


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
In the first of a two-part article, Noel Llopis exposes techniques for optimizing game performance by aligning data effectively, showcasing techniques and code samples to smooth out the process.

I grew up on Z80 and x86 assembly. I happily moved data into my registers from anywhere in memory and back without ever giving it a second thought. Life was nice and simple.
It wasn't until years later, when I started dealing with caches, vector units, and different architectures that data alignment became a big deal. Today, data alignment is an inescapable reality, and we all have to deal with it one way or another.
Data alignment refers to where data is located in memory. All data is at least 1-byte aligned, meaning that it starts at any one byte in memory. Data that is n-byte aligned is located somewhere with a memory address that is an exact multiple of n bytes.
We care about alignment for a single reason: Performance.
In modern hardware, memory can only be accessed on particular boundaries. Trying to read data from an unaligned memory address can result in two reads from main memory plus some logic to combine the data and present it to the user.
Considering how slow main memory access is, that can be a major performance hit. Some platforms such as the PowerPC choose not to hide such an inefficient use of hardware and simply raise a hardware exception flagging the invalid memory access. Neither scenario is particularly attractive.
Even when reading from fast, level-one cache memory, unaligned access to data will use up more cache lines, making poor use of the available memory and evicting data that might be accessed again. As a result, sections of your code can thrash the cache and become major performance bottlenecks.
Vector operations usually force programmers to deal with data alignment explicitly. To squeeze more performance without increasing the frequency of CPU cores, hardware designers have been putting more emphasis on vector operations (which are just a type of SIMD instruction -- single instruction multiple data).
One vector instruction can operate on four or more data points at once, considerably improving the performance of a program that operates over each data point serially. Vector units often have a restriction that they can only work on data aligned on a particular boundary.
For example, Intel's and AMD's SSE vector instructions operate on data aligned on 16-byte boundaries, so it is the programmer's responsibility to align the data properly before feeding it to the vector units.
In general, the more you interface with the hardware directly, the more careful you will have to be about the alignment of your data.
You can only deal with alignment in low-level languages such as assembly or C. Higher-level languages often don't expose exact memory locations or provide any means to change them, making all sorts of opportunities for optimization impossible.
In C/C++, finding the alignment of some data is very easy. Just examine the least significant bits of the memory address where the data is located.
Memory alignment restrictions are almost always based on powers of two, so to detect whether something is aligned on a particular power of two, we can "&" the memory address with a particular bit mask and check for any non-zero bits.
For example, the following code checks if some data is aligned on a 16-byte boundary: ((uintptr_t)&data & 0x0F) == 0. Notice the uintptr_t cast to be able to perform a bit operation on a memory address.
Casting the pointer to an int instead is almost guaranteed to cause problems in the future because it assumes that pointers and ints are the same size, which is not the case in most 64-bit architectures.
Generalizing that technique, Listing 1 (found in this ZIP file) shows a function that verifies the alignment on a particular power of two boundary. We'll be using a lot of bit tricks when dealing with memory addresses at this level, so make sure you're nice and comfy with all that bit twiddling.
Setting the alignment for a piece of data, unfortunately, is not nearly as easy. The C/C++ language falls short again, without a standard way of dealing with alignment.
Not only that, but we'll need to use different strategies to align data depending on how it is allocated: statically, on the heap, or on the stack. We're left at the mercy of compiler-specific extensions and our own home-brewed solutions.
Static variables are those not allocated on the heap or the stack. That includes global variables and class static variables.
The two most common compilers we have to deal with as game developers (Visual Studio and gcc) offer solutions to allow us to align data at a particular memory boundary. In both these cases, the alignment has to be a power of two.
Visual Studio provides the __declspec(align(#)) extension. Any variable or type tagged with that extension will be correctly allocated on the specified alignment. gcc also provides its own extension, but of course, with different syntax: __attribute__ ((aligned (#))).
We can create a macro that allows us to specify alignment attributes in a platform-independent way. Unfortunately, __declspec(align()) precedes the symbol it modifies, and __attribute__((aligned())) comes afterwards, making the macro slightly uglier because it needs to wrap the symbol (see Listing 2 in this ZIP file). With this macro we can now write DATA_ALIGN(int buffer[16], 128); in any platform.
 Sometimes we want to align all instances of a particular type on a certain boundary.
Sometimes we want to align all instances of a particular type on a certain boundary.
For example, a 4x4 matrix class that we're going to manipulate with SSE instructions always needs to be aligned on a 16-byte boundary. In that case, we can apply the alignment attribute to the type, not just to specific instances.
__declspec(align(16)) struct Matrix4x4
{
float m[16];
};
Specifying the alignment of a member variable forces the compiler to align it relative to the start of the struct (or class) it belongs to.
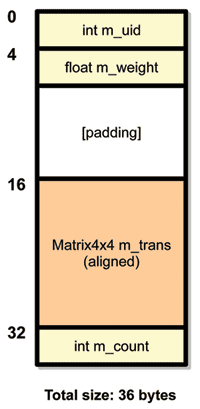
Going back to our previous example, if we add a Matrix4x4 structure to a Waypoint structure, the compiler will pad the Waypoint data so that our matrix is a multiple of 16 bytes from the beginning of the structure (see Figure 1, right).
But what if the Waypoint structure is placed at a random memory location? Does that mean that all bets are off as far as the absolute alignment of the matrix variable?
Fortunately, the C standard comes to the rescue here because it states the following: the alignment for a struct has to be a multiple of the least common multiple of the alignments for all of its members.
That's quite a mouthful, so a simpler way to look at it is that, if alignments are always powers of two, a struct will be aligned the same way as the member with the largest alignment.
That is really good news because now the Waypoint struct is guaranteed to be aligned on a 16-byte boundary, which means that the matrix member variable will also be correctly aligned on a 16-byte boundary.
You would hope that tagging a type with __declspec(align(#)) (or the gcc equivalent) would also align the object correctly when it's created on the heap. No such luck.
Alignment attributes are only used at compile-time, and the C runtime knows nothing about them when you request to allocate a particular type from the heap. Fortunately, we can take control of heap allocations and force the alignment ourselves.
In most cases, malloc will return a 4-byte aligned block of memory. We can create our own version of malloc, aligned_malloc, that allocates memory with any alignment by building on top of standard malloc and pad the front of the memory block until it's aligned correctly.
The only catch is that we need to remember to call our version of free, aligned_free, on that memory when we're done with it.
aligned_malloc will allocate a block of memory large enough, find the first address within that block that has the correct alignment, and return that address. aligned_free needs to call standard free with the originally allocated memory block.
So we need a way to go from our aligned pointer to the original pointer. To accomplish this, we'll store a pointer to the memory returned by malloc immediately preceding the start of our aligned memory block.
The implementation for aligned_malloc and aligned_free is shown in Listing 3 (found here). There are a couple of interesting implementation details:
- We don't know what alignment malloc will return, so we need to account for the worst case. That means that our block has to be large enough to hold the requested allocation size, one pointer, and up to the full alignment size (minus one).
- More bit fun: To find the next address with a particular power of two alignment, we can add the full alignment minus one, and then round it down to the nearest alignment (by masking off the bits corresponding to the power of two of the alignment).
Some platforms implement their own version of aligned_malloc. So if you don't need cross-platform compatibility, you should look at what your platform provides. For example, Microsoft has a function called _aligned_malloc, and other platforms have the semi-standard function memalign, both of which work in a very similar way to the version we just implemented.
Our aligned malloc and free are perfect for allocating plain memory blocks, but what about creating objects with a particular alignment? Next article, we'll cover that and we'll explore the mysteries of stack alignment.
---
Title photo by Jean-Etienne Minh-Duy Poirrier, used under Creative Commons license.
Read more about:
FeaturesYou May Also Like





