


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
In this technical article, originally printed in Game Developer magazine late last year, veteran game programmer Llopis looks at data baking - that is to say, the steps that 'take raw data and transforms it into something that is ready to be consumed by the game'.

[In this technical article, originally printed in Game Developer magazine late last year, veteran game programmer Llopis looks at data baking - that is to say, the steps that 'take raw data and transforms it into something that is ready to be consumed by the game'.]
Who doesn't like a warm cookie, straight out of the oven? Cookies are created from their raw ingredients (flour, butter, sugar, eggs), which are mixed together, portioned into bite-sized pieces, and baked in the oven until everything comes together just so.
The baking process transforms a set of ingredients that are rather unappealing by themselves, into a delicious and irresistible treat.
Data baking (also called conditioning) is very similar. It's a process that takes raw data and transforms it into something that is ready to be consumed by the game.
Data baking can range from being a complex and involved process that totally transforms the data, to a lightweight process that leaves the data in almost its original format.
Since it's an internal process, totally invisible to the player, data baking rarely gets the attention it deserves. As it turns out, the way data is baked and loaded in the game can have a profound impact not just in your game architecture, but in the development process and even the player experience.
The main goal of data baking is to achieve very fast loading times. The player will have a much smoother experience by being able to start the game right away, and team members will be able to iterate and try different options if the game loads in two seconds rather than if it takes a full minute.
There are also some secondary goals achieved by good data baking: data validation, minimizing memory fragmentation, fast level restarts, and simpler data streaming.
Loading times for a game are determined by two things: disk I/O time and processing time. Inefficient disk I/O patterns can dominate loading times, taking close to 100 percent of the full load time.
It's important to make sure your disk I/O operations are efficient and streamlined before we start thinking about gaining performance from baking data. Make sure to minimize seeks, avoid unnecessary blocking, lay out data sequentially, and the rest of the usual best practices for efficient disk I/O.
What follows is a summary of an ideal baking process from a high level.
These steps happen offline:
Exporting from content creation tool
Transforming into final format
Combining into a memory image
Updating data references.
Which leaves only the following steps at runtime:
Loading memory image
Pointer fixup
Extra processing (optional).
Notice that we've done all the heavy lifting during the baking process offline, and the steps performed at runtime are very simple and very fast.
This illustrates what I used to call the Fundamental Rule of Data Loading: Don't do anything at runtime that you can do offline. Can you generate mipmaps offline? Can you generate pathfinding information offline? Can you fix up data references offline? You know the drill. This rule reflects the fact that it is often much faster to load data than it is to do processing on it.
However, that has changed to a certain extent with the current generation of hardware. Disk bandwidth hasn't increased much, but the amount of memory and the available CPU power has gone up significantly.
So we can amend the previous rule to allow for the possibility of trading some CPU computations for a reduction in data size when possible. For example, you might want to decompress data at load time, or even generate some data procedurally while other data is being loaded.
This process is an ideal one to shoot for, but it's not always possible. On a PC for example, we might not be able to know the exact memory layout of our data or how the compiled version of our graphics shaders will be, so we might have to do some processing at load time.
Also, with an established code base, it might be impractical to take the rule to an extreme because it could take a large amount of manpower to precompute everything possible. In that case, we're trading some amount of optimal data loading for faster development.
Just don't overdo it because if the hit on loading times is significant, your whole development will suffer from slow iteration times.
The goal of data transformation is to take some data in raw format (the way it was exported), to the exact format it will be in memory in the game.
For example, the game will never read XML files, parse them, and create new data at runtime. Rather, all that will happen during the transformation step, and the game will just load a small binary set of data into memory and start using it right away.
The actual data transformation is pretty straightforward.
1. Load raw data.
Raw data can be either in the original format the artist created it in (such as a Maya file, PSD Photoshop file), or in an intermediate file format that was exported from the content creation tool. Using an intermediate file format has many advantages. The file can be text-based and easy to read by a human. It can be versioned more easily.
The format is stable, and, most importantly, the original tool doesn't have to be involved to transform it into the final data format. This last point is particularly important because we want to keep this step relatively fast to allow for fast iteration, so avoiding launching heavyweight applications is a big win.
2. Parse and validate data.
Once the data is in memory, we parse it and at the same time validate that everything makes sense. Are all the particle system parameters within the ranges that you expect? Does the animation skeleton have the correct number of bones? If not, this is the time to raise an error, before the bad data makes it to the game.
3. Fill out the data.
This step is just a matter of filling out the data we collected during parsing in the correct structure fields. Because this step needs to create the exact same memory layout as the game, it's easier to write it in the same language as your game runtime (most often C or C++).
4. Write data to disk.
In order to be able to write to disk the exact data structure that will be used at runtime, we should limit ourselves to C structs and C++ classes without virtual functions. That way we can reliably save the data and reload it without having to worry about vtable pointers. Using structs will also encourage the type of architecture that allows us to use the data right after loading instead of having to process it by calling constructors or other member functions.
This data transformation happens as part of a larger data build, so it needs to run fully automated. It's usually best to implement the program that transforms the data as a command-line application that takes inputs and outputs through the command line. It can also be implemented as a DLL or .NET assembly as part of a larger framework, but never as a GUI program that requires user interaction.
Even though this is an offline process, you still want it to happen as fast as possible so data can get in the game quickly and you can iterate as much as possible. There will be some types of data that have thousands of files that need to be transformed, and the overhead of calling the same program repeatedly can be very noticeable.
To improve performance in that case, it is beneficial to have the program take a list of files to transform and process them all at the same time, rather than invoking the program once for each file.
So far, we've transformed isolated data files, some models, some textures, some AI parameters. The next step is to combine them all into one large file containing the full memory image of all the data that will be loaded.
Combining all the data in a large memory image has many advantages. The main one is that it simplifies and speeds up loading significantly. We can load a single file in memory and start using the data right away. Also, loading all the data as one large block will keep memory fragmentation and allocation overhead down to a minimum.
One way to combine all the files is to create a packfile: A single file that contains all the other files inside along with a catalog that associates each file with the offset where they reside within the packfile.
The catalog can be implemented as a hash table of file names and offsets into the packfile. Whenever the runtime asks for a particular filename, we run the filename through a hash function and access the hash table with the result.
Hashes are not guaranteed to be unique, but with a good hash function, they'll be extremely unlikely to clash. If it ever does, we can detect it during this step and we can adapt (either by changing the hash function, adding more bits, or even changing the filename in a pinch!). Make sure you always normalize filenames before computing the hash by setting them to a consistent case and extending paths to start from a specific root.
You will often want more than a single memory image. Some platforms have different memory areas with different uses, whereby each area could get its own memory image (for example, all the textures and other video memory in one, and all your other game data in another).
Also, sometimes you'll need several memory images to be able to load and unload blocks of data independently. For example, the front end could be a memory image, and the level data another one, so the front end can be unloaded when the game starts. Or you can take it as far as making each screen in the front end a different memory image. It's a tradeoff between memory usage and simplicity.
Since this memory image is the smallest unit of data that is going to be loaded in memory, now is the time to apply compression if you're going to use it. Choose a compression scheme that allows you to decompress it incrementally, as the file is loaded, that way you don't need a loading buffer almost twice the size of your data.
The packfile approach is a big improvement over having loose files in disk that need to be accessed separately, but we can take things further by doing even more pre-processing on the data offline.
The reason we need to have a catalog is because the game will create some data associations at runtime: draw the right textures with the right model, point to the correct game entity definitions from the level, and so on.
Since we have a global view of this data, we can precompute most of those associations during this step.
As we create this memory image, we can change all the places where data has references to other data (usually in the form of filenames at this point) into pointers or offsets.
If you're lucky enough to have a memory management system for your game that gives you control over the location of your data, then you can fully resolve data references into an exact memory address.
You know the start address where the memory image will be loaded, so you just need to add the appropriate offset to that memory address. You can then simply load the data in the game and be ready to go.
For most games, you don't know the exact location in memory where your data will live, but you can still do most of the work offline and then do a quick pointer fix-up at load time.
The idea is to look for all data references and convert them to an offset into the memory image, not the full address.
At the same time, the address of each of those offsets is added to the pointer fix-up table so it can be updated later (see Figure 1). This fix-up table is saved along with the rest of the data.
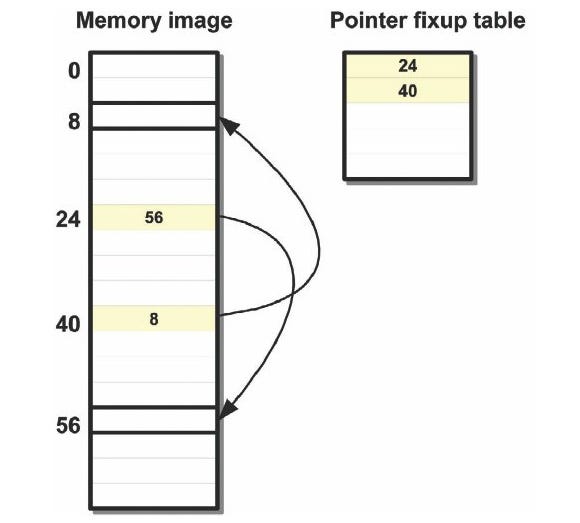
Figure 1: Pointer Fix-up table.
At load time, once all the data has been loaded, we make a very fast pass through the pointer fix-up table and add the address of the start location of the memory image to all offsets.
Using the pointer fix-up table is a totally generic step and works on any type of data without the code having any idea what kind of data it is fixing up. We have done dynamic linking of our data, just like a dll, by relocating it at load time.
Another benefit of computing the references at bake time is that we can detect global data errors. During data transformation, we were able to verify that each piece of data was correct, but we had no idea if a model was pointing to invalid textures. Now we have a global view of all the data, allowing us to detect missing or invalid files and raise errors.
Most games today need to do some type of data streaming during gameplay. Fortunately, the approach to data baking presented in this article fits very well with streaming.
The most straightforward way to stream game data is to break it up into blocks containing data that need to be loaded together. For example, a level could be broken up into blocks containing rooms or sectors.
Then each block can be baked separately, each in a different memory image with its own pointer fix-up table.
The game logic decides what data needs to be present and initiates asynchronous loads for the desired blocks.
Because this approach requires no complex operations at load time, it is very well suited for background loading without affecting the game.
It also minimizes memory fragmentation, and, if you manage to keep each block the same size, then it simplifies memory management tremendously and you know you will never run out of memory.
It's important to hit the right balance between number of blocks and block size. If each block contains just a texture, then we're back to having thousands of separate files and very poor loading performance.
If blocks are very large, they won't fit in memory at once. Finding the sweet spot will depend mostly on your game behavior, what areas are visible, and what actions the player can perform.
To keep streaming even simpler, make sure to make each streaming block fully standalone. In other words, it should contain all the data it needs, independent of what the blocks around it have.
That means that you'll sometimes have to duplicate a texture or a mesh that is present in several blocks.
That's a small price to pay to keep streaming simpler. It also serves to give artists and designers a very specific memory budget, and it can even encourage them to create unique textures for each area if they want to.
What we covered on data baking should be enough to get you started in the right direction.
One important topic I avoided here is the problems introduced by different target platforms, which deserves coverage of its own next month. Until then, enjoy the fruits of your baking.
[EDITOR'S NOTE: This article was independently published by Gamasutra's editors, since it was deemed of value to the community. Its publishing has been made possible by Intel, as a platform and vendor-agnostic part of Intel's Visual Computing microsite.]
Read more about:
FeaturesYou May Also Like





