Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Sponsored Feature: CPU Onloading - Leveraging the PC Platform
In this Intel-sponsored Gamasutra feature, Josh Doss explains how the major technology company is investigating onloading with regard to video game development - the concept of "increasing the platform performance by using CPU resources to do typical GPU-assigned tasks".
10 Min Read

Sponsored by Intel
[In this Intel-sponsored Gamasutra feature, Josh Doss explains how the major technology company is investigating onloading with regard to video game development - the concept of "increasing the platform performance by using CPU resources to do typical GPU-assigned tasks".]

FPS Matters
During the optimization phase of your game's development, it's all about the frame rate. Whether you're increasing visual effects and quality to maximize the user's visual experience or dialing down your GPU demands to increase the responsiveness of the game, frame rate is key.
Onloading is a concept we're currently looking at within Intel as a means to increasing the platform performance by using CPU resources to do typical GPU-assigned tasks. This may be especially useful when targeting platforms with processor graphics as these are typically modest in terms of performance when compared to high end discrete graphics cards.
Several years ago discrete graphics-card vendors began suggesting that developers move typical CPU workloads to the graphics solution [Figure 1][Harris06]. Despite the advances in graphics hardware both in the integrated and discrete space, it's still relatively simple to turn up your effects to become graphics-bound even today.
Post processing effects have a significant impact on the quality of your title and have heavy texture and fill requirements. High resolution displays are the norm with use of multiple displays increasing [Valve11].
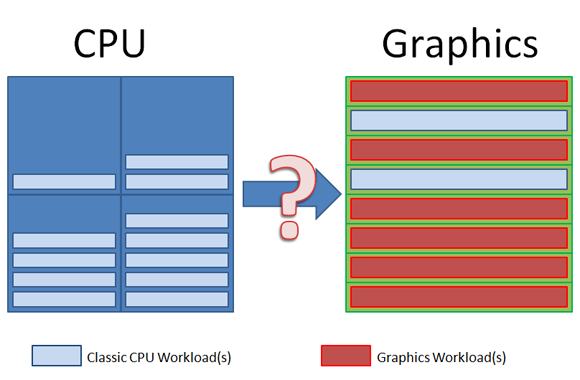
Figure 1: Moving CPU workloads to the graphics device
The CPU can . . .
CPUs are increasing in total throughput at an exponential rate. With increases in core count and wider vector units, we can start looking at how the CPU can assist with some typical graphics workloads. Prior to taking part in this exercise, it is important that we first ensure we haven't moved our typical CPU workloads -- such as Physics and AI -- to the GPU.
Take a look at your game when you start the optimization phase and see where the bottlenecks are. If your game scales well across multiple cores and threads and provides the best user experience on the platform, you may not have an opportunity for Onloading. If you're graphics-bound, have your Physics and AI workloads already on the CPU, and are seeing opportunities for higher CPU utilization, CPU Onloading may offer potential gains.
Along with the opportunities outlined above, there are challenges that exist when considering using the CPU to perform some typical GPU-accelerated workloads. Of chief concern are lack of fixed function hardware, such as texture units and a rasterizer.
Workloads requiring heavy rasterization or texture filtering are not the best candidates. In addition, there's currently no mechanism within Microsoft Direct3D* to avoid copying the working buffer which results in significant overhead. We can work around this by double buffering our render loop.
A significant advantage to using the CPU for graphics workloads is that they can be implemented without the constraints and limitations imposed by current graphics APIs. Irregular data structures, the use of desired programming languages along with large caches provide additional opportunities for flexibility and performance.
If we're smart enough to look at balancing the entire platform, [Figure 2], we're also going to need to ensure we utilize our available threads and vector units as much as possible. Fortunately both parallel and vector programming have gained significant traction in recent years, with tools and knowledge pervasive across platforms.
Developers familiar with console programming should be well versed in these concepts. Intel provides several tools to aid developers in utilizing our processors' resources including the Intel® VTune™ Amplifier XE.
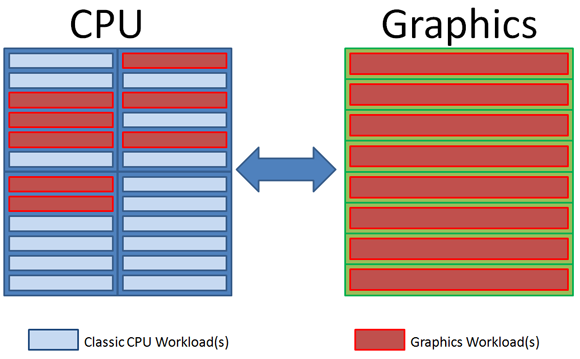
Figure 2: Leverage the Platform Holistically with CPU Onloading
CPU Onload Techniques
We currently see four primary modes of CPU Onloading and are working on identifying workloads for each one.
Intra-frame CPU Onloading is the use of the CPU to perform a portion of the work while the GPU performs another portion of the work and sharing data.
Screen space CPU Onloading is the use of the CPU to do a post rendering effect after the GPU has rendered the contents of a frame.
CPU Onloaded Data Generation is the pre-generation of heat maps, shadow maps or other inputs for consumption by the GPU.
Full Pipeline CPU Onloading is the duplication of a 3D raster pipeline on the CPU for asynchronous generation of slow moving or infrequently updated components of your game.
Intra-frame CPU Onloading is arguably one of the most useful approaches, with the CPU generating a component of a frame such as the UI, particles, etc. and then the GPU leveraging this component in the form of an uploaded buffer. This approach requires buffered rendering as there is currently no mechanism within current generation graphics APIs for cooperative rendering within a frame.
Using intra-frame CPU Onloading a developer can easily tune for platform utilization by using performance heuristics to determine the cost of these intra-frame workloads and tuning for a specific CPU/GPU configuration. A good example of intra-frame CPU Onloading is moving your particle system to the CPU.
It's possible to get good performance in a particle system with a direct quad rasterizer using tiling and binning to generate multiple tasks for parallel processing along with leveraging the Single Instruction Multiple Data (SIMD) units to process and render up to 8 particles at once.
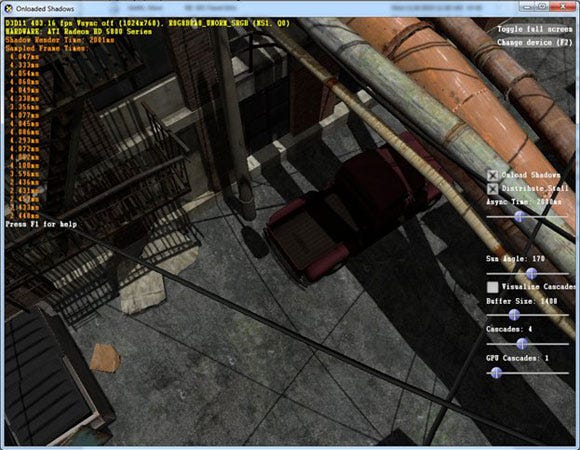
Image 1: The Onloaded Shadows sample illustrates a Full Pipeline CPU Onloading technique
Screen space CPU Onloading is also a potentially interesting approach as it can be easily pipelined n-1 frames deep and post and other full screen effects have a high GPU cost. In general the approach when performing screen space Onloading is to render the scene to a render target which is then read by the CPU. The surface is separated into tiles to enable small consumable chunks for maximum parallel workloads.
We use tasking for asynchronous processing of the data. In order to fully maximize the potential CPU performance on this workload it's important to vectorize the data to keep the SIMD lanes busy and perform multiple operations with a single instruction. The CPU also allows us to provide further optimization with its flexibility and cache layout to perform tasks like tone mapping via an accumulator.
CPU Onloaded data generation is an area we haven't yet done much work in but we believe there is potential for custom rasterizers for shadow map generation on the CPU along with heat generation, etc.
Full pipeline CPU Onloading is the most naïve approach to Onloading and entails using a CPU software rasterizer to render asynchronous components of a scene. The sample “Onloaded Shadows” performs this type of Onloading by using the Microsoft* WARP 10 rasterizer on a single core [Image 1].
Due to the poor mapping of graphics specific APIs like Direct3D* 10 to CPU architecture this approach is the least efficient and care should be taken when evaluating this type of usage to ensure the platform performance is a win.
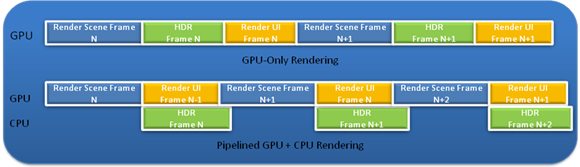
Figure 3: Pipelining
Onloading in action: HDR Post Processing
As an example of Screen Space CPU Onloading, we can look at HDR Post Processing. We're able to get the performance of this implementation to around 2ms per frame on today's high end CPUs with an asynchronous copy operation done that limits our minimum total frame cost to 3.5ms. Latency hiding is accomplished by pipelining the work across the CPU and GPU so the EUs are working on rendering the next frame while the CPU is performing the post effects. [Figure 3]

Image 2: Tiling
Previously the importance of tasking and vectorizing your code for maximal performance on the CPU was addressed. Applying these concepts to screen space effects is fairly straightforward. In keeping the workload fairly comparable in terms of performance measurement across both devices we'll use a float16 render target.
This render target is copied to the CPU where the processing and filtering occurs. Tasking enables us to easily break up the work of a full screen filtering pass by breaking up the buffer into tiles [Image 2]. Each tile can be worked on independently and each stage of the algorithm can be set as a dependency.
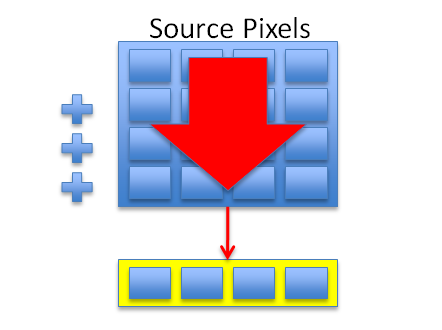
Figure 4
Leveraging the SIMD capabilities of the CPU can maximize our performance. By using the SIMD units we can perform an operation on multiple pieces of data with a single instruction. We can identify opportunities in this particular algorithm beginning with the down-sample step.
We take a 4x4 block of 16 pixels and begin down-sampling the pixels per component using vector addition [Figure 4]. SIMD data is processed “vertically” [Tonteri10] so we need to take a set of four of these vertical (partial) sums and perform a transpose to maximize SIMD utilization.
One additional sum after the transpose gives us our final 4 sums of 16 pixels each (64 original pixels). To complete the down-sampling, multiply by 1/16th for the average.
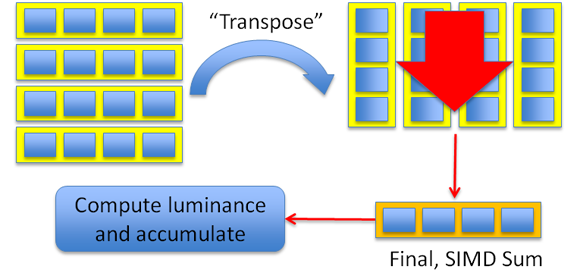
Figure 5
A similar approach can be taken to calculate the luminance using SIMD as well on four (SSE) or eight (Intel® AVX) averages. The CPU's flexibility is an advantage when calculating the luminance. The classic pixel shader technique requires rendering a full-screen quad into a “luminance” render target which is then down-sampled; potentially needing several passes. Using the CPU, you simply compute the luminance and accumulate to a per-tile global.
Compute the remainder of your post processing (i.e. blur, tone-map and bloom) using similar methods. Once the post processing is complete copy the result to the back buffer. You've now Onloaded your post processing and have freed up that time for the graphics hardware to perform more graphics work!
Now Go Experiment
Now that you've read through a CPU Onloaded workload and have a grasp of the basic techniques, we'd like to suggest you do some experimentation on your workloads and explore these techniques further.
While this is a reasonable introduction to CPU Onloading, the possibilities are vast and maximum potential can be realized when using workloads that have been carefully evaluated for their implementation efficiency on the CPU versus your graphics target.
Acknowledgements:
Doug McNabb was a significant reviewer and contributor to this article in terms of illustrations and core technical content. Additional thanks to Zane Mankowski, Steve Smith, Doug Binks and Artem Brizitsky for their work on developing the Onloaded Shadows sample.
Author Bio:
Josh Doss began his career at 3Dlabs enabling some of the first applications to leverage high-level shaders. Josh joined Intel in 2006 to write some of the first software targeting the Intel® architecture (codenamed Larrabee) and is now working on a team that creates developer samples targeting upcoming Intel platforms.
References:
Doss, J & Mcnabb, D. Increase your FPS with CPU Onload [PDF Slides]. Slides presented at GDC 2011, San Francisco CA. Retrieved from http://software.intel.com/en-us/articles/intelgdc2011/
Harris, M. GPU Physics [PDF Slides]. Slides presented at SIGGRAPH 2006, Boston MA. Retrieved from http://developer.download.nvidia.com/presentations/2006/siggraph/gpu_physics-siggraph-06.pdf
Steam Hardware and Software Survey. (March 2011). Retrieved from http://store.steampowered.com/hwsurvey
Tonteri, T. (2010). A Practical Guide to using SSE SIMD with C++. Retrieved February 22nd 2011 from http://sci.tuomastonteri.fi/programming/sse/printable
About the Author(s)
You May Also Like
Latest News


Trending



Featured Blogs






