Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
Scaling a Game Simulator with Cloud DataFlow
Procedural content generation needs automated playtesting, here’s one approach to explore.
9 Min Read

Cloud Dataflow is a great tool for building out scalable data pipelines, but it can also be useful in different domains, such as scientific computing. One of the ways that I’ve been using Google’s Cloud Dataflow tool recently is for simulating gameplay of different automated players.
Years ago I built an automated Tetris player as part of the AI course at Cal Poly. I used a metaheuristic search approach, which required significant training time to learn the best values for the hyperparameters. I was able to code a distributed version of the system to scale up the approach, but it took significant effort to deploy on the 20 machines in the lab. With modern tools, it’s trivial to scale up this code to run on dozens of machines.
It’s useful to simulate automated players in games for a number of reasons. One of the most common reasons is test for bugs in a game. You can have bots hammer away at the game until something breaks. Another reason for simulating gameplay is to build bots that can learn and play at a high level. There’s generally three ways of simulating gameplay:
Real Time: You run the game with the normal setup, but a bot simulates mouse clicks and keyboard input.
Turbo: You disable rendering components and other game systems to run the game as fast as possible. If you’re game logic is decoupled from the rendering logic, this can result in an orders of magnitude speedup.
Headless: The fastest way of running simulations is by disabling all graphics and rendering components in the game. With this approach, the game can be called as a function, and the results of running the simulation are returned by the function.
For the AI course, I used the turbo mode with each AI agent running independently. If I were to repeat the experiment, I would use a tool like Dataflow to scale the system using a managed environment. This post discusses how to use Google’s Dataflow tool to implement this logic. It is well suited for long running tasks that can run independently.
If you’re intersted in building your own Tetris playing agent, this paper by Bohm et al. presents an interesting approach for creating a strong player. They define a number of metrics that are used to determine how to make the best move, such as the altitude and well differences shown below.
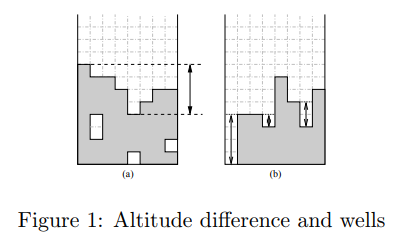
Heuristics used by Bohm et al.
This is no longer state of the art for Tetris, but it’s a great starting point. Tetris is also a good problem to write AI for, because it’s not too complicated to write a Tetris game from scratch that you can then use for simulating AI players. The full code for this simulator is available on GitHub.
The Tetris code is from a class project I wrote over 10 years ago, and I would not recommend using this as a starting point. It was interesting looking back at some of my old code, and I had to make a few modifications for it in order to get it to run in a headless mode for Dataflow. I already had decoupled the game logic and graphics threads for the game, but I removed a number of static object references that would not work in a distributed environment.
Setting up Dataflow
If you’re familiar with Java and Maven, it shouldn’t be too much work to get up and running with Cloud Dataflow. The first step is to define your dependencies in pom.xml:
com.google.cloud.dataflow
google-cloud-dataflow-java-sdk-all
2.2.0
Once you’ve added this dependency to your project, you’ll be able to build and deploy Dataflow jobs. I used Eclipse for this project, but intelliJ is another great IDE for authoring Dataflow tasks in Java. More detail on setting up Dataflow is available in my past post on scaling predictive models.
Simulating Gameplay with Dataflow
After modifying my old code, I now have a game simulation that I can use as a function (method) that runs in a headless mode and returns gameplay statistics when complete. Once you have a game set up in this way, it’s straightforward to use Dataflow to run thousands of simulations. I defined a DAG with the following operations:
Create a collection of seed values to use as input
Run a simulation for each of the seeds
Save the gameplay results to BigQuery
The first step is to create a collection of seeds that are used as input to the game simulator. It’s nice to have a game simulation with repeatable results, in order to QA and to measure performance across different gameplay agents. I used this step as a way to specify how much work to perform. If a small number of seeds is instantiated, then a small number of simulations will be executed, and if you make it larger more simulations will be performed.
Random rand = new Random();
ArrayList seeds = new ArrayList<>();
for (int i=0; i<10; i++) {
seeds.add(rand.nextInt());
}
I used the following code to set up the Dataflow pipeline and pass the seeds as input to the pipeline process.
Simulator.Options options = PipelineOptionsFactory.
fromArgs(args).withValidation().as(Simulator.Options.class);
Pipeline pipeline = Pipeline.create(options);
pipeline.apply(Create.of(seeds))
The next step is to use the passed in seeds as input to game simulations. The outcome of this apply step is that the input seed value is used to create a TableRow object that captures summary statistics for gameplay. The seed is passed to the game object and the result is the number of lines completed by the agent. I also recorded the hyperparameters used by the agent when determining which move to make.
.apply("Simulate Games", ParDo.of(new DoFn() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
Integer seed = c.element();
// play the game
Game game = new Game(seed);
int levels = game.runSimulation();
// save the results
TableRow results = new TableRow();
results.set("levels", levels);
results.set("heightFactor", game.getHeightFactor());
results.set("balanceFactor", game.getBalanceFactor());
results.set("holeFactor", game.getHoleFactor());
// pass the stats to the next step in the pipeline
c.output(results);
}
}))
The final step is to save the results to BigQuery. This is a straightforward step to perform in Dataflow, but you need to first define a schema for the destination table. The code below shows how to perform this step.
.apply(BigQueryIO.writeTableRows()
.to(String.format("%s:%s.%s", PROJECT_ID, dataset, table))
.withCreateDisposition(BigQueryIO.Write.
CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(BigQueryIO.Write.
WriteDisposition.WRITE_TRUNCATE)
.withSchema(schema));
We now have a Dataflow graph that we can run locally to test, or deploy in the fully-managed cloud environment to run at scale. The result of running this DAG is that a table will be created in BigQuery with summary statistics for each of the game simulations.
Running the Simulation
You can run Dataflow locally or in the cloud. It’s easiest to test locally and later scale up. You can test the complete pipeline by setting the number of simulations to a small number, such as 3, and then running the pipeline. Since we’re saving the results to BigQuery, we’ll need to specify a temp location for the pipeline. You can do this by providing a runtime parameter for your java application, such as:
--tempLocation=gs://ben-df-test/scratch
After running the pipeline, you should see a new table created in BigQuery with your simulation results. The next step is to scale up the number of simulations being performed.

The operations in our Dataflow DAG
To run your simulations on the cloud, you’ll need to specify a few more runtime arguments. I set the maximum number of machines to 20, in order to speed up the process from the default value of 3. Please keep in mind that using more machines can get pricey for long running operations.
--jobName=level-sim
--project=your_project_ID
--tempLocation=gs://ben-df-test/scratch
--runner=org.apache.beam.runners.dataflow.DataflowRunner
--maxNumWorkers=20
Running this simulation for 1,000 seeds resulted in the autoscaling chart shown below. My job scaled to 14 works before completing all of the simulations and saving the results.
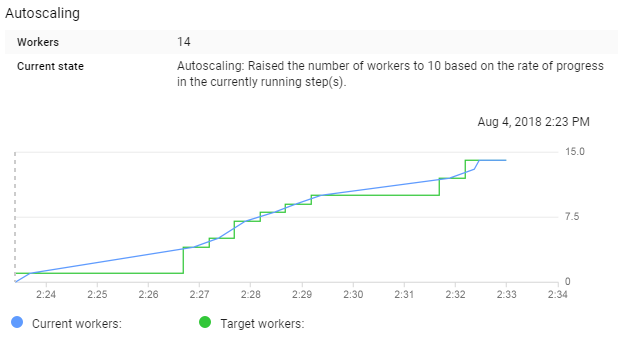
Autoscaling to meet the simulation demand
Once completed, I had gameplay statistics for 1,000 iterations of my Tetris playing agent.
Simulation Results
The results are now available in BigQuery. With each simulation, I made minor changes to the hyperparameter values, as shown in the table below:
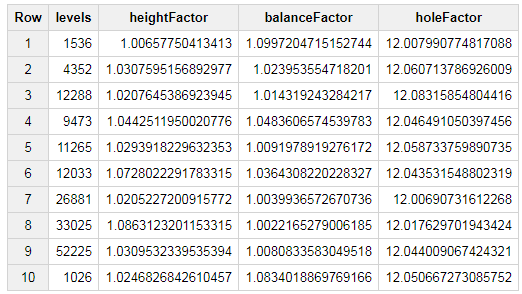
Simulation results in BigQuery
We can now look for correlations in the data, such as determining if certain factors are influential for the number of lines cleared:
select corr(holeFactor, levels) as Correlation
,corr(holeFactor, log(levels)) as logCorrelation
FROM [tetris.sim_results]However, there was no signal in the results, R = 0.04 for the logCorrelation. Since the data is available in BigQuery, we can also use Google Data Studio to visualize the results:
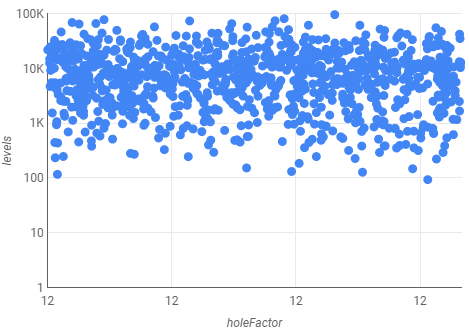
The visualization confirms that there is no correlation in the data, but I also used a small range of values for the factor.
Conclusion
Dataflow is a great tool for scaling up computation. It’s designed for data pipelines, but can be applied to almost any task, including simulating games.
Ben Weber is a principal data scientist at Zynga. We are hiring!
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like
Latest News


Trending



Featured Blogs






