Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Random Scattering: Creating Realistic Landscapes
Neversoft co-founder Mick West continues his acclaimed Gamasutra technical analyses by showcasing a technique (including source code) for procedurally scattering trees across a game level.
12 Min Read

[In this technical article, originally published in Game Developer magazine, Neversoft co-founder Mick West continues his acclaimed analyses by showcasing an algorithm for procedurally scattering objects such as trees across a game level.]
In procedurally generated or procedurally augmented scenes, a common problem is how to scatter something around in a way that looks natural. For example, a landscape might have trees that are evenly scattered, either sparsely as on an African savanna or densely as in a forest. Also, trees are generally surrounded by other vegetation, which is also scattered.
Suppose you are tasked with developing algorithms to facilitate this scattering. This article looks at various approaches and problems you might encounter.
Just Random?
Let's say you take the simplest approach first. Given a number of trees and an area to put them in, simply scatter them randomly across that area. It's very easy to implement this to see how it looks. Just pick n random positions in a square.
Figure 1 shows the result for a group of 110 objects, in this case, dots that represent individual trees. (To see the code used to generate the figures in this article, click here.)

Figure 1: The green dots represent trees randomly scattered on a plane, viewed from above. Although the scattering is entirely random, it looks neither random nor natural.
Problems with this first solution are immediately apparent. Several of the dots on Figure 1 overlap, meaning the geometry of the trees would intersect. There is some strange clumping going on, with trees showing up in little lines of three or four.
Then there are several wide-open spaces, and a few trees off by themselves. This might work for some odd species of plant, but it's not what we were going for.
We might at first assume that there's a problem with our random number generator. Why else would these strange clumps occur? Is the random number generator tending to favor certain numbers? Unfortunately, it's not that simple.
This is what random numbers look like. If you pick a bunch of random numbers in a certain range, it's highly likely that some of the numbers will be close to each other. This is related to the birthday paradox: it only takes 23 people in a room for there to be an even chance of two people having the same birthday.
Random Nature
Consider what's actually being simulated. What does it look like and how has it arrived at this state? Can we model it using the underlying processes that occurred in nature? Or is it better to create some more abstract model simply based on our observations?
Let's first back up and think about what's happening.
Most plants grow from seeds. A seed falls on the ground, sprouts and grows, absorbing nutrients from the soil, air and, sun. Where each seed falls will determine whether it survives. More mature plants that are nearby will compete for the available nutrients, sucking them away from the sprouting seeds.
Mature plants can also block sunlight from seedlings and even reduce the quality of the air. Certain plants go further, releasing chemicals into the ground that inhibit the growth of other plants.
As a simplification, we can think of the area around a tree as having an exclusion zone, where other plants are not likely to survive. To implement this premise, we simply scatter the trees as before, but now for every tree that's placed, we check whether its location is too close to another tree.
If it is, then we pick another spot and try that. If we can't find a spot after a number of attempts, we would declare the area full and stop trying. Figure 2 shows the results of this implementation using the same number of dots (trees) as Figure 1.

Figure 2: If a tree is too close to another tree in a randomly scattered pattern, we can move it elsewhere. Although the result is more natural looking, clumping can still occur, which may or may not be desirable.
Figure 2 contains some very interesting differences. For example, the overlaps and strange groupings have all but vanished. However, there are still a few open spaces with what look like paths leading through the forest. I suspect these are actually artifacts of the algorithm, with spaces of 1.5 times the minimum space being unlikely to be filled, and hence growing into these paths.
This solution might also have performance implications. Since we need to check every tree against every other tree, the naive algorithm is O(n2) complexity, which can become rather expensive. However, it's reasonably straightforward to optimize this with a bucket method, essentially reducing it to O(n).
Random Complications
This simple model works reasonably well, but the distribution is still patchy. What's going on? Well, obviously in real-life, trees do not have "kill zones" surrounding them. Rather they have something more like an inhibit field, where the successful growth of a tree is exponentially more unlikely the closer it is to other trees. The success of a tree is a function of the sum of all the other trees' inhibit fields at that point.
Secondly, trees don't grow one at a time in nature; they grow over the course of several years, with new trees germinating every year. Old trees die and open up space, which other trees then fill, competing for the space. Over many generations, this natural renewal of trees evens out the distribution, making it even and natural.
While natural tree distribution over the course of several decades is something we could simulate, this is for most games unrealistically expensive.
We really don't want to be running a simulation of a forest ecosystem just so we can get an even distribution of trees. We need to look at creating a simple model of the results without regard for the underlying physical process.
Teleological vs. Ontogenetic
Two competing methodologies in procedural content generation are teleological and ontogenetic. The teleological approach creates an accurate physical model of the environment and the process that creates the thing generated, and then simply runs the simulation, and the results should emerge as they do in nature.
The ontogenetic approach observes the end results of this process and then attempts to directly reproduce those results by ad hoc algorithms. Ontogenetic approaches are more commonly used in real-time applications such as games. (See "Shattering Reality," Game Developer, August 2006.)
Step back for a second. What we want are trees that are randomly scattered, not overlapping, yet still evenly distributed. What if we started off with the trees perfectly evenly distributed (say on a square grid), and then simply move each tree a random amount, but not so far that they can overlap?
This solution actually works quite well. If we spread the trees out on a grid with a distance D between each tree, and we move each tree in the x and y directions by a random amount between -D*0.4 and D*0.4, then we know no two trees can be closer than D*0.2. See Figure 3 and Listing 1, which contains the algorithm.
Listing 1
void CreateScatter(float x, float y, float w, float h, int rows, int cols)
{
float xd = w/cols;
float yd = h/rows;
for (int ix = 0;ix <(cols+1);ix++) {
for (int iy = 0;iy<(rows+1);iy++) {
float p = 0.4f;
CreatePoint( Vector2(x+xd*ix+rndf(-p,p)*xd,y+yd*iy+rndf(-p,p)*yd));
}
}
}
Figure 3 looks something like a cross between the pure random scatter and the minimum distance scatter. The trees are evenly distributed, but we still see some minor clumping, including two trees that overlap slightly. But overall this algorithm produces much nicer looking results than our first attempt, and it's simpler and cheaper to implement than the second.

Figure 3: The trees here in this random perturbation-style scatter start off in a regular grid and are moved randomly by a small amount. The result is a very even distribution.
It also has another advantage: It is repeatable. Repeatability is important in a spooling environment where you want each patch of ground to look the same in the same location. When you see a couple of trees, then leave the location and return later, you would expect to see the same two trees in the same place.
We can accomplish this in a game environment by using the low order bits of the original x, y position of the tree as a seed for your random number generator.
This can then be used to generate both the positional offset and the full appearance (the geometry and textures) of our procedural tree. Thus any tree generated from that unique point will always visually be the same unique tree in the same place whenever you return to it.
Mass-Spring Scattering
A common method in the literature of distributing objects in a non-overlapping manner is to essentially connect each object to its neighbors by a spring and then "relax" the positions of the objects so that the springs take care of the constraints and the factors influencing distance.
Figures 4 through 6 show this process:
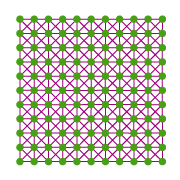
Figure 4: The spring mass system is shown here in its initial state. Each tree is connected to its neighbors by springs of random rest length.
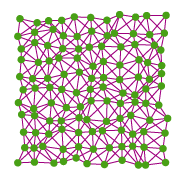
Figure 5: The spring mass system is shown after running 40 iterations.

Figure 6: The tree distribution pattern from the spring mass system is shown with the springs removed.
First in Figure 4, the trees are arranged in a regular grid with springs between them. Each spring has the same initial length (different for diagonals), but has a random rest length. The spring mass system is then iterated several times (40 times in this example; see Figure 5); we then remove the springs, leaving the trees in their final positions (Figure 6).
The relaxing method has a number of problems. For one, it's a more complex method to implement. Second, it requires tweaking to get good looking results. Third, there are problems at the boundaries of the area we are trying to cover.
Because the spring mass system's rest state is unlikely to be similar to the start state, the boundaries of the system end up either shrinking inward or expanding outward, unless the system wraps or additional constrains are added.
Different Sized Trees
So far, we've been trying to evenly scatter a bunch of identically sized objects. What if we want to have objects of differing sizes, with differing growth inhibit zones? The mass-spring system is not so suitable for this task, as it's not trivial to get an initial regularly spaced configuration (although it can be done).
Instead, we could change to a particle system in which each object repels every other object according to some function of distance that is in keeping with their mutual zones of exclusion-and an additional constraint is applied to keep them all together. This is obviously an expensive operation, as it requires multiple iterations of O(n2).
Alternatively, we can go back to the random scattering method where we simply move the object to a new and random position if it gets too close to any other object. This approach requires essentially a single iteration of O(n2), since there are generally very few collisions.
It can also be optimized much closer to O(n) by using buckets for proximity, as mentioned earlier. Figure 7 shows the results of such an algorithm.

Figure 7: Random scattering is shown here with proximity constraints for four different sized objects.
Of all these methods, only the random perturbation is trivially amenable to reproducible procedural landscape generation in arbitrarily small amounts. Since the other methods need to generate a specific number of trees at once, you would need to fill an entire segment of the environment.
To avoid visible boundaries between regions of trees, these segments should conform to natural boundaries within the environment, such as rivers or roads. Since simple positions are not very memory intensive, this method works well for large segments. It's also an ideal process to put on a low priority thread as part of a "procedural spooling" system (see "Procedural Spooling," Game Developer, February 2007).
The Forest, The Trees
Random scattering in nature is not really random. A complex set of underlying rules governs the pattern, even if humans can only see the results as random; however, an image of pure mathematical randomness doesn't look "natural" at all.
Sometimes simple solutions work out better than complicated ones. In this case, to scatter a forest of trees, we found that applying a very simple exclusion zone around plants achieved a nice random distribution of different sized plants.
For most situations, this is reasonably quick and compares well to more complex solutions that involve relaxing spring systems.
[EDITOR'S NOTE: This article was independently published by Gamasutra's editors, since it was deemed of value to the community. Its publishing has been made possible by Intel, as a platform and vendor-agnostic part of Intel's Visual Computing microsite.]
Read more about:
FeaturesAbout the Author(s)
You May Also Like







