that Machine Learning and Computer Vision have made in Internet AI and apply it to Embodied AI.
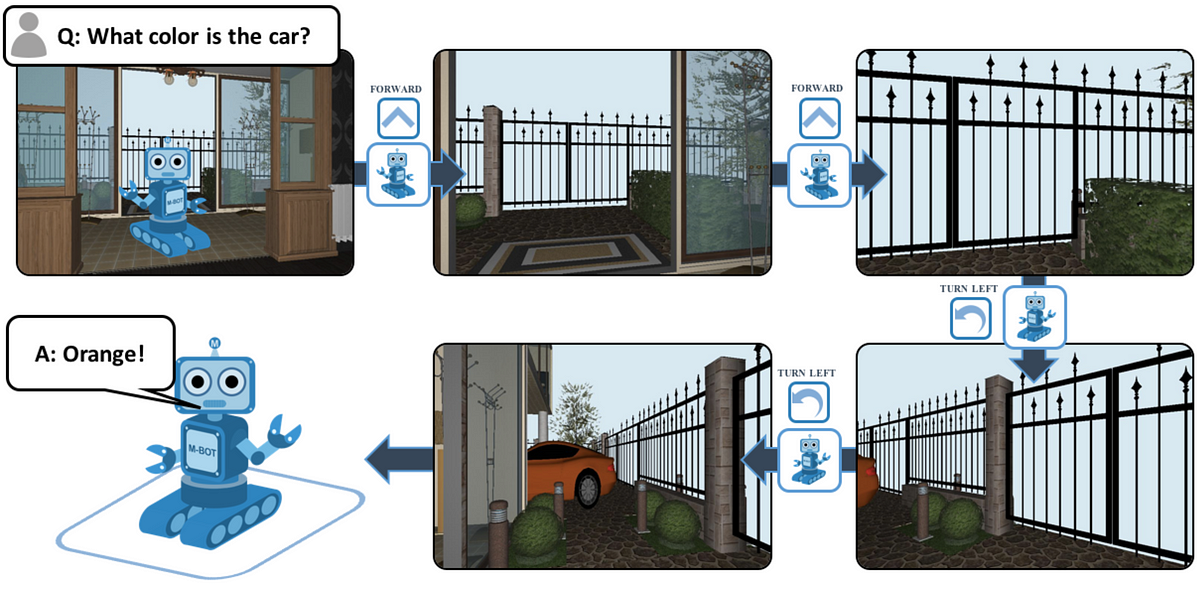
The goal in this example is to find the find the car and perceive its color. It needs to understand the question, find the car, and then answer.
Active Perception
The agent may be spawned anywhere in the environment and may not immediately ‘see’ the pixels containing the answer to its visual goal (i.e. the car/goal may not be visible). Thus, the agent must move to succeed — controlling the pixels that it will perceive. The agent must learn to map its visual input to the correct action based on its perception of the world, the underlying physical constraints, and its understanding of the question. The observations that the agent collects are a consequence of the actions that the agent takes in the environment. The agent is controlling the data distribution that is coming in. The agent controls the pixels it gets to see. This is unlike static datasets, which have been curated online and there’s less control over viewpoint variations of objects, etc. One of the challenges of active perception is to be generally robust to visual variation.
Sparse Rewards
Unlike object detection or image recognition (supervised learning), these agents do collect immediate rewards for each action. Agents in an environment often experience sparse rewards (reinforcement learning). The aim of a reinforcement learning (RL) algorithm is to allow an agent to maximize the rewards from the environment. In some environments, the rewards are supplied to the agent continuously. In others, a positive reward is only provided when the agent completes the goal (e.g., “walk to car”), but it leads to sparse rewards. Sparse rewards can make learning the intended behavior more challenging. It can also make exploration more challenging. For more information on Reinforcement Learning, feel free to read our Overview of Reinforcement Learning.
Tasks
There are several tasks that can be accomplished in the field of Embodied AI. Here are some of the existing tasks.
1) Visual Odometry. Odometry is using any sensor to determine how much distance has been traversed, so visual odometry is just clarification that the particular sensor to be used for odometry is visual (e.g., camera). Traversed distance in odometry is relative to the starting position. So visual odometry assumes the initial position is known. Visual odometry (VO), as one of the most essential techniques for pose estimation, has attracted significant interest in both the computer vision and robotics communities over the past few decades. It has been widely applied to various robots as a complement to GPS, Inertial Navigation System (INS), wheel odometry, etc. In the last thirty years, enormous work has been done to develop accurate and robust VO systems.
2) Global Localization. Localization is the problem of estimating the position of an autonomous agent given a map of the environment and agent observations. The ability to localize under uncertainty is required by autonomous agents to perform various downstream tasks such as planning, exploration and navigation. Localization is considered as one of the most fundamental problems in robotics. Localization is useful in many real-world applications such as autonomous vehicles, factory robots and delivery drones. The global localization problem assumes the initial position is unknown (as compared to VO which assumes that the initial position is known). Despite the long history of research, global localization is still an open problem.
3) Visual Navigation. Navigation in three-dimensional environments is an essential capability of robots that function in the physical world (or virtual robots in a simulated environment). Animals, including humans, can traverse cluttered dynamic environments with grace and skill in pursuit of many goals. Animals can navigate efficiently and deliberately in previously unseen environments, building up internal representations of these environments in the process. Such internal representations are of central importance to Artificial Intelligence. For more information on Visual Navigation, feel free to read our Overview of Embodied Navigation. (Coming Soon)
4) Grounded Language Learning. We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research.
5) Instruction Guided Visual Navigation. The idea that we might be able to give general, verbal instructions to a robot and have at least a reasonable probability that it will carry out the required task is one of the long-held goals of robotics, and artificial intelligence. Despite significant progress, there are a number of major technical challenges that need to be overcome before robots will be able to perform general tasks in the real world. One of the primary requirements will be new techniques for linking natural language to vision and action in unstructured, previously unseen environments. It is the navigation version of this challenge that is referred to as Vision-and-Language Navigation (VLN).
6) Embodied Question Answering. EmbodiedQA is where an agent is spawned at a random location in a 3D environment and asked a question (e.g., ‘What color is the car?’). In order to answer (e.g., ‘Orange!’), the agent must first intelligently navigate to explore the environment, gather information through first-person (egocentric) vision, and then answer the question. This challenging task requires a range of AI skills — active perception (e.g., agent must move to perceive the car — controlling the pixels that it will perceive), language understanding (e.g., what is the question asking?), goal-driven navigation, commonsense reasoning (e.g., where are cars generally located in the house?), and grounding of language into actions (e.g., associate entities in text with corresponding image pixels or sequence of actions).

Egocentric view of embodied agent navigating through a realistic environment.
Datasets and Simulators
Datasets have been a key driver of progress in Internet AI. With Embodied AI, simulators will assume the role played previously by datasets. Datasets consist of 3D scans of an environment. These datasets represent 3D scenes of a house, or a lab, a room, or the outside world. These 3D scans however, do not let an agent “walk” through it or interact with it. Simulators allow the embodied agent to physically interact with the environment and walk through it. The datasets are imported into a simulator for the embodied agents to live in and interact with. With the simulator, the agent can see, move, and interact with its environment. The agent can even speak to other agents or humans with the power of the simulator.
Environments are realized through simulators. However, there are different types of environment representations.
1) Unstructured. An environment can keep everything and maybe compress it. An example of this is Habitat. It will be able to handle long-horizon tasks. This is the predominant model of current environments and usually has metric representations of the environments.
2) Topological. An environment can be represented with a graph of key nodes. Topological environments consist of a graph with nodes corresponding to locations in the environment and a system capable of retrieving nodes from the graph based on observations. The graph stores no metric information, only connectivity of locations corresponding to the nodes. Topological environments allow for navigation strategies, such as “landmark navigation” as opposed to navigating with metric representations.
3) Spatial Memory / Cognitive Map. A mapper can build a spatial map of its environment based on the agent’s egocentric views. The spatial memory captures the layout of the environment. The cognitive map is fused from first-person views as observed by the agent over time to produce a metric/semantic egocentric belief about the world in a top-down view. At each time step, the agent updates the belief of its environment. This allows the agent to progressively improve its model of the environment as it moves around.
Sim2Real
A straightforward way to train embodied agents is to place them directly in the physical world. This is valuable, but training robots in the real world is slow, dangerous (robot can fall over and break), resource intensive (robot and environment demand resources and time), and difficult to reproduce (especially rare edge cases). An alternative is to train embodied agents in realistic simulators and then transferring the learned skills to reality. Simulators can help overcome some of the challenges of the physical world. Simulators can run orders of magnitude faster than real-time and can be parallelized over a cluster; training in simulation is safe, cheap. Once an approach has been developed and tested in simulation, it can be transferred to physical platforms that operate in the real world.

Embodied AI robot can work with fire fighters.
Applications
We want to apply Embodied AI to the real world. We want a physical agent that is capable of taking actions in the real world and can talk to humans with natural language. For instance, a search and rescue scenario. A fire fighter asks: “Is there smoke in any room?” First, the robot has to understand what the question is asking. Then, the language learning and comprehension needs to be grounded in terms of the environment, so that it can understand what it means by “room”. If it the agent is confused or needs assistance, it needs to be able to ask the firefighter what to do. For example, the agent might ask “What subset of rooms are you interested in?” And the firefighter could respond with “The rooms in the burning house.” Or perhaps this particular agent could have learned enough “common sense” to know that the rooms that need to be searched for smoke are the rooms in the burning building. Once the agent understand its objective, it needs to be able to navigate to each room. After it arrives at each room, it needs to be able to comprehend whether there is smoke in the room or not base on its egocentric perception. Finally, it can navigate back to the firefighter and respond: “Yes, in one room.”
This firefighting scenario shows multiple examples of Embodied AI tasks.
Conclusion
Recent advancements in Internet AI have fueled the initial progress of Embodied AI. Once Embodied AI transcends the developments of Internet AI, it will be a major leap forward in enabling robots to effectively learn how to interact with the real world.
Internet AI is only the beginning. Embodied AI will leverage video game technology to fuel the next generation of AI advancements.
Read more about:
BlogsAbout the Author(s)
You May Also Like





.jpeg?width=700&auto=webp&quality=80&disable=upscale)








