Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
In this technical article, MoMinis programmer Itay Duvdevani explains how he and his colleagues solved what should have been a very simple sorting problem creatively, and upgraded their smartphone game engine in the process.
October 3, 2012
20 Min Read

Author: by Itay Duvdevani
Having issues with performance on your smartphone game? In this technical article, MoMinis programmer Itay Duvdevani explains how he and his colleagues solved what should have been a very simple sorting problem creatively, and upgraded their smartphone game engine in the process.
Working on the phone side of the MoMinis Platform is an interesting job. Since our content developers work mostly on the Simulator for game mechanics, bugs and performance tuning -- we always get a little nervous when a title becomes ready to start testing on actual phones.
Compilation of a game can reveal bugs (either in the simulator or the compiler) that will break the game's logic, or performance problems that aren't simulated in the Simulator correctly.
When a game works in the Simulator, but not on a phone, it usually finds its way to my team pretty quickly -- As compiler developers, we're the only ones that can pinpoint the problem.
The Problem with Jelly Jump
Our content developers were working on a new title -- Jelly Jump. After several weeks of development, and a week or so from release, the game became mature enough to start testing on actual phones. On higher-end phones, the game ran smoothly and was actually very fun. However, on mid-range and low-end devices, we experienced random frame rate jitters that made the game unplayable. My team got to handle the situation.
We observed the problem on a relatively capable device (800MHz Snapdragon with Adreno 200 GPU). This wasn't a low FPS problem, but FPS jitter that occurred every few seconds, in what looked like random occurrences. The game would run at 40-50 FPS, then dip to 10-5 FPS for a second or so, and then continue.
My team was tipped off by the content developers about some testing they'd done, which showed that removal of graphics assets made the game run better.
At compile time, the asset-generation stage is responsible for distributing the game's assets to texture atlases. Since this is an automatic process, it uses several heuristics to predict which objects will be drawn together, to minimize texture swapping. These heuristics are currently pretty basic, and rely on static analysis only -- we don't have performance-guided optimization facilities as of today. We suspected the assets were being grouped in an inefficient manner, causing texture thrashing due to memory exhaustion every time certain objects were being drawn.
This was a problem. We had no "magic solution" or even a workaround for this -- we didn't even have a quick 'n' dirty solution. The game simply had too many graphics for our asset-generation pipeline.
After spending a few days figuring out how to tackle the problem, yielding nothing practical for the time we had -- we started doubting our assumptions, and tested whether there even was a problem with the textures. We configured the asset-generation pipeline to downscale all the graphics to a quarter of their size, making all the game's assets fit in a single texture. To our surprise, the game ran just as bad (and was very ugly).
That meant that the game's logic was the bottleneck. We tried profiling the game with the Dalvik profiler. Unfortunately, profilers are very useful when you debug a low-FPS problem, but almost useless when you debug an FPS jitter problem, unless you can predict exactly when your game is going to jitter -- and of course, if we knew that, we probably would have known what the problem was.
Sitting down with the content-developers, hearing about the game's logic -- and using our intuition to plant some debug prints in the code, we came to a surprising conclusion -- our Z-ordering code was misbehaving when a large amount of object were being created in a single logical iteration!
Why Keep Things in Z-Order?
 It should come as no surprise that some of the tasks our game-engine is responsible for, except driving the game's compiled logic, is to draw pretty things to the screen, and respond to touch input.
It should come as no surprise that some of the tasks our game-engine is responsible for, except driving the game's compiled logic, is to draw pretty things to the screen, and respond to touch input.
For a 2D engine like the MoMinis Platform, objects need to be arranged according to their Z-order and traversed (either in a back-to-front or front-to-back order), to decide which objects receive touch input, and which get drawn first.
The Touch Handler
Our touch handler is a simple adapter which expects screen-level touch events from the OS, and dispatches game-level events -- so when I click at a certain location on the screen, the object at that location receives a logical touch-down-event instead of just "The user clicked at: (x,y)".
We provide this layer of abstraction to save game developers the need to handle low level touch events and decide which object should respond. It is very important that our development platform be kept suitable for entry-level developers, and be easy to use with as little hassle as possible.
The case where game objects are stacked on one another and a touch event is received at a location that's within multiple objects can be difficult to handle at the game developer's level. That's why we decided that the touch event in this case is dispatched to the top-most object that's visible under the finger, and that's it.
The easiest way to do it is to scan all the objects in a front-to-back order and find the first that can handle the event.
The Render Queue
The MoMinis game-engine is powered by OpenGL ES on both Android and iPhone. For portability reasons, we limit ourselves to the OpenGL ES 1.1 API.
To maximize fill rate, we separate objects into two groups: opaque and translucent. The opaque group gets drawn first, front-to-back -- so fragments that are eventually invisible will be culled by the Z-buffer instead of being drawn-upon later, saving the entire rasterization pipeline.
For correct alpha-blending, the translucent group must be rendered back-to-front, after the opaque group has been rendered.
Challenges to Platform Developers
The demands from our cross-platform development environment and the games it produces are challenging:
Inexperienced, non-programmer developers should be able to create nice games easily
Games should have good performance
Games should be pretty
Final game size should be small
Games should be portable
Developer should be bothered with porting issues as little as possible (preferably none at all)
These demands conflict most of the time, and make our game-engine development a challenge.
When you're a content developer making a fully-fledged game, the game's logic can get quite complex pretty quickly. You have all these power ups and bonuses and special animations and sounds that change your basic game mechanics temporarily, and in some games you have to dynamically generate the level as the user advances (as in Jelly Jump).
Our platform developers aren't always seasoned programmers, or simply don't know the ins-and-outs of the game engine's implementation, so game logic is at times written in a suboptimal fashion. In addition, as the platform is still evolving, common practices used by content developers may worsen the situation, usually with no real alternative due to lack of features in the platform.
This means that sometimes a content developer will create and destroy many auxiliary objects in a short time during gameplay, making instance management a challenge.
An Always-Sorted Collection Problem
As the engine was originally written for J2ME, it allowed use of only the facilities offered by CLDC under a limited number of classes and code size, and some implementations are very far from optimal. For instance, the code relied on java.util.Vector -- a class that has all its methods synchronized.
The entity that manages the game held all existing object instances in an array sorted by Z-order. Every time an object was being created, destroyed, or its Z-order changed -- we would remove it from the array (moving all the elements after it one index back) and re-insert it at the correct location after a binary search (moving all elements after it one place forward).
Since scanning the array for the object is an O(n) operation, removing and inserting an element is again an O(n) operation, and finding the correct spot is a O(log n) operation -- all the basic actions on an object had runtime proportional to the number of objects existing at the moment.
Needless to say, as games got more complex and required more objects, this became a problem. Jelly Jump was creating 40-60 objects every few seconds, in a world containing 500-700 objects. On top of that, when an object is created, its Z-order is set to the maximal Z-order allowed -- but then immediately set to its layer's Z-order by the object's constructor, doubling the amount of Z-order operation the engine had to perform. This would explain the jitter -- creating objects caused a very long logical iteration, dipping FPS temporarily.
Initial Optimization Experiments
We needed to fix it, and we needed to fix it fast. This was the main problem blocking the release.
At first we took a conservative approach, trying to make as few changes as possible so close to a release. We concluded that there was no reason for the collection to be kept in order at all times -- just before rendering and touch-handling. Our first attempt was to defer sorting to these two occasions.
This should have addressed the object creation problem, reducing it from O(n) to O(1), as we intended to simply append the new object to the end of the list, and query it for its Z-order just before sorting. This would also cut down by half Z-order changes, as we were no longer adding new object to the collection, then moving it like we used to.
We took the standard approach, and tried good-ol' quicksort for the just-in-time array sorting. Unfortunately, the game engine's contract with the developer is such that objects at the same Z-order are sub-ordered by the order their Z-value changed -- meaning our sorting algorithm had to be stable, which quicksort isn't. (It took us a good while to figure that this was what's causing the weird phenomenon we were seeing with the game's graphics).
Somewhat humbled by our reckless arrogance in thinking this was such an easy problem to fix, we looked for a good sorting algorithm that is both stable and efficient. Tree sort was the next thing we tried. Though the sort was now stable, it was also very slow. We failed at identifying that we were using tree sort on a mostly-sorted collection, which is tree sort's Achilles Heel -- in that case you end up with a degenerate tree and efficiency is no more.
Reading a little bit on the web we encountered all sorts of sorting algorithms and variations on existing algorithms that might or might not work, but we didn't have the time to start learning and understanding each one and decide whether it was appropriate for our needs.
So we went back to quicksort. This time we applied a bias to the Z-order, giving a monotonic index for each object that got its Z-order changed. This wasn't perfect, but it was reasonable for the time we had.
Eventually, this optimization didn't make it to the release -- we didn't have the time to properly test the change and we were able to work around the problem enough to make the game releasable by avoiding creation of multiple objects in a single logical iteration, thus not triggering the Z-order overhead. Instead of creating a full screen of jellies at once, we instructed the content developers to create a screen line-by-line.
An O(1) Always-sorted Collection
Although we released Jelly Jump without fixing the problem, we had to fix it for the next game.
Back when I was running Red Hat Linux 8 with kernel 2.4.18 (or something), I remember reading that the under-development Linux 2.6 had an all-new O(1) scheduler. The news about this scheduler was that it could schedule many tasks in constant-time complexity, no matter how loaded the system was. This scheduler held up till 2.6.23, when it was replaced by the O(log n) Completely Fair Scheduler.
What made this an O(1) scheduler was that the author, Ingo Molnar, choose not to store priority information in the tasks themselves and sort them in a collection according to their priority, but to store the task's priority information in the collection itself -- he created a different queue for each priority level, giving him direct access to the head of each queue.
Because the number of priority levels was predetermined, scanning all priority queues for insertion and dequeuing is done in constant time.
Since tasks behave almost erratically, much like objects in our games, but still must be kept in order for scheduling, we tried a new approach, based on the Linux solution.
Let's review the requirements from our collection:
Collection should be traversable by order in both directions in no more than O(n)
Objects with the same Z-order should be ordered by sub-order of last-Z-action-on-top
Insertion, removal and changing of Z-order should be O(1)
Memory complexity should be kept low
All Z-order values are legal (including negative and non-integer values) -- for backward-compatibility reasons
Simplification
We'll start with a simpler case, and ignore the last requirement. We'll define an object's Z-order to be a natural, bounded number (say, between 0 and 100), where lower Z-order means an object is further back.
The idea is to have a "bucket" for every legal Z-order in an array, holding all objects that have that Z-order by order of insertion. We'll implement a "bucket" with a double-ended linked-list, which allows us an O(1) insertion of a new object to its tail, and traversal in-order in both directions:
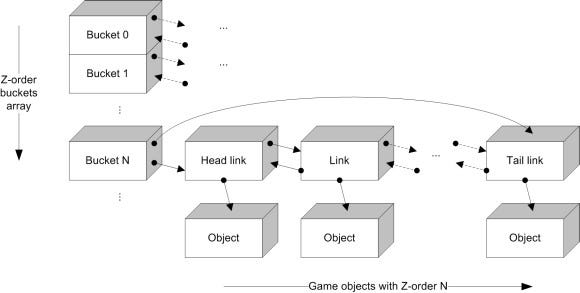
Simple data-structure
Adding a new object to a Z-order bucket involves looking up the Z-order in the buckets array, and appending the object to the list's tail:
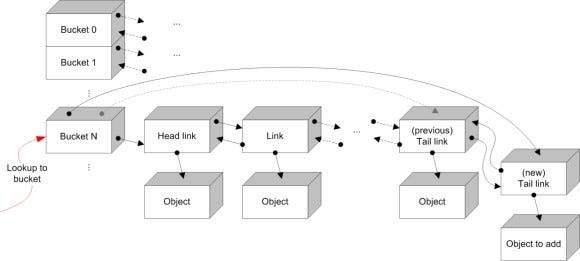
Addition of an object to a bucket
By appending the object to the tail of the list, we maintain sub-ordering by last-Z-order action (we chose back-to-front forward traversal direction)
Traversing the entire structure is trivial -- all we have to do is scan the objects in the first (or last) bucket, and move to the next (previous) bucket until there are no more buckets left.
However, we still have to address the removal of objects from a bucket (either when it is being destroyed, or moved to another bucket as its Z-order changes). To avoid having to scan the entire collection to find the location of the object's link in the bucket's list, we'll use an auxiliary field in the object itself - we're going to cache the current linked-list link holding the object in the bucket inside the sprite, allowing us O(1) access to it.
We're creating a back-reference from an object to its location in the bucket it is currently in:
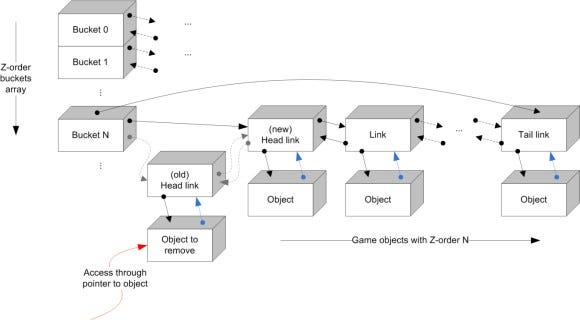
Removal of an object from a bucket (blue arrow donates back-reference from object to linked-list link)
From here things look trivial. Since selecting a bucket is matter of array lookup by index, adding to the end of a linked list is O(1) and removing a link from a linked-list is also O(1) (given the link object itself), we can achieve an always-sorted collection with O(1) runtime for all the actions we need.
Let's examine how it's implemented. First, a game object will have to be able to report its Z-order, and hold the auxiliary link:

For the sake of abstraction, we're not holding the actual linked-list link class in the object, but hold it through an interface that allows us to remove the link from the list:

Next step is to implement the list that will hold a bucket's contents. Remember that it has to expose the link that holds an object for caching, so we can't use any Java built-in collection:

Now all we have to do is to create a bucket for each legal Z-order:

And by that we've written our basic data structure. Let's examine each action separately, and see how we make it an O(1) operation.
Object Creation
To add a new object to the collection, all we have to do is to append it to the end of the bucket of its current Z-order, and cache the link in the object. That will also ensure sub-order of same-Z objects:
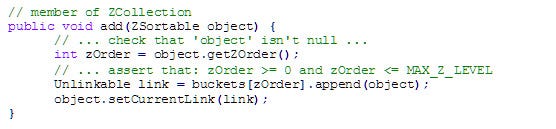
Since this is a double-ended linked-list, appending to its tail is an O(1) action.
Destroying an Object
To remove an object from the Z-collection, all we have to do is unlink it from the bucket's list:
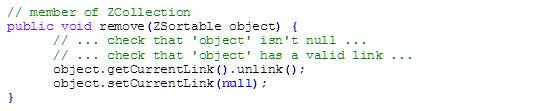
Since unlinking a link from a double-linked-list is an O(1) operation, and we have a direct access to the link, this is also the runtime complexity for removing an object from the collection.
Changing Z-order
Changing the Z-order of an object is as simple as removing it from the previous bucket, and adding it to the new one, just like before:
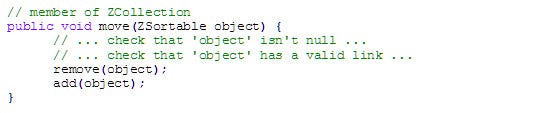
Note that we're not skipping the operation even if the object is moved to the same Z as its current Z - this is on purpose as we have to pop the object up to be above all the rest according to the engine's contract with the developer. Since we're only using O(1) operations, this is also an O(1) operation.
Traversing in Order
Traversing in order (either back-to-front or front-to-back) is trivial -- we traverse all the buckets in the desired order, and for each bucket we traverse its list in the desired order (for back-to-front we'll iterate normally, and for front-to-back we'll iterate in reverse on both buckets and bucket-lists).
Since advancing in a linked-list is an O(1) operation, traversing the entire collection is O(n).
Note: I've included only interface listings for things that are trivial to implement. For a full code listing, check out https://github.com/mominis/zorder and the SimpleZCollection class.
The Real World
Though the previous solution will work well in new designs, we couldn't use it as it was in our engine -- the reason being, as always, backward compatibility. We have to address the last bullets we neglected in the previous section.
For historic reasons, such as J2ME, the engine still works in fixed-point arithmetic -- and supports "non-integer" and negative Z-orders. In addition, the range of possible Z-orders spans the entire integer space - way too many for a single array. Moreover, every object created gets the default maximal Z-order possible (231-1).
Unfortunately, we couldn't come up with a solution to this problem in O(1) runtime complexity and reasonable memory complexity, and had to settle for best-effort approach.
We allow negative an non-integer Z-levels, as well as very high or low values - but these aren't as optimal as natural bounded Z-orders. We also provide a special-case optimization for the default Z-order.
First thing we did was to replace the buckets array with another linked-list. This will allow us to open new buckets for non-integer Z-levels in between "optimized" buckets, or add new large/small buckets on-demand.
We also allocate at the end of the list the last Z-order, for the maximal default entry. Every item in the buckets list holds a list of sortables, and the Z-order it represents.
Initially, the buckets list is initialized with a bucket for each optimized natural Z-order, plus the maximal level. Then, the links of the buckets list holding the buckets themselves are put in an array (the "quick-access" array). As before, we cache the internal structure the linked-list uses:
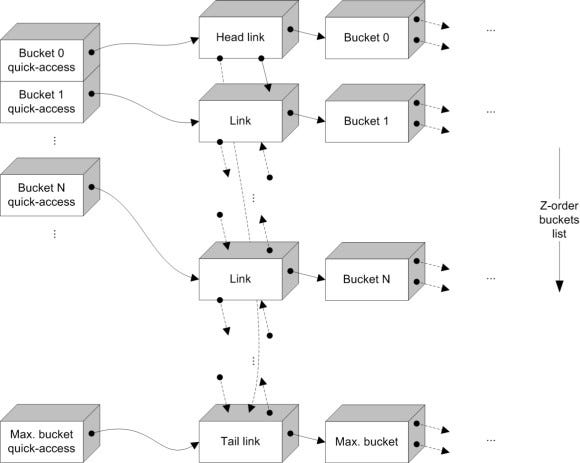
Buckets in linked-list with quick-access array
This ensures we can always access optimized Z-orders buckets quickly, even when new Z-order buckets are inserted in-between.
When we need to add a new object, we first check if its Z-order is the default order. If so, it is appended to that bucket, which we hold direct reference to. Otherwise, we'll test whether it's an optimized Z-order. If it is, we can simply append it to the proper bucket after looking it up in the quick-access array.
If this is an un-optimized Z-order, we'll fall back to an O(n) search method that will look for an existing bucket with the new Z-order. We simply traverse all the buckets in order, starting from the nearest optimized one, and try to find a bucket with that Z-order. If we can't find one, we'll insert a new bucket between links in the appropriate location in the buckets list:
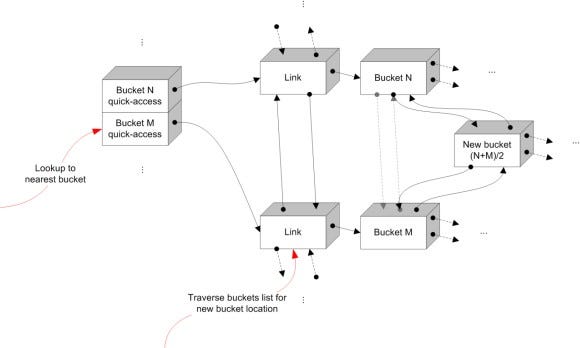
Opening a new bucket between existing buckets
Support for negative Z-order is similar, except we cannot use the quick-access array, and traversal is done from zero downwards.
One little issue we still need to resolve is discarding empty non-optimized buckets. This can be done while traversing the collection. For instance, a counter could be kept for each non-optimized bucket holding how many times the bucket was empty when traversed. If during traversal the counter is over a threshold, the bucket can be removed.
This allows us to support old games, but give new games that follow the guidelines better performance.
You can find the complete implementation of this collection at https://github.com/mominis/zorder in the FixedPointZCollection class.
Conclusion
First, there's a common conception among game developers that performance bottlenecks are the result of the render process, neglecting the CPU aspect of executing the game's logic. When we first started working the Jelly Jump problem, we were given speculations from the content developers' experiments, and tried finding the problem with the rendering process before we even proved the problem was there.
It took us several hours of finding nothing to stop for a second, ignore the initial testing results we got and start working methodically, finding quickly that graphics had nothing to do with the problem. As developers working a bug, we need focus the bug reporter on what happens, not why it happens. Finding the "why?" is our job.
As a young self-taught programmer, I had a period where I didn't believe in Computer Sciences studies, thinking that in today's world every language already has all the basic data structures and algorithms implemented for you, and there's little need for this kind of knowledge "in the real world". I know some experienced programmers that still think so. But after having my share of problems to solve over the years, I see it more as a 20-80 rule. Looking at our initial optimization attempts, we were able to improve performance by using what Java had to offer. The simple solution took us 80 percent of the way -- which in most cases is good enough.
But as game engine developers, we can't be "good enough" programmers; we need to be the best programmers. We develop applications that should run as smoothly as possible on a wide variety of devices, squeezing our every last bit of available CPU, GPU and memory resources (except when we've got battery issues on mobile devices, but that's beside the point). For most applications, 80 percent is enough, but as game engine developers we must be able to do better -- and for that we must have that extra edge over "non-believers".
In this case, the extra 20 percent made us adopt a different approach altogether, and employ methods from OS-kernel scheduler technology to achieve a better solution. In the end, we're sorting a collection without using any sorting algorithm! Employing "traditional" methods would never have gotten use there. Never underestimate knowledge you acquire, no matter how unrelated to your field it may seem -- that's what makes brilliant moments.
You May Also Like







