Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
What follows AlphaStar for Academic AI Researchers?
DeepMind continues making progress, but the path forward for AI researchers in academia is unclear.
8 Min Read

Ten years ago I challenged AI researchers across the globe to build a professional-level bot for StarCraft 1. The Brood War API was recently released, and for the first time academics and professionals could test out AI systems on a highly-competitive RTS game. In the following years a number of AI competitions were held, and while bots started pushing into higher ladder ranks, there was still a large gap to reach professional-level gameplay. When DeepMind announced that they we taking on StarCraft II in 2016, I expected progress would take several years to improve upon existing approaches and reach professional-level gameplay. But I was wrong, and AlphaStardemonstrated last week that deep reinforcement learning could be used to train a bot competitive with professional gamers.

While many people expressed concerns over the constraints placed on the match up, Protoss mirror match-up on a single map with high APM limits, I anticipate that AlphaStar could overcome these limitations with additional training. There were also concerns that AlphaStar was competing against a professional and not a grandmaster of StarCraft. Whether or not this criticism is valid, the point still stands that AlphaStar was able to defeat professional level players. Given the strong results of the demonstration, I consider StarCraft a solved problem and suggest we move to new AI challenges.
But the big question for AI researchers, especially in academia, is how do we build upon the progress demonstrated by AlphaStar? First of all, most academic researchers won’t have access to the types of resources that were available to DeepMind:
Massive Compute: DeepMind leveraged a farm of TPUs to train AlphaStar on hundreds of years worth of gameplay. Similarly, OpenAI used massive compute resources when building OpenAI Five for Dota 2.
Open APIs: The DeepMind team had access to engineers at Blizzard, making sure that the API was functioning as intended, versus BWAPI which had issues due to it being reverse engineered.
Training Datasets: DeepMind was able to train on anonymized replays from professional players to bootstrap the learning process.
I previously wrote about these limitations when OpenAI Five competed with professionals, and while DeepMind has improved upon the second and third points significantly, the fact remains that academics have a huge disadvantage when it comes to resources. Another issue is the lack of materials available for building off of the progress of AlphaStar. For example, it’s until how other researchers can test their bots versus this system.
AlphaStar is a huge advancement for AI, but for AI researchers that want to work on big open challenges, the best opportunity to make progress on these types of problems is to leave academia and join a company such as DeepMind or OpenAI. In the short term this may not be too big of an issue, but it does create a problem for building a long-term AI talent pipeline.
For AI researchers in academia, we need to rethink the types of problems where we can make progress. Making incremental improvements on AI benchmarks is no longer viable if the problem can be solved by throwing huge compute resources at the problem. Here are recommendations I have for AI researchers in academia working on AI for games:
Identify smaller-scale problems: I called out StarCraft as a grand AI challenge, because it had so many problems to solve for AI systems. While these types of problems may be useful environments for getting funding, progress can be made with smaller challenges. For example, King has been using deep learning to perform automated playtesting for Match 3 games, which are much more tractable than StarCraft.
Build reproducible AI: In order to encourage incremental research, its useful to release source code and data sets for published papers. I took this approach and published a data set for build order prediction, but didn’t release code. I later reproduced this work and wrote about the process.
Evaluate versus humans: In order to evaluate the performance of an AI system, it’s useful to frequently test against human opponents. This was an approach I took with my dissertation project, and I performed an ablation study where different reasoning components were disabled and the resulting bot was tested versus humans, as shown in the figure below. Make sure to get IRB approval if necessary for work like this.
Explore learning with less compute: One of the issues with reinforcement learning is the amount of training needed to learn policies. Researchers can potentially make progress in this area without making use of massive compute resources.
Revisit transfer learning: One of the methods explored in early RTS research was transfer learning, with systems such as TIELT. Given the massive compute necessary to train networks, transfer learning seems like a good area to explore for researchers to make progress.
There’s still the need to explore grand AI challenges in academia, but the solutions may come from private companies.
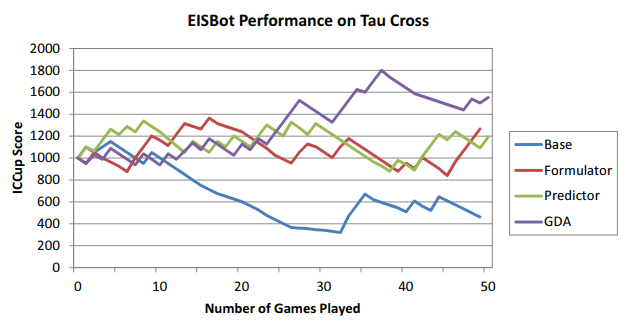
Testing my bot versus human opponents on ICCup.
One of the things that I find most fascinating about AlphaStar is that it continues to learn as more and more compute is thrown at the problem. This isn’t saying that the problem is easy, but instead saying that the system built by DeepMind is novel and continues to learn with additional experience, which is a huge step forward for AI. DeepMind wasn’t able to solve StarCraft simply because of resources, but through clever design and massive compute. I previously blogged about some of the challenges that DeepMind would have to overcome, and many of these issues seem to be addressed by AlphaStar:
Fog-of-War: AlphaStar performs scouting behavior similar to pro-players and continuously engaged with opponents to gain intel. However, due to the stalker focused build of AlphaStar, it’s unclear if the bot performs forward reasoning about the build orders of opponents.
Decision Complexity: It wasn’t clear from the demonstration video how AlphaStar decouples build-order decisions from micro-management, but it does seem like the bot uses as much information as possible when deciding which unit or structure to build next. AlphaStar has addressed this issue by building reasoning systems that work well with decompositions of the StarCraft problem space.
Evolvin Meta-game: One of the cool things to learn when watching the demonstration was that AlphaStar was training on a league of different bots, which are constantly trying out new strategies. This approach should help with small changes in gameplay, but might not translate well when new maps are introduced to the bot.
Cheese: The bot scouted well and sent additional workers to investigate scouting units in the initial matches, which shows that the bot may have learned to adapt to early rush strategies. However, cheese tends to be map specific and it’s unclear how AlphaStar would generalize.
Simulation Environment: One of my assumptions was that AlphaStar would have to perform forward modeling in order to play at a professional level, but it’s unclear at this point if the bot does any explicit planning. This isn’t something that was necessary for the goal of professional play, but something I thought would be a prerequisite.
Real-time: AlphaStar seems to have a good decomposition of gameplay, when means that once training is performed, the action to take at any given time does not take significant resources.
The result of all of this training is a bot that puts a lot of pressure on opponents, and does exhibit different strategies throughout a matchup. But one criticism does still remain, which is that AlphaStar is exploiting units (stalkers) in a way that is not humanly possible. This is a similar outcome to the first StarCraft AI competition, where Berkeley’s Overmind used mutalisks in a novel way. While this is a valid criticism when the goal is to pass a Turing test, it wasn’t the goal I set for StarCraft AI, and I expect ongoing work with DeepMind to move beyond this tactic.
AlphaStar is a huge step forward for RTS AI, and I’m excited to see what gets shown off at Blizzard this year. However, for academic AI researchers, this is another demonstration that AI requires huge compute for advances. My recommendation is to explore smaller problems where progress can be made, and to demonstrate learning and transfer learning before scaling up.
Ben Weber is a principal data scientist at Zynga. We are hiring! This post is an opinion based on my experience in academia and does not represent Zynga
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like







