

Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Managing D3D12 Resource Lifetimes
Managing resource lifetimes in Direct3D12 may be an issue as CPU and GPU run in parallel, and application has to make sure that all resources are valid by the time GPU uses them. This article presents a strategy to deal with this problem.
12 Min Read

Introduction
In a typical Direct3D application, CPU and GPU run in parallel, with GPU falling behind CPU by few frames. This means that when CPU issues a rendering command, the command does not get executed immediately, but added to the GPU command buffer instead, and the GPU will run this command some time later. At this time, all resources associated with the command must still be valid and in the correct state. In D3D11, this was ensured by the system. So, for instance, a buffer may be released right after it was bound as shader resource, and D3D11 will make sure that actual resources associated with the buffer object are only released after draw command is finished. In D3D12, however, this is responsibility of the application. Lifetimes of the following resources must properly managed by D3D12 application:
Resources (textures and buffers)
Pipeline states
Descriptor heaps and allocations within descriptor heaps
Not only descriptor heap itself must be alive when command is executed by the GPU, but all descriptors that draw command references must be valid
Command lists and allocators
Dynamic upload heap
Basic Strategy
The main tool for synchronizing CPU and GPU execution that D3D12 system provides is fence. The fence can be thought of as a milestone in GPU execution. The CPU may command GPU to signal the fence (see ID3D12CommandQueue::Signal()), and this command will be added to the command buffer along with all other commands. When GPU reaches this point, it sets the specified value. CPU can request the current value (see ID3D12Fence::GetCompletedValue()) to understand where GPU execution is at this moment. Diligent Engine tracks number of command lists executed by the GPU. Every time next command list is submitted to the command queue, the engine signals the next value. The engine maintains m_NextCmdList variable that contains 0-based ordinal number of the command list that will be submitted next. The engine also maintains a fence whose value is the total number of completed command lists (rather than ordinal number of the last submitted command list). The following code snippet shows operations that engine performs when next command list is submitted to the queue:
std::lock_guard<std::mutex> LockGuard(m_CmdQueueMutex); // Submit the command list ID3D12CommandList *const ppCmdLists[] = {pCmdList}; m_pd3d12CmdQueue->ExecuteCommandLists(1, ppCmdLists); // Increment the counter before signaling the fence. SubmittedCmdListNum = m_NextCmdList; Atomics::AtomicIncrement(m_NextCmdList); // Signal the fence value. m_pd3d12CmdQueue->Signal(m_pCompletedCmdListFence, m_NextCmdList);
Note that all operations must be atomic and thus protected by a mutex. Also note that the next command list number is first incremented and then used to signal the fence. Consider submitting the first command list (ordinal number 0). This is the very first command list, so it is completed when one command list is executed, so we should signal 1 in the queue. The following figure illustrates CPU and GPU timelines and associated values:
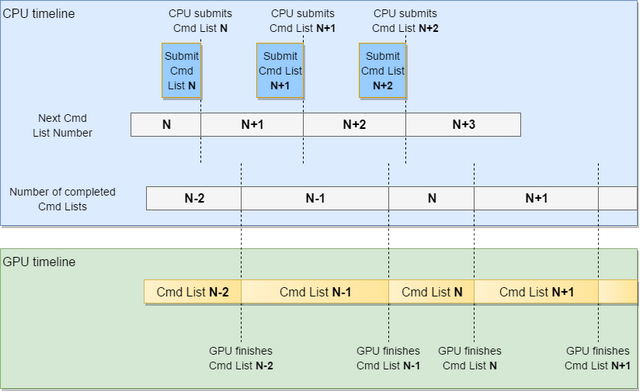
Notice that the number of completed command lists is one greater than the last completed cmd list, and is also equal to the ordinal number of the cmd list currently been executed by the GPU. Also note that though command lists can be submitted to the command queue from several threads (which is not expected), the engine serializes access to the command queue, so that only single thread can submit command list and atomically update the next cmd list number.
The engine uses the same strategy to recycle all types of resources. When resource is released by the app, it is not destroyed immediately, but added to the release queue along with the next command list number. There are different queues for different types of resources. The queues are purged once or several times during the frame and only these objects that belong to completed command lists are actually destroyed. This strategy works given the following basic requirement is met:
a resource is never released before the last draw command referencing it is invoked on the immediate context.
For immediate context, this is a natural requirement. A resource can be released right after a draw command was called, and the engine will keep it alive until it can be safely released. For a deferred context, however, this means that all resources must be kept alive until command list from this deferred context is executed by the immediate context. Deferred context does not keep references to the resources, so this is responsibility of the application.
The basic requirement above guarantees that the command list number that is paired with the resource in the release queue is at least the command list number where the resource was last referenced (but may be greater). Consider the following example where a buffer is released right after a draw command that references it:
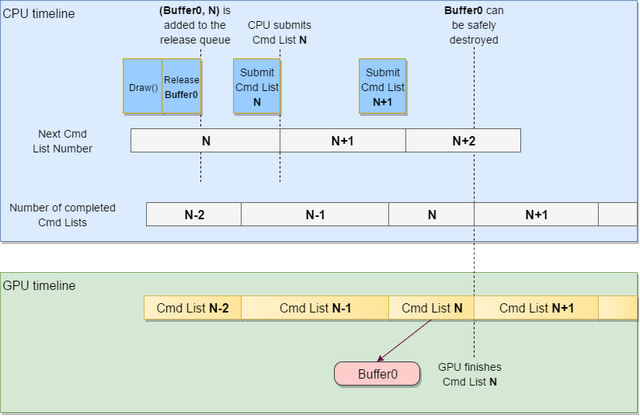
Note that after cmd list N is completed by the GPU, the Direct3D12 buffer resource will not be released immediately, but rather when the corresponding queue is purged next time. Also note that the buffer object can be released by another thread. As long as the basic requirement that the last draw command is executed before the resource is released is met, the resource can safely be destroyed by another thread.
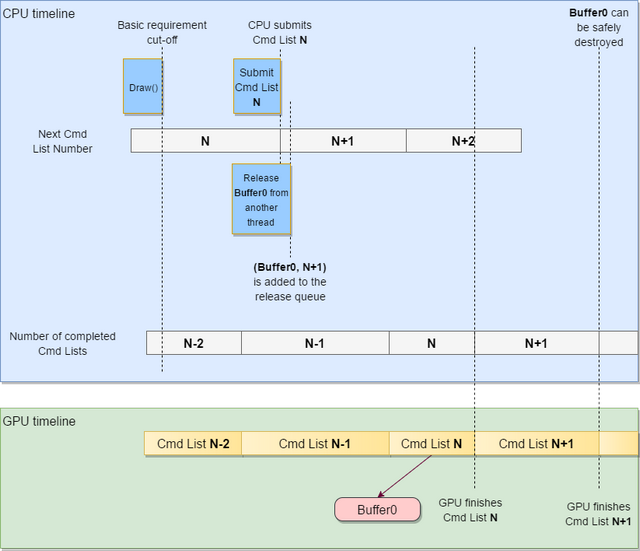 Note that in the example above, the buffer reference is paired with N+1 in the release queue, so the buffer will be released little later that it potentially could have been. In a multithreaded environment, the buffer may be paired with any arbitrary number, but the basic requirement guarantees that when release procedure is invoked, next cmd list number is at least N, and N only grows. As a result, the buffer reference will be paired with at least N, and consequently, the buffer can only be destroyed after cmd list N is completed. It may be destroyed later, but never earlier, which provides correctness guarantee.
Note that in the example above, the buffer reference is paired with N+1 in the release queue, so the buffer will be released little later that it potentially could have been. In a multithreaded environment, the buffer may be paired with any arbitrary number, but the basic requirement guarantees that when release procedure is invoked, next cmd list number is at least N, and N only grows. As a result, the buffer reference will be paired with at least N, and consequently, the buffer can only be destroyed after cmd list N is completed. It may be destroyed later, but never earlier, which provides correctness guarantee.
Resource Lifetime Management Details
This section briefly talks about specific details of managing lifetimes of different types of resources.
Buffers, Textures, and Pipeline States
Render device maintains single queue for D3D12 buffers, textures, and pipeline states:
typedef std::pair<Uint64, CComPtr<ID3D12Object> > ReleaseQueueElemType; std::deque<ReleaseQueueElemType> m_D3D12ObjReleaseQueue;
When an objects is destroyed, its destructor calls SafeReleaseD3D12Object() method of the render device to add its internal D3D12 resource to the release queue:
BufferD3D12Impl :: ~BufferD3D12Impl() { // D3D12 object can only be destroyed when it is no longer used by the GPU GetDevice()->SafeReleaseD3D12Object(m_pd3d12Resource); }
Temporary resources that are used to upload initial data to textures and buffers are recycled in a similar way. Render device adds the resource along with the next command list number into the queue:
void RenderDeviceD3D12Impl::SafeReleaseD3D12Object(ID3D12Object* pObj) { std::lock_guard<std::mutex> LockGuard(m_ReleasedObjectsMutex); m_D3D12ObjReleaseQueue.emplace_back( GetNextCmdListNumber(), CComPtr<ID3D12Object>(pObj) ); }
Note that in a multithreaded environment, the value returned by GetNextCmdListNumber() can potentially be arbitrary, but if basic requirement is met, it will never be smaller than the number of the last command list that references that resource (see diagram above).
The queue is purged once at the end of each frame:
void RenderDeviceD3D12Impl::ProcessReleaseQueue(bool ForceRelease) { std::lock_guard<std::mutex> LockGuard(m_ReleasedObjectsMutex); auto NumCompletedCmdLists = GetNumCompletedCmdLists(); // Release all objects whose cmd list number value < number of completed cmd lists while (!m_D3D12ObjReleaseQueue.empty()) { auto &FirstObj = m_D3D12ObjReleaseQueue.front(); // GPU must have been idled when ForceRelease == true if (FirstObj.first < NumCompletedCmdLists || ForceRelease) m_D3D12ObjReleaseQueue.pop_front(); else break; } }
Descriptor Heaps
Diligent Engine contains four CPU descriptor heap objects, and two GPU descriptor heap objects, as described in this page. Every descriptor heap object contains one or several descriptor heap allocation managers. Every descriptor heap allocation manager, in turn, relies on variable size GPU allocations manager to perform suballocations within allotted space. Every allocations manager maintains its own release queue that contains command list number along with the allocation attributes. The queues work in a similar manner to resource release queues and as long as the basic requirement is met, descriptor heap deallocation is safe and correct.
The queues are purged once at the end each frame by the render device.
Dynamic descriptors
Dynamic descriptors are allocated by DynamicSuballocationsManager class (see Managing Descriptor Heaps). The class requests descriptors in chunks from the main GPU descriptor heap as needed. When command list from this context is closed and executed, all dynamic allocations are discarded:
pCtx->DiscardDynamicDescriptors(SubmittedCmdListNum);
At this point, all dynamic chunks are added to the release queue of the corresponding allocations manager, which are recycled at the end of each frame.
NOTE: since all dynamic allocations are recycled every frame, all dynamic descriptors (including allocated in deferred contexts) cannot be used across several frames and must be released before the end of the current frame. In practice this means that deferred context cannot record commands for several frames and must be closed and executed within the same frame it was started in.
Upload Heaps
Dynamic Upload Heap is used by the engine to allocate temporary space need to update the contents of the resource or to provide storage for dynamic buffers. The upload heap is described in this post and uses ring buffer. At the end of every frame, current ring buffer tail is added to the release queue along with the next command list number. Also, all stale tails belonging to previous frames are released.
NOTE: since all space is recycled every frame, all dynamic space (including allocated in deferred contexts) cannot be used across several frames and must be released before the end of the current frame. In practice this means that all dynamic buffers must be unmaped in the same frame and all resources must be updated within boundaries of a single frame.
Command Lists
Command lists and allocators are never destroyed, but reused. When command list is submitted for execution, its associated D3D12 Command List object as well as command list allocator are added to the end of the queue along with the next command list number. When new command list is requested, allocators and command lists from the beginning of the queue are fist examined. If they refer to already completed command list, they are reused. Otherwise a new command list object is created.
Submitting Command List to the Command Queue
The following listing presents a function that runs every time a command list is submitted to the queue. The functions goes through the following steps:
Increments next command list number (m_NextCmdList) and signals incremented value from GPU
Discards allocator used to create D3D12 command list
Discards all dynamic descriptors used by this context
Returns the contexts to the pool of available contexts
void RenderDeviceD3D12Impl::CloseAndExecuteCommandContext(CommandContext *pCtx) { CComPtr<ID3D12CommandAllocator> pAllocator; auto *pCmdList = pCtx->Close(&pAllocator); Uint64 SubmittedCmdListNum = 0; { std::lock_guard<std::mutex> LockGuard(m_CmdQueueMutex); // Kickoff the command list ID3D12CommandList *const ppCmdLists[] = {pCmdList}; m_pd3d12CmdQueue->ExecuteCommandLists(1, ppCmdLists); // Increment the counter before signaling the fence. SubmittedCmdListNum = m_NextCmdList; Atomics::AtomicIncrement(m_NextCmdList); // Signal the fence value. Note that for cmd list N that has just been submitted, // we are signaling value N+1, that has a meaning of the TOTAL NUMBER OF COMPLETED // cmd lists rather than the index number of the LAST completed cmd list. m_pd3d12CmdQueue->Signal(m_pCompletedCmdListFence, m_NextCmdList); } m_CmdListManager.DiscardAllocator(SubmittedCmdListNum, pAllocator); pCtx->DiscardDynamicDescriptors(SubmittedCmdListNum); { std::lock_guard<std::mutex> LockGuard(m_ContextAllocationMutex); m_AvailableContexts.push_back(pCtx); } }
Finishing Frame
Another set of operations is performed at the end of every frame, as show in the listing below:
All allocations from upload heaps are discarded
All stale allocations from all descriptor heaps are released
All stale D3D12 resources are destroyed
void RenderDeviceD3D12Impl::FinishFrame() { auto NumCompletedCmdLists = GetNumCompletedCmdLists(); { std::lock_guard<std::mutex> LockGuard(m_UploadHeapMutex); for (auto &UploadHeap : m_UploadHeaps) UploadHeap->FinishFrame(GetNextCmdListNumber(), NumCompletedCmdLists); } for(Uint32 CPUHeap=0; CPUHeap < _countof(m_CPUDescriptorHeaps); ++CPUHeap) m_CPUDescriptorHeaps[CPUHeap].ReleaseStaleAllocations(NumCompletedCmdLists); for(Uint32 GPUHeap=0; GPUHeap < _countof(m_GPUDescriptorHeaps); ++GPUHeap) m_GPUDescriptorHeaps[GPUHeap].ReleaseStaleAllocations(NumCompletedCmdLists); ProcessReleaseQueue(); Atomics::AtomicIncrement(m_CurrentFrameNumber); }
Conclusion
Resource lifetime management system in Diligent Engine requires applications to follow few rules:
A resource is never released before the last draw command referencing it is invoked on the immediate context
For deferred contexts this means that no resources can be released until a command list from that deferred context is sent for execution
All dynamic descriptors (including allocated in deferred contexts) are released before the end of the current frame
A deferred context cannot record commands for several frames and must be closed and executed within the same frame it was started in
All dynamic space (including allocated in deferred contexts) is released before the end of the current frame.
All dynamic buffers must be unmaped in the same frame and all resources must be updated within boundaries of a single frame
Following these rules allows implementing low-overhead resource lifetime management system that ensures all resources are valid and in correct state when GPU commands referencing them are executed.
Related Articles on Diligent Engine Architecture
Efficient Implementation of Dynamic Resources in Direct3D12
Shader resource binding model in Diligent Engine 2.0
Lightweight variable-size memory block allocator
Efficient D3D12 Descriptor Heap Management System
Visit Diligent Engine on the Web, follow us on Twitter, and Facebook.
Read more about:
BlogsAbout the Author(s)
You May Also Like





