Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
What happens when you use genetic programming to evolve the AI for a soccer game? In this in-depth Gamasutra technical article, de Alencar Jr. and Dias try finding a "winning strategy" by letting their virtual soccer players work it out themselves.
September 25, 2007
10 Min Read

Author: by Diego Silva Dias
The most common Artificial Intelligence approaches are used to optimize a strategy that has been previously hand-coded. These strategies are, usually, already known to be optimal.
Sometimes, there is not a known optimal strategy that can be used to solve a given problem. In these cases, instead of trying to optimize a fixed strategy that we don’t even know whether it will bring good results or not, would be desirable if we could search for it using the computer and that is exactly the aim of genetic programming, which is an evolutionary technique based on Darwinian concepts of natural selection.
We have decided to use a genetic programming approach to develop the artificial intelligence of a 2D soccer team because, as we know, a “winning strategy” for these games hasn’t been found yet. In our genetic programming approach we’ve generated a “population” of teams. Our goal was to develop a decision tree to each one of the team’s players.
Decision Tree
“if-else” Structure – Binary Tree
In our implementation each terminal node is an action the player can take (e.g. kick the ball). Non-terminal nodes are the ones that represent the situations of the game (e.g. player has the ball).
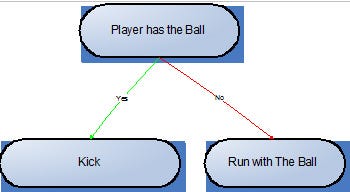
Figure1: Sample of a decision tree with if-else structure randomly created
In the example above, the left leaf is a terminal node and represents an action the player takes only when his parent node, the non-terminal “Player has the Ball” is true. The other branch represents an action taken by the player when he does not have the ball. As we can see, these decision trees can be directly mapped to an “if-else” code.
Compatibility List
Even with this simple approach, there were incompatible elements, so a verification of compatibility between the nodes was necessary. If a player doesn’t have the Ball, for example, it doesn’t make any sense to give him an order to kick or run with it.
To check whether a node could be inserted or not to a branch of a tree, a list of compatibilities was added to each node. In this list, every possible children of the given node is present, in such a way that only the nodes in this list can be added as a child. This approach, however, is not enough to solve the problem, because undesirable combinations, like the one shown in Figure 2, would still happen. In this Figure, if the player has the ball and is near his own goal an order to Mark will be given, but that is not desirable since he will leave the ball behind.
A possible solution can be: when adding a new node, would be done a search in the tree to check if the new node would be compatible with his “ancestors”. However, this solution would be much expensive in the computational point of view, besides in this program a lot of trees would be generated, so this solution was discarded. The adopted solution was to modify the list of compatibilities of each node in the moment it is inserted in a branch. At this moment, the node inherits the list of compatibilities of its father and makes an intersection with its own list of compatibilities (the original), producing a new list.
The nodes that represent the “false” statement don’t need to have any relation of coherence with their parents. For that reason the generation of these nodes and its compatibility list is made using their grandfather’s.
This solution produced teams a lot more coherent. Besides it limited the size of the trees, preventing them to grow infinitely, and reduced their size which accelerated the evolution process.
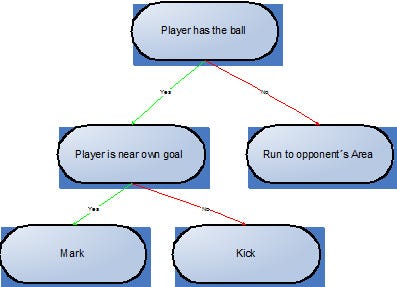
Figure 2: Example of a situation where a simple list of compatibilities wouldn’t work
Initial Nodes
We have decided to build the trees always with the same initial nodes. This approach was possible because there were four nodes which represented all the possible situations in the game, they were: “Player with the ball”, “Team with the ball”, “Opponent team with the ball”, “Nobody with the ball”.
For these initial nodes, there weren’t any children in the false condition, because if we do so, we would be in the problem of more than one different action to the same game state.
This made the trees become much more coherent, accelerating the evolutionary process. Also, it forced the players to do something in every state of the game.
Selection Approach
The first problem faced was the definition of a proper fitness function. The first solution was to use base teams as a benchmark to play with the ones randomly created and then evaluate the final score of each game. Based on that, the best teams would be chosen and then evolved. Knowing that the generation of good teams in the initial stages of evolution is highly improbable, it would be extremely difficult to evaluate, among lots of losses, which ones are the best teams.
Because of that reason, a co-evolution technique was used. In this approach, a championship was made (where teams from the same generation played against each other). The “winners”, then are chosen and evolved.
To perform the evolution itself, new teams were created based on the biology concepts of crossing over, mutation and reproduction.
Mutation
Mutation consists in randomly making changes in a player’s sub-tree, generating a new team with a different behavior.
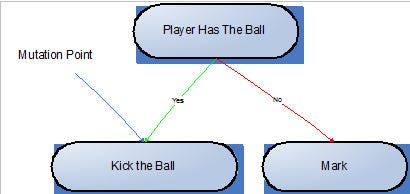
Figura3a: Sample of a sub-tree of a player before the mutation takes place
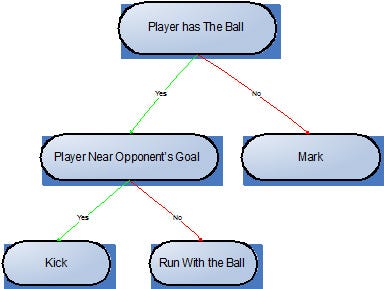
Figura3b: Player’s sub-tree after the mutation
As we can see in the example above, after the mutation, a different decision tree has been generated, resulting in a new behavior for the “mutant player”.
Crossing-Over
Crossing-Over consists in exchanging behaviors amongst players of the same team, aiming in propagating and recombining well-formed strategies.
To perform this operation, a given player’s sub-tree is exchanged with another branch from a different player, resulting in the creation of different teams. To successfully perform crossing-over, the root node of both of the sub-trees selected should be compatible with their new parent node.
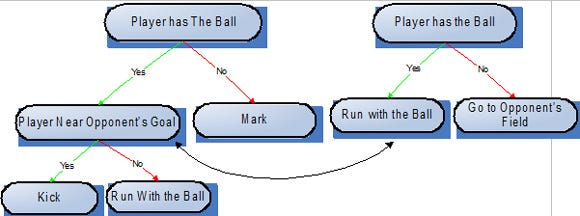
Figure4a: Sub-trees of two different players before crossing-over took place. 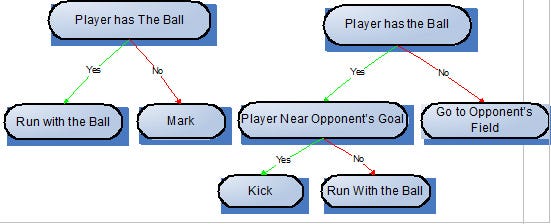 Figure4b: Resulting sub-trees after crossing-over operation was performed.
Figure4b: Resulting sub-trees after crossing-over operation was performed.
Crossing-over is not very important in the initial generations, as there isn’t basically, any well-developed behavior yet, but, as the evolution progresses, it becomes really important, as it allows sharing well-defined strategies amongst players.
Reproduction
The reproduction is a concept very similar to the Crossing-Over and has the same purpose of it. To perform reproduction, two different teams should be chosen randomly. After that, two distinct situations can happen: the exchange of players amongst them or the exchange of sub-trees between players from these different teams.
Evolution
In each step of the evolutionary process only half of the teams survived. The other half that we needed to “complete” the generation was created with the operations of mutation, reproduction and crossing-over.
Amongst all of the teams generated by these operations, half were generated by mutation, a quarter by reproduction and the other quarter by crossing-over.
Training Methodology
In order to minimize the duration of the training, a maximum number of games to each team was established before the evolution took place. The teams were divided in groups and played amongst them. The best from each group were the “chosen ones”. This approach of dividing in groups was implemented to accelerate the evolutionary process.
To automate the system of evolution, all the teams were stored in a database with their history of games. In the end of each “tournament”, a script responsible for selecting the best teams was executed so the creation of the next generation could take place.
Tests And Results
Since the technique shown is somehow independent of language, we had to make the decision trees of the players become a compilable code in the language of the soccer game simulator. To achieve it, we developed a “translator” that wrote the content of the tree and its node in a compilable file. Since this article is to show/teach how genetic programming can be implemented we won’t get in details about the translator.
A small number of generations were enough for us to observe some interesting behaviors. In the second generation almost all the teams had some kind of a goalkeeper (what not necessarily would have happened, but it is right to think that it is an important characteristic of a good team), besides most of the best teams had a player that acted in the attack running with the ball.
In the figure below, we could see a game between a team from generation 0, which basically had a behavior where all the players went marking, which is known as “Kid Soccer” (this team was eliminated during the evolution), against a team from generation 2, which had a goalkeeper and a player near the opponent’s goal.
Because of the compatibility list implemented, the initial nodes chosen and the soccer simulator utilized, which was a simple soccer 2D with 5 players, we didn’t need to evolve the population of teams very far to achieve good results. Only 3 generations were enough for our teams to beat the simulator pre-built soccer teams.
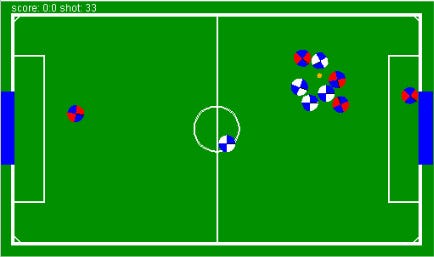
Figure 5: Match between a team from generation 0 against a team from generation 2.
Conclusion
In this implementation, Genetic Programming achieved its purpose. The “World” created started with many “incoherent” teams and as the evolution took place the teams were becoming better, because the players were acquiring different and interesting soccer behaviors.
Genetic Programming is a very suitable technique for soccer games, since in these games an optimal strategy has not yet been proved to be known. So, we can use a genetic programming approach to develop strategies for the teams.
As a result of the training, there will be a huge number of teams which can provide a great diversity to the game, also each generation can represent a level of difficulty and it would go as far as desired, since each new generation of teams is better than the previous one (the average of teams), generating a wide range of difficulty levels.
Also, if the nodes are properly developed, all the teams generated will have “human” behaviors, since the strategy is randomly developed by the computer.
Although this technique is suitable for soccer games, the quality of the teams would be greatly dependent of the quality of the terminal nodes and the range of the non-terminals.
If the non-terminal nodes don’t have enough range, the teams won’t be prepared for all the possible situations of the game, also if the terminal nodes are not well developed, the actions that the players have won’t be good. The quantity of nodes is also very important, since the speed of the evolution is directly linked with the number of nodes.
Read more about:
FeaturesYou May Also Like







