Daily news, dev blogs, and stories from Game Developer straight to your inbox
Sponsored By
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs.
Machine learning enables personalized experiences in games, and Zynga is leveraging feature generation tools to streamline this development.
7 Min Read

“One of the holy grails of machine learning is to automate more and more of the feature engineering process” - Pedro Domingos, CACM 2012
One of the biggest challenges in machine learning workflows is identifying which inputs in your data will provide the best signals for training predictive models. For image data and other unstructured formats, deep learning models are showing large improvements over prior approaches, but for data already in structured formats, the benefits are less obvious.
At Zynga, I’ve been exploring feature generation methods for shallow learning problems, where our data is already in a structured format, and the challenge is to translate thousands of records per user into single records that summarize user activity. Once you have the ability to translate raw tracking events into user summaries, you can apply a variety of supervised and unsupervised learning methods to your application.
 https://github.com/FeatureLabs/featuretools
https://github.com/FeatureLabs/featuretools
I’ve been leveraging the Featuretools library to significantly reduce my time spent building predictive models, and it’s unlocked a new class of problems that data scientists can address. Instead of building predictive models for single games and specific responses, we’re now building machine learning pipelines that can be applied to a broad set of problems. I presented an overview of our approach at the AI Expo in Santa Clara, and the slides from the talk are available here.
Machine Learning Use Cases
Automated feature engineering is the process of creating feature vectors from thousands or even millions of data points for each user. It is inspired by the feature synthesis methods from deep learning, but focuses on only the feature generation stage and not the model fitting stage. The result of deep feature synthesis is that your can translate thousands of records describing user activity into a single record that can be used for training models. Here are some of the use cases we’ve explored for automated feature engineering:
Propensity Models: What actions are users performing?
Recommendations: What actions should we prescribe?
Segmentation: How should we personalize user experiences?
Anomaly Detection: Which users are bad actors?
I provided a deep dive of feature engineering during my AutoModel talk at the Spark Summit earlier this year. Since then, we’ve found a variety of different use cases for automated feature engineering. The key takeaway is that if you can translate raw event data into summaries of user behavior, then you can apply machine learning models to a variety of problems.
Propensity Models
Predicting which users are likely to perform an action is useful for personalizing gameplay experiences. For the AutoModel project, we used the Featuretools library to automate feature engineering for building propensity models across all of our games.
 Propensity models
Propensity models
Recommendations
Collaborative filtering is a valuable tool for providing personalized content for users. Instead of using past purchases as a feature vector for collaborative filtering, I’ve been exploring a number of proxy variables to suggest items.
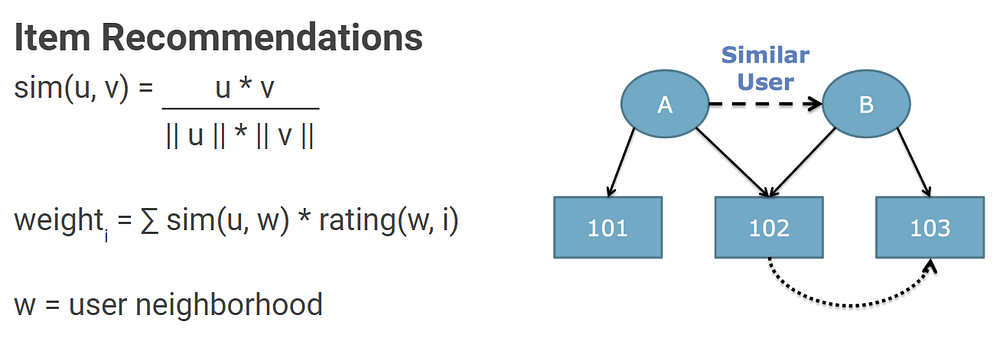 Recommendation engine for personalized content.
Recommendation engine for personalized content.
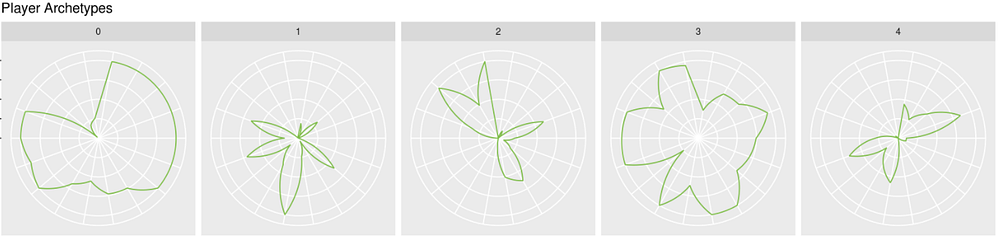
Archetypes
Segmentation is one of the key outputs that an analytics team can provide to a product organization. If you can understand the behaviors of different groups of users within your product, you can provide personalized treatments to improve the engagement of your user base.
Anomaly Detection
There’s bad actors in any online environment. We’ve been exploring deep learning for this problem, and applying autoencoding on our generated feature sets has provided a powerful tool for flagging problematic users.
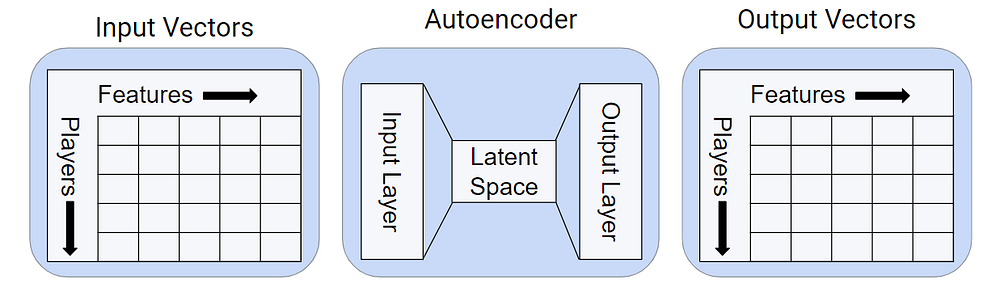 Anomaly detection with deep learning.
Anomaly detection with deep learning.
Feature Generation
Feature engineering is one of the primary steps in machine learning workflows, where raw event data is transformed into player-level summaries that can be used as input to supervised and unsupervised learning algorithms. We’ll provide an example of how we perform this step using sample data from the NHL Kaggle data set, which provides detailed gameplay events from the past two decades of professional hockey matches.
We use Python for most of our exploratory analysis and PySpark for scaling up our machine learning pipelines. The first task in a ML pipeline is fetching data from a data store. We typically fetch data from a data lake on S3, but for this example we’ll use local files downloaded from the Kaggle data set. The Python snippet below shows how to load these files as Pandas data frames, and drop extraneous columns from the plays data frame.
# load CSV files into Pandas data frames import pandas as pd game_df = pd.read_csv("game.csv") plays_df = pd.read_csv("game_plays.csv") # clean up the data frame and show the results plays_df = plays_df.drop(['secondaryType', 'periodType', 'dateTime', 'rink_side'], axis=1).fillna(0) plays_df.head()
The game_df data frame provides game-level summaries of hockey matches, while the plays_df data frame contains details gameplay events such as faceoffs and shots taken within a game. The last command in the snippet above displays the first five play records, shown below.
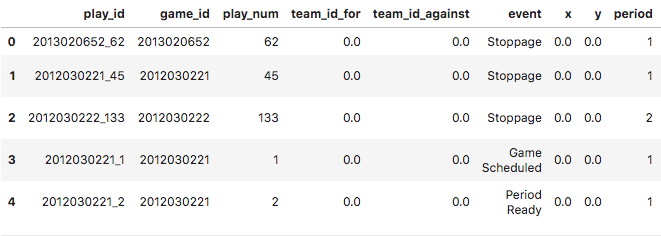 Gameplay events within the NHL data set.
Gameplay events within the NHL data set.
Our goal is to transform the detailed gameplay events from a narrow and deep format into a shallow and wide format, where a single row contains hundreds of columns and summaries a single game. To perform this process, we use a two-step transformation where we first one-hot encode a set of columns, and then run deep-feature synthesis on the resulting data frames.
For the NHL data set, we want to one-hot encode the event and description columns. Featuretools provides a function called encode_features to transform columns with many possible values into dummy columns with binary values. Before we can use this function, we need to encode the plays data frame as an entity set, which provides metadata about the data frames to the Featuretools library. The Python snippet below shows how to create an entity set for the plays data frame, specify which columns are categorical, and one-hot encode the event and description columns. The result is a wider data frame with dummy variables for these columns.
# load the featuretools library import featuretools as ft from featuretools import Feature # create an entity set and list the categorical variables es = ft.EntitySet(id="plays") es = es.entity_from_dataframe(entity_id="plays", dataframe=plays_df ,index="play_id", variable_types = { "event": ft.variable_types.Categorical, "description": ft.variable_types.Categorical }) # one-hot encode the features and show the results f1 = Feature(es["plays"]["event"]) f2 = Feature(es["plays"]["description"]) encoded, defs = ft.encode_features(plays_df, [f1, f2], top_n=10) encoded.head()
The output from this snippet is shown in the table below. The data frame has the same number of records as before, but the frame now has 36 rather than 18 columns.
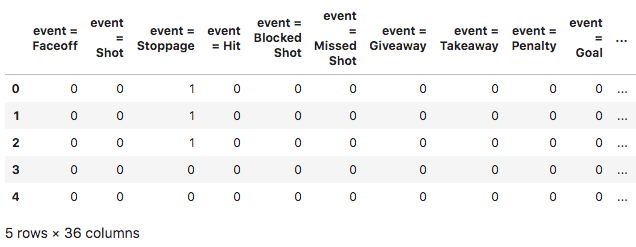 Gameplay events with dummy variables.
Gameplay events with dummy variables.
Now we can perform deep-feature synthesis using the dfs function in Featuretools. Again, we need to translate our data frame into an entity set, but we’ll add an extra step. The code snippet below shows how to convert the data frame with the dummy variables into an entity set, and then normalize the entity set. The normalize_entity function specifies that plays should be grouped into sets using the game_id column. After running dfs on the resulting entity set, the result is a data frame with a single record per game and hundreds of columns describing the actions in the match.
# create an entity set from the one-hot encoding es = ft.EntitySet(id="plays") es = es.entity_from_dataframe(entity_id="plays", dataframe=encoded, index="play_id") # group play events into sets of games es = es.normalize_entity(base_entity_id="plays", new_entity_id="games", index="game_id") # perform feature synthesis and show the results features,transform=ft.dfs(entityset=es, target_entity="games",max_depth=2) features.head(2)
The resulting data frame with our generated features is shown in the table below. The plays data frame has now been translated from 36 columns to a game summary data frame with over 200 columns.
 Game summary data frame with generated features.
Game summary data frame with generated features.
Instead of manually specifying how to aggregate our raw tracking events into player summaries, we are now leveraging tools that enable us to automate much of this process. We walked through an example with NHL gameplay data, but the same process can be applied to tracking events for mobile games. The full code for the NHL example if available on GitHub.
Conclusion
Automating the feature generation step in machine learning workflows unlocks new problems for data science teams to tackle. Instead of focusing on specific games, our data scientists can now build solutions that scale to a portfolio of titles. This post focused on the feature engineering process, while my last post discussed how we scale up this approach to work with tens of millions of active users. If you’re interested in machine learning at Zynga, we are hiring for data science and engineering roles.
Read more about:
Featured BlogsAbout the Author(s)
You May Also Like







