

Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
Analytics Event Collection and Storage with Apache Flume NG
A look at how Plumbee collects and stores analytics events from its gaming platform using Apache Flume NG.
7 Min Read

At Plumbee we take a data driven approach to analysing our business and hold strongly to the belief that you can never have enough data. As a result a significant proportion of our workforce are dedicated to the analysis of events from sources as diverse as Customer Relationship Management (CRM), advertising, database writes and Remote Procedure Calls (RPCs). On any given day we collect approximately 450 million events adding 166GB of compressed data to our existing warehouse of 87TB, all of which is stored in Amazon’s cloud based storage solution S3 (Simple Storage Service).
In a previous blog post we discussed our approach to logging analytics events represented in JSON into Amazon’s Simple Queue Service (SQS), a highly scalable, reliable and fast cloud based message queue. In this post we cover the consumer side of that story focusing on how we process and store those events in S3 using Apache Flume NG.
What is Flume NG?
Apache Flume NG (Next Generation) is an open source project written in Java which uses the architectural paradigm of streaming data flows for moving events between different systems. Flume's basic architectural model revolves around three core components; sources, channels and sinks. Events are consumed by a source component and temporarily stored in a channel before being picked up by a sink which then stores the event in an external repository (a final destination point) or forwards the event to another agent for further processing. When sources, channels and sinks are chained together they define a flow in which events move between each hop/component using a transactional model to guarantee message delivery. Flume also supports the concept of interceptors, which allow events to be manipulated in-flight as they move between source components and downstream channels.
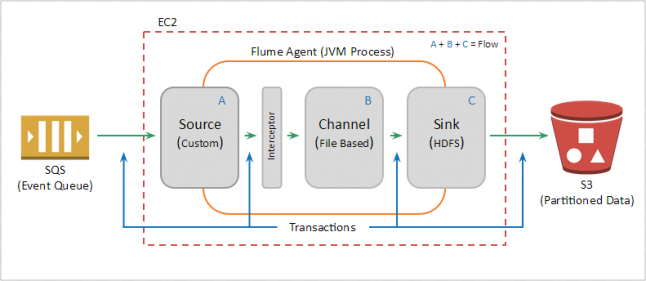
The next sections describe in more detail the source, channel, and sink we use to support our use case.
SQS Source
To retrieve events from SQS we created a custom Flume SQS source plugin which uses batch API calls, long polling and a back off policy for improving efficiency and reducing costs. In Amazon you pay for what you use so the fewer calls you make the less expensive it is.
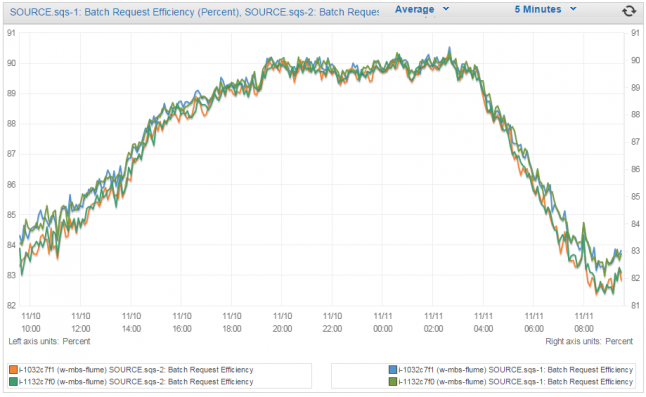
Our plugin is heavily instrumented (extending from Flume’s in-built MonitoringCounterGroups framework) to provide us with metrics to measure how the plugin is performing. These metrics can be queried using Jconsole or (if enabled) exposed via a Jetty web server running inside the agent. An example of the web server output can be found below:

To provide better visibility of these metrics we also publish them to Amazon’s CloudWatch service via a custom Flume MonitoringService plugin. We have alarms on key metrics to notify us when things look abnormal and require our attention.
With regards to efficiency we always try and operate our Flume nodes at 90% batch efficiency (BatchEfficiencyPercentage). This means that for every batch request we make to SQS we get back 9 out of a maximum 10 messages. Unlike our producers who try and get rid of data as fast as possible to mitigate potential data loses when servers are terminated, consumers can simply back off to achieve maximum efficiency and reduced costs.
Event Partition Interceptor
To access our data efficiently we partition our events in S3 by date, type and sub_type. This partitioning allows us to:
Process our data more easily. The event type and sub_type form part of the S3 key (file path) and provide our processing tools upfront knowledge of what type of processing should be applied to the data without the need to actually deserialize the content.
Only read relevant data. Without partitioning, if we wanted to retrieve a list of all transactions made in the w/c 2014-06-09 we’d need to read approx. 1TB of data, deserialize the JSON events and discard 98.6% to access the mere 15MB of data we’re actually interested in.
Achieve higher levels of compression.
To support our partitioning logic we created a custom Flume interceptor that deserializes the JSON event, looks at the data structure and assigns it to a partition recorded in the event’s message header. When the event is later transferred from the File channel to the HDFS sink, those headers are used to construct the location of where data should be written to in S3.

Infrastructure & File Channel
Within our data collection infrastructure we have several Amazon Elastic Compute Cloud (EC2) instances provisioned via CloudFormation which run a single Flume agent each. We use an Instance Store backed Amazon Machine Image (AMI) which during bootstrapping gets allocated an Elastic Block Store (EBS) volume from a centrally managed pool. These volumes are used to store temporary channel data and act as an area for the HDFS event sink to partition and compress data prior to long term storage in S3.
Our infrastructure is built in such a way that at any given time we can lose an instance and another will be provisioned automatically via Auto Scaling Groups (ASG). The new instance will reclaim the terminated instance’s EBS volume and continue processing from where it left off. Flume’s transactional model for processing data ensures that we don’t lose any events.
HDFS (S3) Event Sink
As our sink, we use Flume’s HDFS (Hadoop Distributed FileSystem) sink. Its main responsibilities are to aggregate, compress and upload data to S3.
Most Big Data tools don’t perform well when processing lots of small files so to compensate for this we aggregate our data into larger files and only upload it to S3 when any of the following criteria are met:
The uncompressed file size has reached 512MB.
No data has been written to the file in the last 6 hours, i.e. it is considered idle.
It's 08:30 in the morning. All open files regardless of size are uploaded to S3. We’ve patched the HDFS event sink to support this cron based file rolling functionality allowing us to make sure that all the data for the previous accounting day (represented in PST) is uploaded to S3 before automated Extract Transform Load (ETL) activities start to process it.
The HDFS sink also compresses our data using Snappy. We’ve opted for Snappy compression over LZO as our internal benchmarks showed a better decompression speed for a marginally larger archive size. Prior to our adoption of Flume, data was compressed using gzip and although gzip produces very small archive sizes, its decompression speed is very poor. We found a lot of our processing activities spent the vast majority of CPU time deflating the gzip as opposed to actually performing our calculations. Moving to Snappy gave us a fourfold improvement in read speeds.
Finally, the sink stores files in SequenceFile format, a container file format for storing binary key-value pairs which enables the Hadoop MapReduce framework to split the files into chunks for distributed processing.
Next Steps
Since deploying Flume to production a little over a year ago we’ve not experienced any major issues. With improvements in how we record data via partitioning, aggregation and data compression we’ve reduced our daily ETL processing times from around 4 hours to just under 1.
Even though we are fairly happy with our current infrastructure we always look to make improvements and during the last year we’ve investigated switch data representations from JSON to Avro and moving from SQS to Amazon Kinesis. We’re still looking into those, but in the meantime if you’re interested in using our SQS plugin, the source code is available at: https://github.com/plumbee/flume-sqs-source
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like







