


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Black Rock (Split/Second, Pure) core technology group member Julian Adams explores the practical ins and outs of code branches -- including how his team has implemented them, productivity gains, and compromises inherent in the approach.

[Black Rock (Split/Second, Pure) core technology group member Julian Adams explores the practical ins and outs of code branches -- including how his team has implemented them, productivity gains, and compromises inherent in the approach.]
These days, everyone uses a Version Control System (VCS). Like many game developers, the first VCS I used was Visual Source Safe. Back in the 1990s, it was incredible. All five of us in the team shared our work, merged our work, and tagged our releases. Basically, we all knew what was going on, and we all sat together. There were rarely problems, and all was generally good.
Even as teams grew to be about 20 people everything was fine... mostly. Now, though, if something goes wrong, and the build breaks, you might not know the code; you might not even know whose code it is. You can still collaborate pretty freely with anyone on the team -- but sometimes you need to share half-finished code with the guys working directly with you on a feature, and it's a pain. You try and make sure that the interim commits won't break anyone's work, but everyone makes mistakes.
These days, game development has changed. Split/Second had 40 programmers at its peak. Pure had 25 with another 15 developing core technology -- all working on the same code base. There were also 65 people working on game assets in a separate per-project Perforce depot.
Let's define a "broken" build as one that stops someone from working. With the smartest 55 people in the world pushing into the mainline, the build will always be broken for some of them.
As a development team scales up, one way to mitigate build breakages is to start adding automated tests to test whether the build is good, and using continuous integration to run those tests as code is checked in, giving continuous feedback as to the state of the build.
If the tests are sufficiently fast they can be run by coders before checking in any code. If the tests had full coverage of everything that anyone was interested in, and took zero time, that would be it: you'd never check in broken code, as you'd run the tests against the latest, and the latest would always be good!
Tests never have 100 percent coverage, of course, so right there is the chance that code which passes the tests is broken for someone.
On the other hand, test run time (latency) means the test results you see for a branch are out of date. It makes it likely you won't run all the tests yourself pre-commit, or that you ran all the tests against the code you updated to pre-merge, but not against the latest code, post-merge.
The combination of non-zero test time and incomplete coverage combine to mean that the build will get broken at times. As more people check into a single branch, the chance the branch will be broken at any given time increases greatly.
With a large code base the chance that you'll know how to fix a build breakage, or even who to ask, decreases. Branching addresses these issues.
One issue with talking about VCSes is that the terminology isn't totally standard. Most of what I'm going to talk about will be pretty obvious to anyone who's used a VCS. I've used terms which are mostly standard and defined in the Wikipedia entry on revision control.
The terminology for branching is less clear. I'm going to talk about "committing", which refers to storing local changes in the repository, without making them visible to other people, and about "pushing", which refers to publishing changes from one branch to another.
A branch is a set of files in a VCS which are changed compared to the mainline, and evolve independently. Unlike a working directory (for which this is also true) many people can work from and push to a branch.
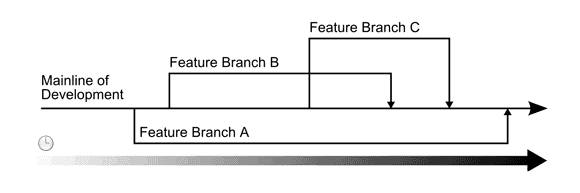
Figure 1. Branches diverging from and merging with the mainline of development.
Branches let you go back to developing in smaller teams. You work directly with five to 10 people. Now you only see changes relevant to what you're working on, related test breakages, and have a small team to keep track of. You've got the opportunity to share code with just the people you're working directly with, and have a staging ground to develop that cool new feature. When it's stable you merge against the mainline, and push your work to the rest of the team.
Conversely, when teams stabilize their branches and then push up to the mainline, the mainline becomes more stable. Again, this is simply a question of numbers. Instead of 70 people pushing into the mainline there are maybe seven teams pushing code in there. Immediately there's a lower frequency to the changes going into the mainline. Also this is code which has already been tested and stabilized on a branch, so it's less likely to cause problems.
So far I've talked a lot about branching, but branching has always been easy. Visual Source Safe could branch, CVS could branch. On the other hand, merging was incredibly hard, and nothing like the normal workflow, as discussed here.
These days, many VCSes make branching and merging as easy as local changes. Look at it like this: every local change you make is effectively a branch. Merging your working directory is merging a branch, committing the changes is reconciling your local working directory (branch) with the mainline. Branching and merging should be this easy, and in a lot of VCSes these days they are.
Distributed VCS (DVCS) has become the big trend in VCSes over the last couple of years. You've probably heard of Git and Mercurial. In short, the idea of these systems is that every branch is a clone of the full depot, so that all revision control functionality, except updating from non-local branches, is available without a network connection. In a situation like that a DVCS had better be good at merging or it won't get many users.
There's an excellent online tutorial for Mercurial. If you've not used a DVCS system, it's well worth checking this out. It's command line-driven, but the simplicity is there, and there are GUIs available if that's what you want. If your VCS doesn't handle branching and merging this well, maybe it's time look at the options, or talk to the vendor!
At this stage you're probably thinking that for game assets, having a copy of the repository with every branch isn't ideal. That's true! I'm not suggesting you should jump on any of the systems and start using them, but they're freely available and show the level of branch and merge support that is the state of the art. Although the examples I've given are distributed, a centralized system can offer equally good branch support. We use Accurev.
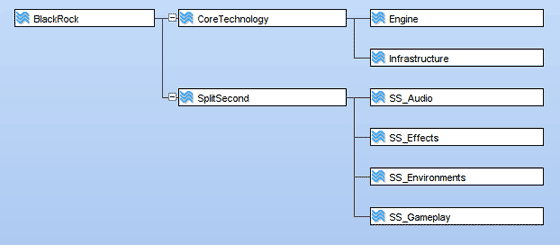
Figure 2. A Branch Per-Team.
When we started, we picked a simple arrangement of branches. Each team in the studio got a branch, and if the teams were big enough they had child branches for each of their sub-teams. Actually this works pretty well. Each team working on a branch was pretty tight knit and focused, and that gives most of the win.
Each team can be using the same core libraries for pretty different projects. Over the last two years, we've had teams working on Pure, on Split/Second, and the technology itself.
To keep us honest, there are a lot of tests we run on servers; from unit tests to module tests to game tests, and there is a feedback system so that you can keep track of the branches of interest.
Unfortunately, some of the full game tests are slow (hours in total) and this influences our approach to branching. Sometimes the tests get broken in a team's branch. That's fine; we fix it.
If you're trying to merge at that time it's pretty inconvenient. What broke the build: the merge or your development changes? We use an "Airlock" system of two branches to deal with this. The parent branch has a merge branch hanging off it and the team's development branch hangs off that.

Figure 3. "Airlock" pairs of development and merge branches.
With this arrangement, we only push transactions into the merge branch which have passed all our tests. Any test failures that we see in the merge branch are the result of the merging. This merge branch is always stable and we use it to track the parent branch, incrementally merging changes both up and down.
As teams get more experienced working with branches we've seen a tendency for teams to start setting up new branches for individual features. In many ways, this is the perfect way of working: collaborate with just the people who are working directly with you at any given moment.
You don't even have to set up the branch before working on feature X. Just start working in a working directory under your team's branch. If and when you start collaborating with other people on X, you can create a new branch under your team's branch, move your working directory to it and have your collaborators do the same.
Figure 4. Feature Branches.
In practice this flexibility is fantastic, although it may highlight other areas of infrastructure which don't offer the same flexibility. For us, setting up tests for a new branch takes longer than setting up the branch, which is something we'll be addressing in the future.
For Split/Second we've seen the hierarchy of branches adapt to the current state of the project. In Accurev and many DVCSes, branches and working directories can be easily moved so that they have a new parent.
Split/Second started with a small team, working in a single mainline branch. Once the project had ramped up into full production, there were nine branches in active development. In practice, that seemed to be too many branches to promote to a single stream, due to the amount of change and breakage seen in the mainline. These development branches were grouped under two merge branches (Merge1 and Merge2) sitting under the mainline.
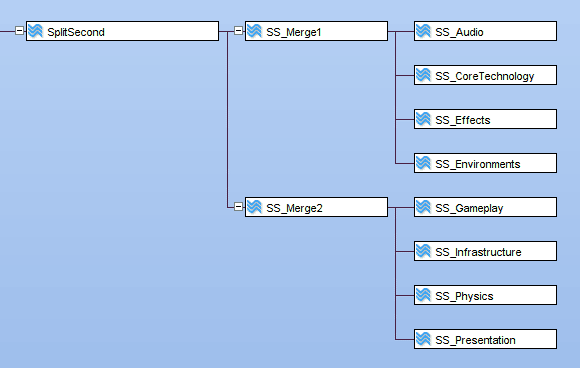
Figure 5. Development with Merge Branches.
When the project was feature complete and being finally bug fixed and tweaked, Merge1 and Merge2 were removed and all branches were pushed direct into the mainline. There was simply much less merging to be done. A more direct connection to the mainline was desirable.

Figure 6. Bug fixing direct to Development Branch.
For long-running branches, from which changes will be pushed into the mainline, there's a question of when to merge. A merge isn't required until you wish to push into the mainline, so, perhaps, that's the only time to merge conflicts between the branches.
In practice, this is somewhat of a gamble. Effectively this is putting an unknown amount of merging work right at the point of feature delivery. Practically we've found it better to keep an eye on conflicts (your VCS should be able to show this to you without you actually merging) and merge regularly.
We've found that merging conflicts as soon as there is confidence that both branches involved are stable is a win. Regular merging allows more regular pushes of work into the mainline, which, in turn allows those pushes to be smaller and easier to merge. This is the same principle as Continuous Integration.
From this, it's clear that there are social issues to manage across teams in different branches of the same repository. Having one team merging and pushing incrementally is of no benefit if another team works on global architectural changes for a few months and then pushes them into the mainline.
Within a single game there's often strong technical and project management organization which ensures that information flows to where it needs to go. However, across multiple games and the technology group, there may not be the organizational and social infrastructure to make code sharing work across branches.
Games are independent entities and generally, rightly, managed as such. If several games are using a given library there may be a diverging vision for that library between the teams. We handle this by making sure there is regular face to face communication between peers at all levels in the studio. For example, all the tools guys meet up once a week to catch up on current work and future plans. This way we get a small team feel for each discipline across the studio and we also minimize conflicts during merges.
There are a few trade-offs. It's important to think about these and consider the options in advance if possible. The first is having to merge the mainline with your branch. Without a branch, each developer merges his or her own changes with the mainline. When there are conflicts each developer knows what the intent of their changes was. If the social side of the studio culture is healthy, they most likely know why there are conflicts also.
A branch needs merging with the mainline in addition to normal merges. Somebody has to do this and that somebody might not be the person who made either of the conflicting changes. At any given time one person is responsible for merging a branch. In general we change this weekly, in a round-robin way. For merges, we encourage people to grab the authors of the original changes if any merge isn't totally obvious. It's not perfect, and there's some overhead, but it works well enough in practice.
The key is responsibility: somebody needs to be responsible for each branch, for testing it, smoothing out any problems, and pushing changes to the parent. Without this, a branch stops working as a means to propagate changes. Although we almost always share ownership of our branches it's equally valid for one person to have responsibility.
In general having fewer, larger changes entering the mainline makes it easier to push into a branch. However there's one point in time when this isn't true: at a milestone. Here everyone's changes need to be in the milestone build. Time is typically short. If everyone is waiting for slow tests to pass in the merge branch, it can take much longer than desired to push up changes.
An alternate strategy is to push up changes from lots of branches almost simultaneously. These changes are all individually tested in their branches. The merges between them are not fully tested before they are pushed into the mainline. It's quicker to get changes to the mainline, although the changes are more likely to break the game initially. In this case that's not a problem: the time taken to merge the milestone's features is reduced, and breaking the delivery build in the short term does not hold up the development team working on the branches.
Binary files represent a significant issue for any workflows which rely on parallel edits and textual merges between branches. These cannot be merged, so in case of conflict you have to pick one change or the other. Traditionally, when developing on a single branch, these files are set up so you have to get exclusive lock on the file before editing it. No merges are required.
With multiple branches can you have a lock which applies to multiple branches? Yes, but what happens if a file is edited in one branch and you want an exclusive lock in another? What version would you edit?
Editing the version in your branch is likely what you want. This gets you a conflict though, even though you have an exclusive lock. Bringing the changes across from the other branch without the rest of the files from that branch may not be correct, as typically changes on any given branch are interdependent. I don't know of a VCS which implements this solution. The commonly implemented alternative is for locking to be exclusive to a single branch only. In case of conflict during the merging of two branches, one version of the file is discarded.
For test files we simply live with this. These files support the tests we run and lack of merging isn't a pain point. We store the assets for the games in separate Perforce depots. This setup has evolved over time. We don't branch these assets and use exclusive locking.
Initially branching the code in Accurev, and having a single branch for assets in Perforce, made it hard for the artists to freely collaborate with each other, and with the coders. Development assets in Perforce simply weren't adequately compatible with the code in all branches of Accurev. The build was often broken.
To coordinate revisions of assets in Perforce to the revision in Accurev we now map each top-level directory in Perforce to a single branch in Accurev. In Accurev we track known-good revisions of the Perforce directories in text files. Since these are text files, they can be easily merged as they are pushed between branches.
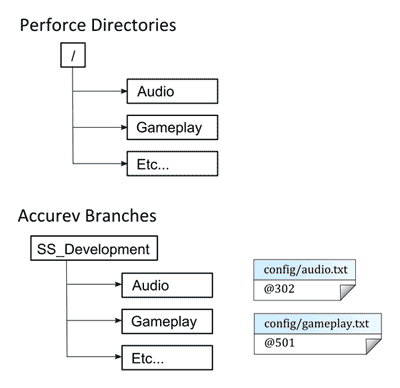
Figure 7. Relating Directories of Assets to Branches of Code.
When you want new assets from Perforce, our tools get the latest version of assets for the Accurev branch you're currently in, as well as the known-good versions of everything else. When code is pushed from a branch in Accurev we use a script to automatically update the known-good Perforce revision based on the tests. This setup enables us to work with multiple branches in Accurev and to collaborate freely with artists. It's dramatically improved the workflows across the teams.
A weakness of this system is that assets must be owned by a single branch and not be edited from multiple branches. Since this system evolved after we set up the asset structure, we had cases where multiple teams wanted to edit a file. For example, both Gameplay and Vehicle teams wanted to alter portions of the car setup. In the end we reorganized the data to remove this contention.
Having a VCS system which enables flexible, comfortable branching and merging is a big win for Black Rock Studio. There are issues which we'd like to address going forward which will improve our workflows further. I'd like to investigate having everything in one VCS. Tracking revisions in two VCSes complicates matters. At Black Rock this is an arrangement which has evolved, perhaps we can consolidate to a single system.
Our games are reasonably tolerant of missing or out of date assets. Incompatible data and a lack of fault-tolerant systems in the games still break builds due to the propagation of the required code through branches. We're going to make absolutely everything the game loads have forward and backward compatibility, with all systems handle loading failures gracefully. This will significantly improve the experience for everybody working on the games.
Although branching increased stability of the mainline it also increased the time taken for changes to reach the mainline. It was overly hard to get a build from the mainline with all the latest features; at times the latency could be one to two weeks. We'd like to make it more routine and easy to push features to the mainline as soon as they are complete and tested to bring the latency down.
We are increasing the flexibility of our build and test systems to make these more easily handle ad-hoc branching and most efficiently use the build machines. This will reduce further still the current barriers to ad-hoc branches. I'm sure that in a couple of years' time, when we finish another game, there will be a lot more to tell.
Thanks to Tim Swan, Jez Moore, Jim Callin, Neil Hutchinson, Rory Driscoll, Tom Williams, Steve Uphill and Shawn Hargreaves who all gave valuable comments and feedback on this article.
[1] Branching and Merging in CVS: http://kb.wisc.edu/middleware/page.php?id=4087
[2] Mercurial Tutorial: http://hginit.com/01.html
[3] Continuous Integration: http://martinfowler.com/articles/continuousIntegration.html
Read more about:
FeaturesYou May Also Like





