


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
In this technical article, originally printed in Game Developer magazine late last year, veteran game programmer Llopis continues his look at data baking by examining how different console and PC game platforms treat data in memory.

[In this technical article, originally printed in Game Developer magazine late last year, veteran game programmer Llopis continues his look at data baking by examining how different console and PC game platforms treat data in memory.]
Baking is often described as precision cooking. Unlike boiling spaghetti or simmering a stew, baking usually requires a very particular ratio of ingredients, precise directions, and an exact time and temperature in the oven. If any of those parts changes, the overall result will be affected, often in not very pleasant ways.
The same is the case with data baking. In last month's column, I covered the basics of data baking, from the time data is exported from the content-creation tool, to the time it makes it into the game.
What I didn't discuss was that different target platforms often have different in-memory formats. If the memory image created by the baking process is off even by a single bit somewhere, the result is usually completely unusable data.
It is possible to bypass the problem completely by baking your data in the target platform. Then all you need to do is load up your data structure and save it to disk. End of story.
That approach might work well for PC games, even when you're doing cross-platform development. If you're developing in Windows, it's pretty easy to involve a Mac or a Linux machine in the baking process.
Although in the case of PC games, the amount of data baking you can do is limited because you hardly ever know the exact hardware your game will run on, so you might not need to involve target machines at all.
If you're developing for game consoles or other fixed platforms, where you definitely want to create the exact memory image of your data, you could consider involving the target platform in the data baking process.
While it is possible to use a game console to build your data, and some games have done that in the past, it's a route fraught with peril and potential for disaster. You're likely to encounter difficulties in automating data builds, poor handling of errors and crashes, slow builds because of underpowered machines, or even just a lack of hardware to build data on.
Whenever possible, stick to using development PCs for data baking. That will give you the fastest and most reliable builds, but you'll need to invest a bit of work to create the exact memory image for your data.
Imagine you're about to bake a structure like this:
struct WaypointInfo
{
int m_id;
bool m_active;
float m_position[3];
char m_letter;
};
It looks like an innocent enough data type, right? Surprisingly, it can have wildly varying sizes and layouts in different platforms (see Figure 1, below). There are three things that will affect its size and layout:
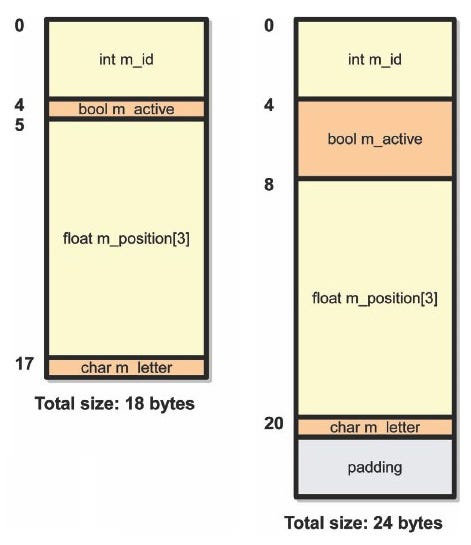
Figure 1: Two possible ways the structure could be in memory.
1. Size of Basic Data Types
How big is an int exactly? Or a bool? The C standard doesn't specify a size for any fundamental data type.
In some platforms ints and floats will be 32 bits, and sometimes they will be 64 bits. You're likely to encounter the inconsistency that a Boolean can sometimes be 32 bits and sometimes 8 bits. That's going to change things!
2. Member Padding
You may think that all members of the structure will be laid out sequentially in memory, and that's almost true. Again, referring to our trusty, if slightly verbose, C standard, we find that members have to be laid out in memory in the same order they were declared in the structure (only if they're within the same public/private/protected block though), but they could have gaps between them.
How big are those gaps? It depends on the platform, compiler, and specific compilation flags. Most often compilers will add padding between member variables to improve performance access to each member variable.
In 32-bit processors, it's faster to load a 32-bit value if it's aligned on a 32-bit boundary, so most compilers will insert enough padding to align it that way.
3. Struct Padding
Figuring out the size of the data types and the amount of padding in between each of them is not enough. Consider this array WaypointInfo m_waypoints[10]; Compilers will often pad structures for performance purposes so that arrays of them will be aligned correctly.
In the example above, if we assume 32-bit integers, 8-bit Booleans, a 3-byte padding, 32-bit floats, and 8-bit characters, we might think the structure is 21 bytes. In reality, it will probably be padded to 24 bytes so subsequent structures in the array will be aligned on a 32-bit boundary. Some compilers might go as far as to pad it to 32 bytes.
What's a poor data baker to do with all those rules?
The varying size of basic data types is often dealt by creating user-defied data types that have a well-defined size. See Listing 1 for an example. In each target platform, you can provide definitions for those data types so their sizes are the same.
Listing 1: Example Data Definition for One Platform
typedef __int64 int64;
typedef signed int int32;
typedef unsigned int uint32;
typedef unsigned short uint16;
typedef unsigned short int16;
typedef unsigned char byte;
Doesn't it seem wasteful that we're all redefining our own data types just so we can know their exact sizes? It gets even worse when middleware providers do the same thing. We end up with many different "basic" data types of varying sizes and properties all over the same code base.
Fortunately, C99 introduced a new header file stdint.h, which among other things, declares integer data types with exact sizes, such as int8_t, uint8_t, int16_t, uint8_t, and so forth.
Do yourself a favor and start using those data types whenever exact size is important. If your compiler isn't yet C99 compliant (tsk, tsk, Visual Studio 2005!), you can get a third-party header file that adds those defines. (See Resources.)
The rules for member and struct padding aren't defined in the C++ standard, so it's completely up to each compiler implementation to decide how to do it. Fortunately, a lot of common compilers (most notably Visual Studio and gcc) support the #pragma pack directive, which allows you to specify the byte alignment desired in your structures.
You can either use #pragma pack everywhere that matters, or you can learn the padding rules for your compiler by implementing those structures and seeing what the compiler creates.
Another common source of problems are bitfields. Using the C language bitfields is very handy to pack flags into a small amount of space:
struct EntityState
{
bool m_active : 1;
bool m_invisible : 1;
bool m_invulnerable : 1;
bool m_playerControlled : 1;
bool m_inVehicle : 1;
// ....
};
The C++ standard guarantees that all those flags will fit in one bit each plus some padding. What it doesn't make any promises about is exactly how those bits will be laid out and or how they will be padded.
You either need to find out how the compiler in your target platform does it, or replace those flags with something you have control over, such as explicit bit masks on a 32-bit unsigned integer.
struct EntityState
{
uint32_t m_flags;
// .....
};
#define ENTITYSTATE_ACTIVE 0x00000001
#define ENTITYSTATE_INVISIBLE 0x00000002
#define ENTITYSTATE_INVULNERABLE 0x00000004
#define ENTITYSTATE_PLAYERCONTROLLED 0x00000008
#define ENTITYSTATE_INVEHICLE 0x00000010
In general, you need to watch out for anything that the standard doesn't explicitly dictate, and that's left up to each implementation.
For each of those cases, you should either substitute it with something that is well defined and consistent, or learn how each implementation defines it and make it part of the rules of your data baking.
Once you've figured out the size of your data types and their offsets in the structure, you still need to know how exactly they're stored in memory. You might know that an integer is 32 bits, but what bit pattern describes a particular number?
There are two parts to that answer. The first one relates to how data types are represented in different hardware. And here, there's good news: Most modern platforms use the same method to represent basic data types.
Signed integers are represented with two's complement, and floating point numbers use the IEEE 754 standard for both 32- and 64-bit numbers (sign, mantissa, and exponent). A few platforms might not support floating point numbers, in which case we'll need to translate the data to fixed point or some other format. But in most cases, this is not something we have to worry about.
That's not the end of the story, though. The second part of the answer relates to how that number is stored in memory. In all modern platforms, a byte (8 bits) is the smallest addressable memory unit. Data types that are just a byte long (like a char) are simply stored at a particular memory address in a single byte, with nothing more to it.
The problem comes with data types that are larger than a single byte. Integers and floats are often 32-bits long, which is 4 bytes. How are those bytes arranged in memory? This is such a fundamental issue that you would hope there were one standard everybody followed. Unfortunately, because of historical reasons, there are two standard ways to do it.
Figure 2A shows the 32-bit integer 0x0A0B0C0D broken down into four bytes. The bit on the far left has the highest potential value (2^31) and is called the most significant bit (msb).
Conversely, the bit on the right has the lowest potential value (2^0) and is called the least significant bit (lsb). Extending this to bytes, the byte containing the lsb is called the least significant byte (LSB) and the one containing the msb is the most significant byte (MSB).
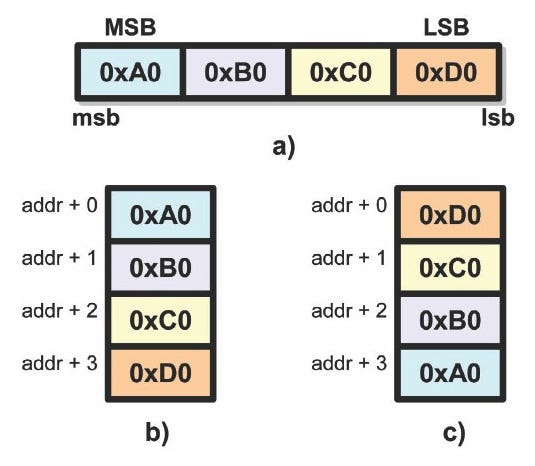
Figure 2 a) 32-bit data in a register. b) Memory layout in big-endian format. c) Memory layout in little-endian format.
One approach, known as the big-endian format, stores bytes in memory starting with the MSB (see Figure 2B). The other approach, little-endian, stores bytes in memory starting with the LSB (see Figure 2C).
The names big-endian and little-endian come from Jonathan Swift's Gulliver's Travels - tensions are high between two rival nations because one cracks its eggs on the big end, and the other cracks them on the little end, and each is convinced that its way is the correct way.
Just like in Gulliver's Travels, both formats make perfect sense depending how you visualize memory and data, and there isn't any advantage to using one over the other.
Some architectures use one and some use the other one; just be aware of which format is used in each of your target platforms and format your data accordingly.
As an example, Intel and AMD-based CPUs use little-endian format, whereas PowerPC CPUs (which include the Microsoft Xbox360, Sony PlayStation 3, and Nintendo Wii) use the big-endian format. Some platforms go as far as being able to switch between the two memory formats.
It's not just the CPU that needs to be little-endian or big-endian. Any hardware that fetches multi-byte data types from memory needs to be aware of the format of that data. Most GPUs can work in either mode for that reason and are customarily set to match the CPU format to keep programmers from going insane.
Data endianness is something that programmers only have to be aware of when sharing binary data between different platforms. You might never have to think about data endianness if you're only developing for a single platform. You really don't care in what order those bytes are stored in memory; you just load them into a register and the CPU takes care of fetching them in the correct order.
An example of a common situation in which data endianness is crucial is network communication. Binary data is transmitted over network packets and might be received by very different platforms.
Fortunately, to allow different machines to communicate with each other and interpret the data in the same way, everybody agreed on a standard network format for binary data-big-endian.
The network sockets API provides a set of standard functions to convert long and short data types between the host format and the network format (htonl, htons, and ntohl, ntohs), which do nothing in hosts with native big-endian format, and swap bytes around in little-endian platforms.
As game developers, the most common situation in which we have to deal with byte-endianness is saving and loading data across multiple platforms.
Whether it's because we're baking data on a little-endian PC and loading it on a big-endian console, or because we want save games to work across a variety of platforms, we need to be very careful how we arrange those bytes.
We could take the same approach as network data and just pick one format and transform the data into that format before saving it. Then, if the target platform uses a different byte-endianness, we could swap the bytes around at load time.
That approach would work, but it would add an extra operation at load time that we could have done ahead of time. So we fold that operation into the data baking process.
When we create the memory image for the data we're baking, we need to compare the byte-endianness of the target platform and the building platform. If they're both the same, we don't need to do anything extra, and we continue baking as usual.
If they're different, we need to rearrange the bytes of every data type larger than one byte. Listing 2 shows a function that swaps the endianness of a piece of data for any data type.
Listing 2: Function for Swapping Endianness
Template < typename T >
T SwapEndianness(T& out, const T& in)
{
const unsigned char* src = reinterpret_cast < const unsigned char* >(&in);
unsigned char* dst = reinterpret_cast < unsigned char* >(&out);
for (int i = 0; i < (int)sizeof(T); ++i)
dst[i] = src[sizeof(T) - 1 - i];
}
[Edit: Eric Bernard pointed out that returning a floating point number by value after swapping its bytes, can be loaded in a floating point register, which can cause it to be re-normalized into a float, slightly changing its precision (and sometimes not so slightly). To avoid that problem, it's important that the resulting value of SwapEndianness is passed as a reference (or pointer) and not returned by value.]
It's useful to note that data endianness is a completely orthogonal concept to the way the data is represented. Both a 32-bit integer and a 64-bit floating point number are going to be stored MSB-first in a big-endian format.
This will make our job a lot easier when converting data for specific platforms because we can first convert the data to the correct representation, then convert them to the right data endinanness, and finally apply any padding rules.
With these new tools in hand, we can now deal with different data sizes, padding, and byte-endianness and create perfect data memory images for just about any platform. Happy baking!
Msinttypes
http://code.google.com/p/msinttypes
C++ standard
Required reading for low-level C++ issues
www.open-std.org/jtc1/sc22/wg21/docs/projects
Read more about:
FeaturesYou May Also Like





