




















Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
GAN-Supported Concept Art Workflows
We all love the fact that computers can execute annoying work for us. Work we already know how to do. And now there’s a new kid in town: Style-GAN’s - short for Generative Adversarial Networks that can support the creative vision of your team.
19 Min Read

Preface
Introduction
Applications
Character Concepts
Portraits
Environments
Keyframes, Storyboarding, Scenes and Illustrations
Textures and Design
Abstracts and Art
Pitfalls
The Future
Preface
We all love the fact that computers can execute annoying work for us. Work we already know how to do, work that is repeatable and, often, also repetitive.
For the past few decades, new processes such as procedural generation have been helping us achieve diverse results with minimal input, leaving us to focus on being creative. Be it in the shape of procedural level generation of early rogue-like games, procedural nature such as Speedtree or, lately, the vast possibilities of procedural texturing with noise procedurality as seen in Substance Designer.
And now there’s a new kid in town: GAN’s - short for Generative Adversarial Networks.
Neural networks that generate new data and in the case of so called StyleGAN’s it creates images or sequences.
These machine learning frameworks are making two AI’s play against each other to test and learn what would be considered to be a realistic result. This is based on the library you are feeding the network.
When we look back at the early versions of GAN’s, they were quite rudimentary and the results more than questionable. At least nobody would have said; “Let’s use this scary DeepDream image of a dog knight for our next big video game production.”
(Credit Alexander Mordvintsev / Google DeepDream 2015 ©)
However, even during these clumsy beginnings, bigger companies were already seeing GAN’shuge potential. And now the time has come in which not only big companies are able to use neural networks to support their production, but it is also available, and affordable, for small studios, freelance artists and general consumers.
This change opens up huge opportunities. Endless ones. It also comes with some potential dangers and pitfalls that we as creatives should be aware of. In the following I will give an overview of how GAN’s can be successfully used, what the future might bring and what all this will mean for our job in the next 5 years.
Introduction
Let’s take a small trip back in time. This is an image I created one and a half years ago with a GAN website where you could input color-coded areas that defined the property of the environment. You could paint where you wanted clouds, a river, a wide mountain range or even a building with four rows of windows and a large door.
You could then click the generate button and “magic” would happen. I was stunned when I first tried it, as were most of my colleagues and friends after I shared the results.
For the first time it felt like these networks had become so powerful that a production would actually benefit from them, instead of hours of work, this tool could easily spew out one realistic landscape concept after the other in mere minutes. At around the same time, a team at NVIDIA was working on their own tool which also allowed you to change the overall light mood and time of day alongside the segmentation map input I just mentioned.
https://www.youtube.com/watch?v=p5U4NgVGAwg
A couple of months later I saw a great talk by Scott Eaton who was building a deep-learning AI network and feeding it with sets of photos he shot of performers. He would use this self-built network to create abstract human shapes which used his line drawings as input.
He eventually reached a point of experimentation where he trained the network on less figuratively modeled cubes and shapes. After the AI learned to interpret its new library, Scott took the results which, once again, were based on his linear drawing input and made them into physical sculptures .
https://www.youtube.com/watch?v=TN7Ydx9ygPo
Skip forward in time to about two months ago, the beginning of a new production cycle in our studio. Wonderful pre-production time. And as is often the case during early development, we had a little bit more freedom to experiment, to get back to the drawing board and find cool new ways to not only create crazy visuals but also re-think our art departments pipeline. Pre-production is always a good time to try and pinpoint time-consuming chores and how to overcome issues of terrible software bridging, or even just generally optimize everyone’s workflow by a bit.
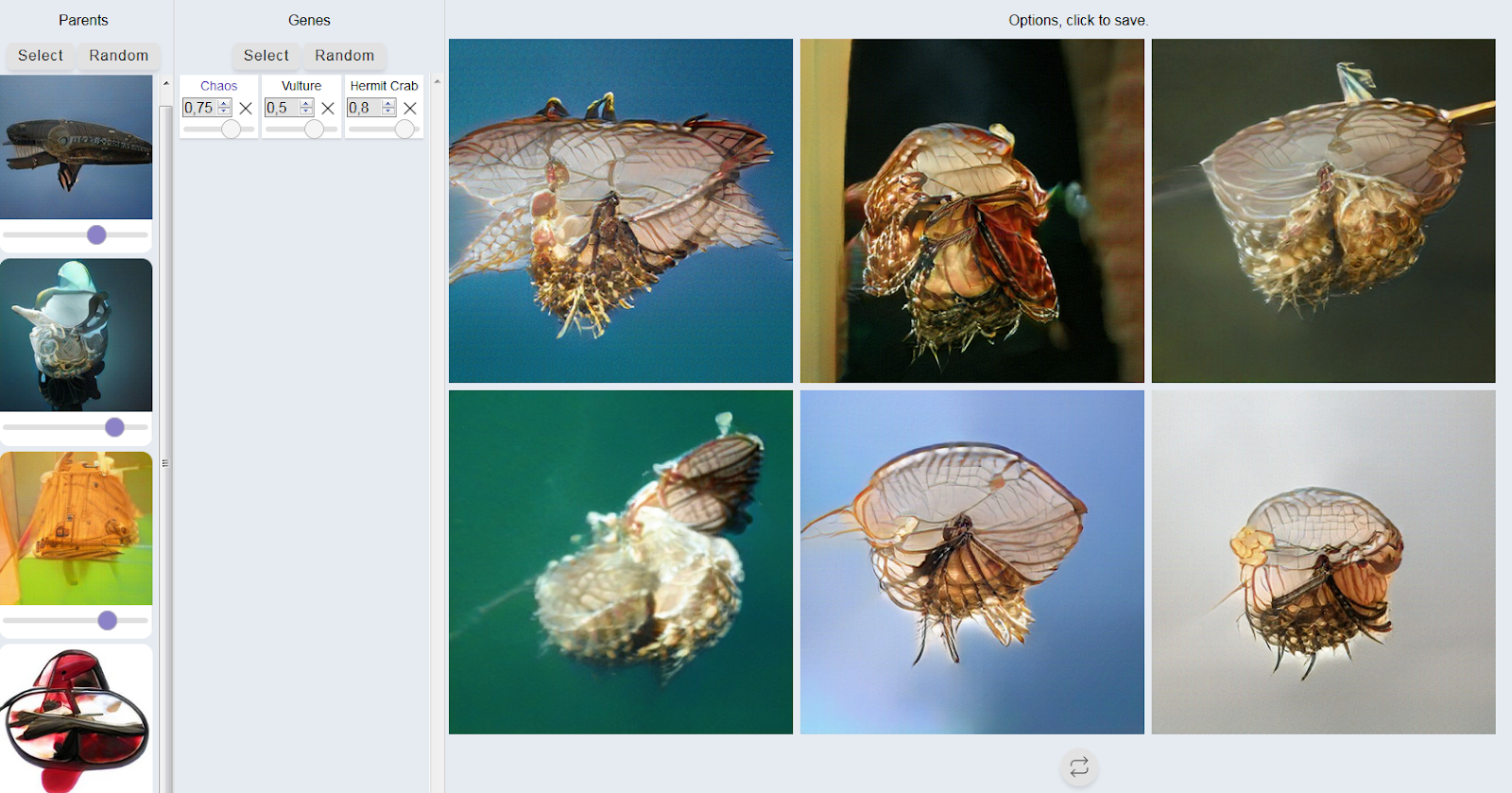
With this in mind I thought of a website that I had used a while ago, called Ganbreeder. This page allowed you to input your own images and “cross-breed” them with existing images from other creators or its library. Since then the website was renamed to Artbreeder, and now hosted a wide array of GAN’s trained for specific purposes such as environments, characters, faces or the more specialized categories like anime and furry heads.
So I took a real deep-dive into these generators.
It took me about two days of using the tool to stop being disturbed by my own creations. Don’t get me wrong, I loved the tool and quickly became addicted to it, but the results also gave mean eerie feeling of unease, of uncanny-ness sometimes. Once this period passed, I showed my results to the team and we we began discussing the possibilities this crossbreeder offered.
Applications
Let’s be real. If you were to properly set up and train your own neural network, the options you have are limitless. And you can create them much more specifically geared towards a certain purpose, not only by what library you train the system on, but also by how you want your input methods and variables to shape the output.
Realistically though, for most of us without a server farm in the basement or proper programming/scripting skills, we are limited to website options and fiddling around with the results we can get there.
For our production I found a couple of major aspects that already proved to be really helpful. Not only as time savers, but also to get new creative ideas in. Ideas that one might not imagine on their own.
Our project needed us to create concepts which felt really alien and unexpected, and so far this is one of the aspects in which GAN’s show their strength. They are able to deliver results which appear realistic at first glance, but can create weird,unusual shapes and designs if you allow them to.
Here is a break-down of several use cases for GAN’s and how I worked with them up until now.
Character Concepts
So far I have very mixed feelings with the current state of usability for character concepts. The reason being; Characters are the core of any film, game or any other storytelling medium. They are carefully crafted and rely on so many aspects coming together that they need to follow very specific rules and are rarely arbitrary or random. This of course is only true for important main characters, with a story and background.
For these cases it’s more than necessary to do a lot of additional work after gathering the output from a GAN. You often need to change perspective, morph some parts and collage others together. And then, of course, you re-iterate after talking to the designers, writers or a tech-artist. It can almost take as long as the regular approach to character design, either with sketches or a photo-bashing approach.
Another strong suit of these networks is for costume and clothing ideas. Here I see the benefit of being able to start with something completely weird but cool and toning it down in the process so it becomes readable and sensible for the purpose.
Another great opportunity are background characters and aliens. They are often freed from strict rules or even benefit from being unrecognizable.
Portraits
I struggled a lot with this one. The results are almost too good at times. And I was scared and disturbed after a human face that I’d just created smiled back at me with the confidence of being as real as the spilled coffee on my desk. The results are absolutely production ready. I have no doubt that in a couple of years a lot of released concept art for realistic games like The Last Of Us will drop on Artstation and nobody will ask or be surprised how these images were created so realistically.
Even more stylized or abstract faces are an easy task for a well-trained network and allow artists to quickly see how a specific character would look in a different style. Or how a character would look with more beard, or gentler features, or if their face were twice as wide, or with a different hairstyle.
In this realistic example I used a StyleGAN for the face, as it allowed me to quickly create a ¾ view of the face, show the character smiling, or to create alternative looks for the person. For the rest it was faster and more crisp to rely on traditional photobashing and overpainting it.
Environments
Next to portrait creation, environments are where the GAN’s really shine. Whether you use a mixer breeder such as Artbreeder or a segmentation map based approach such as the NVIDIA GauGAN, the results are phenomenal and really free up the creativity and speed when it comes to thumbnailing mood sketches and such.
They still require a bit of work after you are done generating, but since nature is very forgiving in terms of the uncanny valley effect, you can get near-perfect looking results quickly and most importantly, a vast variety. This is true for very realistic landscapes as well as weird alien planets.
The only downside is integration of buildings in landscape. A far away city or skyline works well, but if you are aiming for a downtown LA vibe and want to retain a lot of fidelity and realistic detail, it might be better to train a network specifically for that purpose.
Keyframes, Storyboarding, Scenes and Illustrations
If the technology reaches a level where we will input sentences like; “A man in a blue shirt is fighting a superhero in Italy” and the result is a functioning visualization we will be a lot closer to covering these disciplines as well. At the moment we are not quite there yet. There are first Text to Image API’s, but to be honest they still suck.
(Deep AI, Inc. 2019 ©)
The complexity of creating a successful scene for an entertainment production is insane. As a creator you think about composition/blocking, camera angle, motion, lighting, the previous and next frame and the scenes context. This is just too much for the current GAN’s,and will take Earth’s computer geniuses another couple of years until we will see adequate results. Best time to become a storyboarding artist it seems.
Textures
I started creating a couple of bases for textures to test out the capabilities. When it comes to finding different ideas for textures, using a GAN can be quite good, though the accuracy sometimes lacks a great deal of fidelity in the details and will start to “look generated”. But since Substance Designer already exists and is probably working on solutions to integrate specifically trained neural networks, it’s only a matter of time until we see similar features.
Designs
For designs, I once again fell in love with GAN’s. The more free you are with your input the better. It liberates you from your comfort zone and allows you to think beyond what you usually do. Organic designs work a tad better than technical ones. Especially sharp edges feel like something that needs to be specifically trained, so the smaller the library of a network is, the more accurate and technical/sharp your results will be. They will however lose a bit of the unexpected chaos factor that you might sometimes want.
Abstracts and Art
The contemporary art world might need to reconsider where art specifically starts and how much of it is bound to the recipients enjoying it, versus the creative process of the creators behind it.
You are able to create something that looks like a painting with ease and nobody will doubt that the printed version in your living room is a forgotten Kandinsky or a modern abstract flower bouquet painting.
Art lives with its context and meaning. Often through the artist and what he or she stands for and committed their life to. If you use a GAN to support your creative workflow it can be used as a great tool to come to results that empower your voice. It is just a dangerous balancing act if you are letting the computer take over and just consume and republish what it did by itself, without authoring or shaping it, even if you gave it an initial input.
Pitfalls
It’s important to mention that these GAN’s are by no means the magical “make good art” button some people have been hoping for for years. It still takes someone that knows what they want and what to do with it after. An untrained individual can of course create cool images much faster and the gap between an image from somebody that has 10 years of experience creating art and somebody that just started is smaller. However, you will still need to know about the basics of design, such as composition, colors and light, ratios within designs, etc.
Another big factor is the aftercare. After you create an image you want to prepare it for the pipeline, make it production ready. And this relies on skills and experiences you only get by working in the respective fields. Such as; What animation requirements does the design need to follow? Is a single piece of design coherent with the overall products goals or visual guidelines?
The Future
I spoke with Joel Simon, the creator of Artbreeder, about StyleGAN’s and what the future might bring:
Hi Joel, great you had time for an interview.
Looking back, what was your first connection to GAN's and how did you start working on one?
I actually had no experience with GAN's prior to working on Ganbreeder (what the earlier iteration of Artbreeder was called). While I had some experience with other machine learning methods, my background and interest was really in genetic algorithms and experimenting with tools for creative expression. After I started learning more about GAN's and seeing the results of BigGAN, I realized they would be a perfect fit with interactive evolutionary algorithms.
How do you think current GAN's will evolve - what is next up in terms of potential features?
I am not a machine learning expert by any measure, but there are a few trends that will likely continue. One that I'm excited for is that video generation is increasingly improving in accuracy and level of control. Although, a lot of what's interesting may not be GAN's but other machine learning algorithms. Ultimately, iterative improvements are easy to predict but big developments are not. It also depends on what the big companies decide to put their resources on, something like BigGAN costs tens of thousands of dollars in training time.
What is your opinion on AI-supported workflows? Do you see dangers or opportunities?
Absolutely both, and I think that's true for any technology. Regarding workflows, I divide the tools or approaches into two categories. Those that respect user judgment and those that don’t. For instance, consider a tool that may claim to have trained the perfect model to optimize your advertisement design […] to maximize impact and they tell you what to do. These become black boxes that will most likely lead you astray. For Artbreeder, it always leaves you in the driving seat and merely suggests things and gives you the levers to explore and play around.
There is the risk that one may get too removed from the medium itself, and that's a debate architecture had with CAD - for an inspiration tool I think it's very powerful
Looking into the future, what are trends and new developments on the horizon that will shape the way we work?
I like to compare things to how they already are. New technologies can abstract certain things and remove busy work, and I think that can enable a kind of "directorial creativity" if done right. A creative director can design in the medium of words to everyone else ("I don't like this", "show me more of that", etc). And while they are further removed from the medium, I don't think it's fair to say they are less creative. A film director is just operating at a higher level of abstraction but, if anything, is an extremely high level of creativity.
So I hope the future is allowing anyone to do that.
(Interview: Joel Simon, Max Schulz Sep. 2020)
â–
Imagine being a small indie team. 10-20 years ago this would have meant you potentially wrote your own engine. Your artists would have been able to create a couple of lowpoly models a day, sitting there for hours UV-unwrapping or painstakingly painting textures before using CrazyBump for an “ok” looking normal map. Your concept artist with carpal tunnel would render cloth folds for hours so the character artist could interpret it correctly.
These times are already over thanks to more advanced procedural modeling and texturing tools, generated VFX, photogrammetry, kitbashing and photobashing.
Did it make the industry faster? Yes.
Did it make the industry better? Maybe it made it different. Definitely more diverse.
When sitting in front of a model and pushing vertices by hand, you have time to think about what you create, have time to think about how the player will interact with what you build. When you are designing stylized tree branches for 5 hours, it’s 5 hours that you look at these trees, analyze the sketches, maybe come up with a crazy idea on what else you could do with its creative potential.
By no means do I want to imply we should waste our time on repetitive and un-innovative work, but the faster processes are becoming, the faster somebody is expecting them to be done too.
There is a fantastical feeling connected to being a creative, being a creator. Your head filled with wild ideas. Your heart warm with passion. Being a creative is a lot about imagining things in your head and then transferring it on paper or onto the computer.
When we don’t allow ourselves to think and linger anymore, to play out silly ideas, then we fall victim to consuming and copying that which is already there.
If you start up your GAN and click a couple of buttons, the likelihood of you becoming a consumer of the GAN can be high. So it helps to always ask yourself what your goals are in the process. Think about concepts first, be thoughtful with your input and ask yourself if it follows your vision, only then you should start to generate amazing results.
And similarly to globalization, there is a danger of designs becoming too streamlined through internationalization of mass culture. If a lot of people are feeding the net the same thing, the result will also be arbitrary or homogenous.
In the future we will work more and more with this AI-support.
Only recently a paper was released that reads out a 2D image, or photo of a human and generates a relatively accurate 3d model from it. This one is called PIFuHD.
(Shunsuke Saito, University of Southern California / Facebook Reality Labs / Facebook AI Research ©)
https://shunsukesaito.github.io/PIFuHD/
Combine this with a Character-GAN; You quickly create a character concept, let the PIFuHD algorithm run over it, texture-project the concept onto front and backside. Use the black and white concept to generate a normal map for it. Polish a couple of edges on the model before quick-rigging it, so you can search online for some pre-recorded mo-cap animations and put it in engine. A couple of hours and you have a fully functioning in-game model ready with animations and everything.
Using advanced randomization algorithms you successfully created a random character.
It’s great what we are enabled to do and what we will be able to achieve very soon. But with everything we work on, we should ask ourselves what we are doing and why we are doing it.
So when we start the creative process let’s live up to it and embrace our own creativity, value the process as well as the result, see where we can make mistakes, can grow, bring in our individualism, ask our inner child for ridiculous nonsense and most of all, enjoy ourselves.
Max Schulz, 2020
----------------------------------------------
Bio
Max Schulz is a German-based concept artist and art director that started in the games industry 12 years ago. He worked on titles such as Path of Exile, Injustice 2, the movie Wonderwoman and the upcoming game release of Suicide Squad.
Keywords:
#ai #GAN #neuralnetwork #proceduralgeneration #PIFuHD #artificialintelligence #deepdream #deeplearning #conceptart #videogameproduction #workflowimprovement #StyleGAN #Artbreeder #JoelSimon #MaxSchulz
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like
Latest News


Trending



Featured Blogs






