


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Following on from his <a href=http://www.gamasutra.com/features/20070419/garcia_01.shtml>first feature</a> on the subject, Pyro Studios tech lead Jesus de Santos Garcia discusses how to organize game code so that data will be loaded as swiftly as possible.
May 3, 2007

Author: by Jesus de Santos Garcia
In the previous article on Fast File Loading, I described techniques directly related with the hardware and the operating system to load files in the most efficient way. In this one, a technique for organizing the data to be loaded as fast as possible is described. Basically, we are going to load data without doing any parsing at all. Although the techniques described here are oriented towards real-time applications, any application could use them to accelerate its load times.
The implementation and all the samples shown here can be found in a project that you can download. It is a project for Microsoft Visual Studio 8.0 and it has been tested under a 32-bit architecture. Extensions to other compilers and other architectures should be easy to add. This code must be taken as a proof of concept and not as a solid and robust implementation ready to be used in a project. I have tried to isolate the dependencies with other systems so that you can concentrate in the topic of this article.
1. Load-In-Place (aka Relocatable Data Structures)
The basic philosophy under Load-In-Place is “preprocess as much as possible“: do not waste CPU ticks with operations that can be done offline, do not waste CPU ticks so that the the loading process can run in parallel without interfering with your main process.
Imagine that you could load your data with a simple fread() from a file. Without doing any parsing at all. This is basically what we are going to try to do without modifying the structures we usually have.
If we had, for example, a data file with a vector of floats, loading with this philosophy in mind would be as simple as memcpying the file to memory and pointing a float* to the beginning of the memory buffer. And that would be all. We would have our data ready for being used.
For simple structures that would be enough but this simplicity disappears when we start to use more complex structures in C++:
Pointers: it is usual to have pointers embedded in the data. Pointers can not be saved to disk without a proper management. And when you load those pointers they have to be relocated properly.
Dynamic Types: a pointer to a type T doesn’t imply that the dynamic type is T. With polymorphism we have to solve the problem of loading/saving the proper dynamic type.
Constructors: objects in C++ have to be properly constructed (invoking one of its constructors). We wouldn’t have a generic enough implementation if we didn’t allow object construction. Constructors are used by the compiler to create internal structures associated to a class like vtables, dynamic type info, etc.
Basically, what we want is a system being able to take a snapshot of a memory region and to save it to disk. Later, when loading the block, we need the system to make the proper adjustments to have the data in the same state that it was before saving. The mechanisms described here are very similar to those used by the compilers to generate modules (executables, static libraries, dynamic libraries) that later have to be loaded by the OS (relocating the pointers for example).
With this technique, native hardware formats are loaded by the runtime. This may imply a redesign of your data pipeline. A good approach is having a platform-independent format that is processed for each platform giving a native format that is loaded-in-place. This is the same procedure that is followed when generating binaries (executables, libraries). So it may be a good idea to unify this because now code and data are all the same.
2. Implementation Details
The class SerializationManager is in charge of loading/saving objects to/from file. Basically you have a function for saving where you pass a pointer to a root object and a function for loading with the same parameters. The root class has to satisfy some requirements for being serialized. The implementation is designed to be as less intrusive as possible. It means that you can design the classes as you wish. To make a class in-placeable you have to implement 2 functions for each class you want to save:
CollectPtrs(): This function is used when saving. In this function you collect all the pointers and continue gathering recursively.
In-Place Constructor(): this function is used when loading. There is a special constructor for Load-In-Place where you relocate the pointers. It is a good idea not having default constructors in the classes you want to in-place. That way default constructors are not silently called if you forget to call the in-place constructor.
The SerializationManager traverses the pointers starting from the root object looking for contiguous memory blocks. When all the contiguous memory blocks are localized, the pointers are adjusted to become an offset from the beginning of the block. When loading, those pointers are relocated (the stored offset is relative to the beginning of the block) and initialized (each pointer is only initialized once) using the placement syntax of the new operator:
// Class constructor is called but no memory is reserved Class *c = new(ptr) Class();
Let’s see a simple example:
class N0;
class N1;
class N2;
class N3;
class N3
{
public:
float a, b, c;
N3() {}
N3(const SerializationManager &sm) {}
void CollectPtrs(SerializationManager &sm) const {}
};
class N0
{
public:
N2 *n2;
N1 *n1;
N0() {}
N0(const SerializationManager &sm)
{
sm.RelocatePointer(n2);
sm.RelocatePointer(n1);
}
void CollectPtrs(SerializationManager &sm) const
{
sm.CollectPtrs(n2);
sm.CollectPtrs(n1);
}
};
class N2
{
public:
N2() {}
N1 *n1;
N3 *n3;
N2(const SerializationManager &sm)
{
sm.RelocatePointer(n1);
sm.RelocatePointer(n3);
}
void CollectPtrs(SerializationManager &sm) const
{
sm.CollectPtrs(n1);
sm.CollectPtrs(n3);
}
};
class N1
{
public:
float val;
N2 n2;
N1() {}
N1(const SerializationManager &sm): n2(sm) {}
void CollectPtrs(SerializationManager &sm) const
{
sm.CollectPtrs(n2);
}
};
With the above class definitions we serialize the following instances:
N0 n0;
N1 n1;
N3 n3;
n1.val = 1.0f;
n0.n1 = &n1;
n0.n2 = &n1.n2;
n0.n2->n1 = n0.n1;
n0.n2->n3 = &n3;
manager.Save(”raw.class”, n0);
This is a graphical representation of how the In-Place process would be applied to this sample:
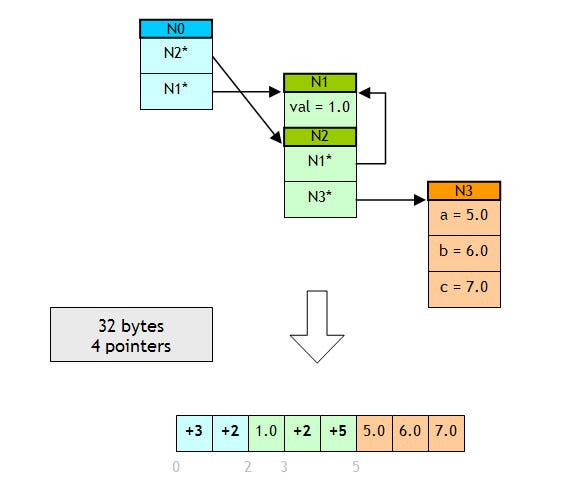
To save classes in this way, you need to add to them the two functions described above. This intrusive method doesn’t allow, for example, saving STL containers. To solve this problem (and probably to avoid dependencies with a specific STL implementation) you probably will need to develop your own in-placeable containers. I have included in the sample project, a Vector and StaticVector implementation.
Polymorphic classes need to be initialized in a different way. For these classes, I am using an object factory that assign an unique ID to each class. When saving this classes to disk, the ClassID is written in the vtable position (4 bytes at the beginning of the class in most of the compilers). This is a sample of a Vector of polymorphic objects:
Vector renderables(4);
renderables[0] = new Sphere(10.0f);
renderables[1] = new Cube(10.0f);
renderables[2] = 0;
renderables[3] = new Mesh(5000);
manager.Save(”raw.class”, renderables);
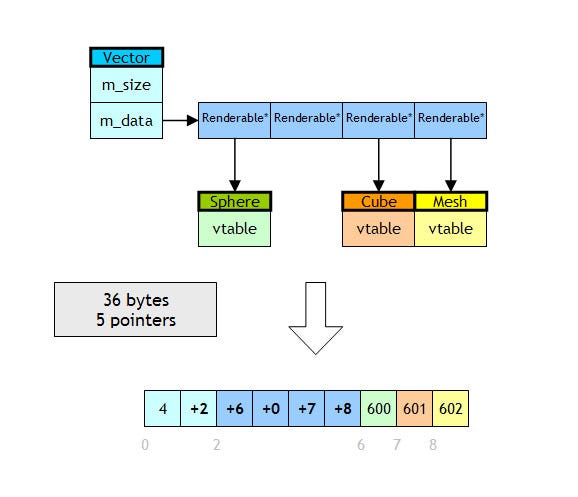
As you can see in the example above, null pointers needn’t be treated in a special way. A 0 is written to disk.
One last point about memory management. When you load-in-place classes using the SerializationManager, you receive a pointer to the root class inside a Resource class instance (that acts like a smartpointer) holding the raw memory allocated. When finishing using that Resource, you should Release() it. When Releasing() a Resource, destructors for the classes in the tree are not invoked. That way, you can use the destructor to free the memory when the class is used in a normal way (not being loaded in-place). When the class in loaded in-place, it shouldn’t free the memory because it has not been allocated by itself.
Resource > renderablesRS;
manager.Load(”raw.class”, renderablesRS);
// Use renderablesRS
// …
renderablesRS.Release();
3. Efficiency
All the complex operations happens when saving. I will concentrate on the loading phase. Loading In-Place basically consists of two parts: loading the entire file to memory (a relatively long I/O operation) and relocating the pointers through the Load-In-Place constructor (a relatively short CPU operation). Pointers are relocated adding the address of the memory block and constructing the object if it has not been previously constructed. Constructing the object is doing a placement new or invoking the factory (through a virtual function) if the object is polymorphic.
All the critical SerializationManager functions are templatized and they will be properly inlined in Release configurations. At the end, you can expect a quality code very similar (if not faster) to what you would have written manually.
For example, loading a vector of 3d points (a simple struct with 3 floats) generates the optimal code (just a simple fread()) when it is compiled in release configuration and all the code is inlined (all the relocation code disappears).
Pointer relocation can be considered a very fast operation in comparison to reading the data from file. So, at the end, the Load In-Place operation is heavily dominated by an I/O operation leaving the CPU free for other resources. In my examples, the relocation phase is always under 0.1% (with relatively small files, bigger files will go below this) of the total time. Rest of the time is for the I/O phase.
There is one more thing to consider about efficiency. With Load-In-Place, you will have less memory fragmentation because lots of objects are placed in a contiguous memory block.
4. A more realistic scenario
Having finished with all the tests to implement Load-In-Place I decided to take a real scenario from an old project I had in my source control repository. In that project, I had code to load/save a typical realtime mesh representation: list of materials, list of vertices, normals, binormals, tangents, text coords channels, color channels, etc.
The code for that part is included in the sample 8 of the project. That sample creates a mesh with 1000 vertices (randomly filled) with all the attributes and 2 text coord channels. Two fictitious materials are added to the mesh.
In total, 80186 bytes are written to disk and 15 pointers are relocated. The relocation phase in this sample is under 0.03% of the total time in my machine. With this new method for loading the application started to load a lot faster. But that is not all, there is a opened door for implementing loading in a background thread now that the loading process is an almost 100% I/O operation. I will talk about this in future articles.
5. Ideas for the future
These are possible ways to improve the simple implementation given within this article:
Integration with a class reflection system. Instead of implementing a function to save a class (like the CollectPtrs() one), you implement a description of the class. Using that description not only you can save the class (generating automatically the CollectPtrs implementation), you can for example edit it in realtime, you can edit classes saved to disk, you can detect when a class saved to disk is not the same that the one you have in runtime and do a proper transformation (automatic class versioning). A reflection system deserves an own article.
As you cannot use the STL library, you will have to implement all the containers and algorithms that you need. Probably you will want to expose the same interface as STL so that the clients of this system doesn’t have to learn a new (and not standard) API.
A packaging system where you can pack and unpack several object trees into one file would be really useful if you start to use this system in a serious project.
Support for external references. In this article, only internal pointers are treated. External pointers (pointers to objects located outside the file) are needed to reference external resources.
Probably you will need a more sophisticated method to detect when you want to save an object polymorphically or not. In the example given, all the classes derived from BaseObject are treated polymorphically. The exception here are arrays. Arrays of objects are never treated polymorphically.
With the system described here and with little modifications, you can easily move objects in memory. It is a similar process to the one for loading from file. A system that defragments the memory moving objects can be easily implemented this way.
Support for multiple inheritance. The implementation given here doesn’t support multiple inheritance. You will probably want support for multiple inheritance when using interfaces (implementing several interfaces in the same class).
6. Conclusion
A technique for loading data without parsing has been described. Reading C++ instances from disk is one of the fastest way to load information without incurring in a CPU cost (most of the time, the CPU is idle waiting for the I/O operation to finish). That CPU power could be used to read compressed data to improve load times. Decompression and pointer relocation times can be hidden by the latency of the I/O disk operations. At the end you can go as fast as the read operation allows.
You can discuss this article in the following blog entry:
http://entland.homelinux.com/blog/2007/02/21/fast-file-loading-ii-load-in-place/
Other references:
Read more about:
FeaturesYou May Also Like





