


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Computer Systems Science student and educational game designer and programmer Ville Mönkkönen discusses his views on development of game engines for multicore platforms,including game engine parallelism on an architecture level.

Even though multicore processors have been available for the PC for well over a year, and the Xbox 360 has already sold millions, there is still a lack of knowledge regarding the development of game engines for multicore platforms. This article will attempt to provide a view to game engine parallelism on an architecture level.
As shown by Gabb and Lake[1], instead of looking at multithreading on the level of individual components, we can find better performance by looking for ways to add parallelism to the whole game loop. We will be looking at three different threading supported architecture models for the basic game loop, and comparing them with regards to qualities such as scalability, and expected performance.
There are two main ways to break down a program to concurrent parts: function parallelism, which divides the program to concurrent tasks, and data parallelism, which tries to find some set of data for which to perform the same tasks in parallel. Of the three compared models, two will be function parallel, and one data parallel.
One way to include parallelism to a game loop is to find parallel tasks from an existing loop. To reduce the need for communication between parallel tasks, the tasks should preferably be truly independent of each other. An example of this could be doing a physics task while calculating an animation. Figure 1 shows a game loop parallelized using this technique.
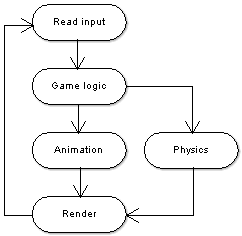
Figure 1. A game loop parallelized using the synchronous function parallel model. The animation and the physics tasks can be executed in parallel.
Costa[2] presents a way to automate the scaling of this kind of an architecture. The idea is to divide the functionality to small tasks, build a graph of which tasks precede which task (such as the graph in Figure 1), then supply this task-dependency graph to a framework. The framework in turn will schedule the proper tasks to be run, minding the amount of available processor cores. The alternative to using such a framework is to rewrite parts of your code for each core amount you plan to support.
One major concern with both the function parallel models is that they have an upper limit to how many cores they can support. This is the limit of how many parallel tasks it is possible to find in the engine. The number of meaningful tasks is decreased by the fact that threading very small tasks will yield negligible results. The synchronous function parallel model imposes an additional limit – the parallel tasks should have very little dependencies on each other. For example it is not sensible to run a physics task in parallel with a rendering task if the rendering needs the object coordinates from the physics task.
The expected performance of the model can be directly seen from the length of the longest path of execution in the game loop. The length of this path of execution is directly tied to the amount of parallelism in the loop. As this model generally allows the least amount of parallelism of the three models, the same can be expected from the model's performance.
As the synchronous function parallel model assumes there are very few connections between tasks that run in parallel, existing components do not require many changes. For example if running the physics component update is a task that can be run concurrently with the sound mixer, neither component needs special support to operate.
Gabb and Lake propose an alternative function parallel model. The difference is that this model doesn't contain a game loop. Instead, the tasks that drive the game forward update at their own pace, using the latest information available. For example the rendering task might not wait for the physics task to finish, but would just use the latest completed physics update. By using this method it is possible to efficiently parallelize tasks that are interdependent. Figure 2 shows an example of the asynchronous function parallel model.
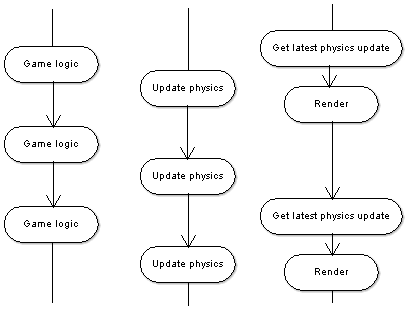
Figure 2. The asynchronous function parallel model enables interdependent tasks to run in parallel. The rendering task does not wait for the physics task to finish, but uses the latest complete physics update.
As with the synchronous model, the scalability of the asynchronous function parallel model is limited by how many tasks it is possible to find from the engine. Fortunately the communication between threads by only using the latest information available effectively reduces the need for the threads to be truly independent. Thus we can easily have a physics task run concurrently with a rendering task – the rendering task would use a previous physics update to get the coordinates for each object. Based on this, the asynchronous model can support a larger amount of tasks, and therefore a larger amount of processor cores, than the synchronous model.
As Gabb and Lake point out, communication between tasks in this model presents an intriguing problem with timing – a problem that the other models don't have. Suppose there are three tasks that work concurrently, an input tasks, a physics task that uses input to move game objects, and a rendering task that uses physics results to draw the objects. Optimally the input task would complete just before the physics task starts, which would complete just before the rendering task starts. In the worst case scenario the rendering would start just before the physics task is complete, and the physics task would start just before the input task is complete. This would result in a input-to-display time of roughly two times of the optimal scenario, and the time would fluctuate between the optimal and the worst on each frame. Gabb and Lake suggest a remedy of calibrating some tasks to run more often than others, such as having the input task run twice more often than the physics task. This may help alleviate the problem, but it will not eliminate it.
Since the asynchronous model assumes little or no synchronization between the concurrent tasks, the performance of the model is not limited as much by the serial parts of the program. Therefore the main performance limitation comes from the ability to find enough useful parallel tasks. The thing to keep in mind here is that the tasks should be well balanced - having one large task and several very small ones could signify a performance bottleneck.
Since the asynchronous model relies heavily on tasks not directly connecting to each other, but on communication using the last available information, there may be changes needed for current components to function on this model. At the very least each component needs a thread safe way to inquire the latest state update. Such changes should be easy enough to make, and they can even be added as an additional wrapper layer to the component.
In addition to finding parallel tasks, it is possible to find some set of similar data for which to perform the same tasks in parallel. With game engines, such parallel data would be the objects in the game. For example, in a flying simulation, one might decide to divide all of the planes into two threads. Each thread would handle the simulation of half of the planes (see Figure 3). Optimally the engine would use as many threads as there are logical processor cores.
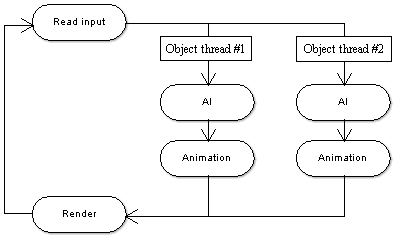
Figure 3. A game loop using the data parallel model. Each object thread simulates a part of the game objects.
An important issue is how to divide the objects into threads. One thing to consider is that the threads should be properly balanced, so that each processor core gets used to full capacity. A second thing to consider is what will happen when two objects in different threads need to interact. Communication using synchronization primitives could potentially reduce the amount of parallelism. Therefore a recommended plan of action is to use message passing accompanied by using latest known updates as in the asynchronous model. Communication between threads can be reduced by grouping objects that are most likely to interact with each other. Objects are more likely to come into contact with their neighbors, so one strategy could be to group objects by area.
The data parallel model has excellent scalability. The amount of object threads can be automatically set to the amount of cores the system is running, and the only non-parallelizable parts of the game loop would be ones that don't directly deal with game objects (Read input and Render tasks in Figure 3). While the function parallel models can still get the most out of a few cores, data parallelism is needed to fully utilize future processors with dozens of cores.
The performance of the data parallel model is directly related to how large a part of the game engine can be parallelized by data. As the amount of processor cores goes up, the data parallel parts of the engine take less time to run. Fortunately these are usually also the performance heavy parts of a game engine. If an engine can use data parallelization for most parts of the game loop, then the data parallel model will give the best performance of the three models.
The biggest drawback of the model is the need to have components that support data parallelism. For example, a physics component would need to be able to run several physics updates in parallel, and be able to correctly calculate collisions with objects that are in these separate threads. A potential solution is to leave the physics calculation completely out of the data parallel part of the game loop, and use internal parallelization in the physics component. Fortunately many other components won't need extensive changes. For example a component calculating the animations of graphical objects has no interaction between concurrent threads, and won't need any special support for parallelism.
Because the synchronous function parallel model does not require special changes to engine components, and is really just an enhancement of a regular game loop, it is well suited for adding some amount of parallelism to an existing game engine. The model is not suited for future use because of it's weak scaling support and low amount of parallelism.
The asynchronous function parallel model can be recommended for new game engines because of the high amount of possible parallelism and the fact that existing components need only few changes. This model is a good choice for game engines aimed at the generation of multicore processors that have a relatively small number of cores. The only drawback is the need to tune thread running times to minimize the impact of worst case thread timings. More research is needed to know how this timing fluctuation actually affects game play.
The data parallel model is definitely something to think about for the future. It will be needed when the amount of processor cores increases beyond the number of tasks available for a function parallel model. For current use the increased scalability doesn't offer enough benefits compared to the trouble of coding custom components to support this type of data parallelism.
The current trend seems to be towards creating engine components that use some internal form of parallelization. While this allows engine developers to not worry about threading issues, it may leave large parts of the program sequential, which results in poor performance. The view presented in this article has been that whole game loops could be parallelized, not just some parts of them. The models presented here can be a good starting point for developing specialized game engine architectures.
[1] Gabb H., Lake A. 2005. Threading 3D Game Engine Basics. http://www.gamasutra.com/features/20051117/gabb_01.shtml
[2] Costa S. 2004. Game Engineering for a Multiprocessor architecture. MSc Dissertation Computer Games Technology. Liverpool John Moores University.
Wilson K. 2006. Managing Concurrency: Latent Futures, Parallel Lives. http://www.gamearchitect.net/Articles/ManagingConcurrency1.html
Read more about:
FeaturesYou May Also Like





