

Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
How we made particles twice as fast through cache optimisation
Cache optimisation is one of the most hardcore, low-level topics in game programming. In this post I explain the basic ideas, and show an example of how our particle systems went from tons of cache misses to good memory coherence.
11 Min Read

Cache optimisation is one of the most hardcore, low-level topics in game programming. It's also a topic that I haven't been very successful with myself: I tried optimising for cache efficiency a few times but never managed to achieve a measurable improvement in those specific cases. That's why I was quite intrigued when our colleague Jeroen D. Stout (famous as the developer of the experimental indie game Dinner Date) managed to make our particles twice as fast. What's the trick? Jeroen was kind enough to tell me and today I'll share his approach. Since it's such a hardcore topic, I'll start by giving a general overview of what cache optimisation is in the first place.
Let's have a look at computer memory, or RAM. Computers these days have gigabytes of very fast memory that's used to store whatever the game or program needs to use on the fly. But is that memory truly so fast? Physically, it's a separate part of the computer. Whenever the processor needs to get something from memory, it needs to be transported to the CPU. That only takes a tiny bit of time, but a modern processor can perform billions of operations per second. At those kinds of speeds, a tiny bit of time is actually a lot of operations that the processor could have done during that time. Instead, it's waiting for something to come out of memory.
This is where cache comes in. Cache is a small amount of even faster memory that's directly on the processor and is thus a lot faster to access than normal memory. So whenever something is already in cache, the processor doesn't have to wait for it (or at least not as long) and can keep working. According to this article cache can be up to 27 times faster than main memory.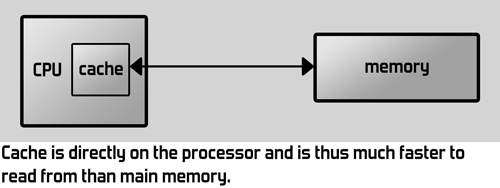
As programmers we generally don't have direct control over what's in cache: the processor tries to utilise the cache as efficiently as possible by it's own volition. However, depending on how we access memory, we can make it a lot easier for the processor to use cache efficiently. This is where cache optimisation comes in.
The goal of cache optimisation is to structure our code in such a way that we use cache as much as possible and need to wait for memory as little as possible. Whenever the processor needs to get something from memory and it's not already available in cache, that's called a cache miss. Our goal is to avoid cache misses as much as possible.
To be able to avoid cache misses, we need to know a little bit about how cache works. I'm no specialist in this field, but we only need a small bit of knowledge to already understand how a lot of cache optimisations work. These are the basic ideas:
Data is transferred from memory to cache in blocks. So whenever you're using something, the memory directly around that is likely also already available in cache.
Cache is often not cleared immediately. Things you've just used have a good chance of still being available in cache.
The processor tries to predict what you'll use next and get that into cache ahead of time. The more predictable your memory access, the better cache will work.
These three concepts lead to a general rule for writing code that's efficient for cache: memory coherence. If you write your code in such a way that it doesn't bounce all over memory all the time, then it will likely have better performance.
Now that the basics are clear, let's have a look at the specific optimisation that Jeroen did that halved the CPU usage of our particles.
To avoid dumping huge amounts of code here, I'm going to work with a highly simplified particle system. Please ignore any other inefficiencies: I'm focusing purely on the cache misses here. Let's have a look at a very naive approach to implementing a particle system:
struct Particle
{
Vector3D position;
};
class ParticleSystem
{
std::vector<Particle*> particles;
void update()
{
for (int i = 0; i < particles.size(); ++i)
{
particles[i]->position += speed;
if (shouldDestroy(particles[i]))
{
delete particles[i];
particles.erase(particles.begin() + i);
--i;
}
}
while (shouldAddParticle())
{
particles.push_back(new Particle{});
}
}
};
|
This code is simple enough, but if we look at it from a cache perspective, it's highly inefficient. The problem is that every time we create a new particle with new, it's placed in a random free spot somewhere in memory. That means that all the particles will be spread out over memory. The line particles[i]->position += speed; is now very slow, because it will result in a cache miss most of the time. The time the processor spends waiting for the particle's position to be read from memory is much greater than the time that simple addition takes.
I knew that this would give performance problems, so I immediately built the particles in a more efficient way. If we know the maximum number of particles a specific particle system can contain, then we can reserve a block of memory for that on startup and use that instead of calling new all the time.
This results in a bit more complex code, since we now need to manage that block of memory and create objects inside it using placement new. In C++, placement new allows us to call a constructor the normal way, but use a block of memory that we already have. This is what the resulting code can look like:
struct Particle
{
Vector3D position;
};
class ParticleSystem
{
unsigned char* particleMemory;
std::vector<Particle*> particles;
int numUsedParticles;
ParticleSystem():
numUsedParticles(0)
{
particleMemory = new unsigned char[maxCount * sizeof(Particle)];
for (unsigned int i = 0; i < maxCount; ++i)
{
particles.push_back(reinterpret_cast<Particle*>(
particleMemory + i * sizeof(Particle)));
}
}
~ParticleSystem()
{
delete [] particleMemory;
}
void update()
{
for (int i = 0; i < numUsedParticles; ++i)
{
particles[i]->position += speed;
if (shouldDestroy(particles[i]))
{
//Call the destructor without releasing memory
particles[i]->~Particle();
// Swap to place the dead particle in the last position
if (i < numUsedParticles - 1)
swap(particles[i], particles[numUsedParticles - 1]);
--numUsedParticles;
--i;
}
}
while (shouldAddParticle() && bufferNotFull())
{
//Placement new: constructor without requesting memory
new(particles[numUsedParticles]) Particle{};
++numUsedParticles;
}
}
};
|
Now all the particles are close to each other in memory and there should be much fewer cache misses when iterating over them. Since I built it this way right away, I'm not sure how much performance I actually won, but I assumed it would be pretty efficient this way.
Nope.
Still lots of cache misses.
In comes Jeroen D. Stout, cache optimiser extraordinaire. He wasn't impressed by my attempts at cache optimisation, since he saw in the profiler that the line particles[i]->position += speed; was still taking a disproportionate amount of time, indicating cache misses there.
It took me a while to realise why this is, but the problem is in the swap-line. Whenever a particle is removed, it's swapped with the last one to avoid moving all particles after it one forward. The result however is that as particles are removed, the order in which we go through the particles becomes very random very quickly.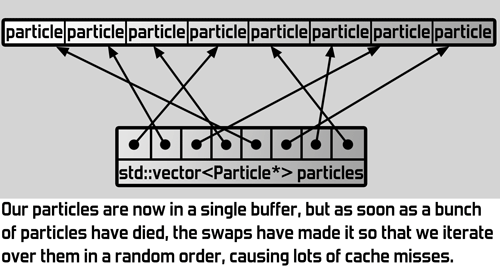
The particles in our example here are really small: just a single Vector3D, so 12 bytes per particle. This means that even if we go through the particles in random order, we might occasionally still be staying in the same cache line. But a real particle in the Secret New Game (tm) that we're developing at Ronimo has much more data, like speed, scale, orientation, rotation speed, vibration, colour, and more. A real particle in our engine is around 130 bytes. Now imagine a particle system with 100 particles in it. That's a block of memory of 13,000 bytes. Hopping through that in random order is much more problematic for cache!
Thus, Jeroen set out to make it so that updating particles goes through memory linearly, not jumping around in memory at all anymore.
Jeroen's idea was to not have any pointers to the particles anymore. Instead we have that big block of memory with all the particles in it, and we store the indices of the first and last currently active particles in it. If a particle dies, we update the range of living particles and mark the particle as dead. If the particle happens to be somewhere in the middle of the list of living particles then we simply leave it there and skip it while updating.
Whenever we create a new particle, we just use the next bit of memory and increment the index of the last living particle. A tricky part here is what to do if we've reached the end of the buffer. For this we consider the memory to be a ring buffer: once we reach the end, we continue at the start, where there's room since those particles will have died by now. (Or, if there's no room there, then we don't create a particle since we don't have room for it.)
The code for this isn't that complicated, but it's a bit too much to post here. Instead, I'm just going to post this scheme:
Compared to my previous version, Jeroen managed to make our particles twice as fast with this approach. That's a pretty spectacular improvement and shows just how important cache optimisation can be to performance!
Interestingly, my first hunch here is that this optimisation is a bad idea since we need to touch all the dead particles in between the living ones to know that they're dead. Worst case, that's a lot of dead particles. In fact, when looking at computational complexity, the worst case has gone from being linear in the number of currently existing particles, to being linear in the number of particles that has ever existed. When I studied computer science at university there was a lot of emphasis on Big O Notation and complexity analysis, so to me this is a big deal.
However, as was mentioned above, accessing cache can be as much as 27 times faster than accessing main memory. Depending on how many dead particles are in the middle, touching all those dead particles can take a lot less time than getting all those cache misses.
In practice, the lifetimes of particles don't vary all that much. For example, realistic particles might randomly live between 1.2 seconds and 1.6 seconds. That's a relatively small variation. In other words: if there are dead particles in between, then the ones before them will also die soon. Thus the number of dead particles that we need to process doesn't become all that big.
The big lesson this has taught me personally, is that cache optimisation can be more important for performance than Big O Notation, despite that my teachers at university talked about Big O all the time and rarely about cache optimisation.
Several commenters on Twitter and Reddit suggested an even simpler and faster solution: we can swap the dead particles towards the end of the list. This removes the overhead of needing to skip the dead particles and also removes the memory that's temporarily lost because dead particles are in the middle. It also simplifies the code as we don't need to handle that ring buffer anymore.
For further reading, I would like to again recommend this article, as it explains the principles behind cache lines very well and shows some clever tricks for optimising to reduce cache misses.
As a final note, I would like to also stress the unimportance of cache optimisations. Computers these days are super fast, so for the vast majority of code, it's fine if it has very poor cache behaviour. In fact, if you're making a small indie game, then it's probably fine to ignore cache misses altogether: the computer is likely fast enough to run your game anyway, or with only simpler optimisations. As your game becomes bigger and more complex, optimisations become more important. Cache optimisations generally make code more complex and less readable, which is something we should avoid. So, use cache optimisations only where they're actually needed.
Have you ever successfully pulled off any cache optimisations? Are there any clever tricks that you used? Please share in the comments!
For more blogposts on development of Awesomenauts, Swords & Soldiers, Cello Fortress, Proun, procedural music, my cello album and any of the other stuff I work on, check my dev blog at www.joostvandongen.com.
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like
Latest News


Trending



Featured Blogs






